Revision Selection
Git allows you to specify specific commits or a range of commits in several ways. They aren’t necessarily obvious but are helpful to know.
Single Revisions
You can obviously refer to a commit by the SHA-1 hash that it’s given, but there are more human-friendly ways to refer to commits as well. This section outlines the various ways you can refer to a single commit.
Short SHA
Git is smart enough to figure out what commit you meant to type if you provide the first few characters, as long as your partial SHA-1 is at least four characters long and unambiguous — that is, only one object in the current repository begins with that partial SHA-1.
For example, to see a specific commit, suppose you run a git log command and identify the commit where you added certain functionality:
$ git log
commit 734713bc047d87bf7eac9674765ae793478c50d3
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 14:58:32 2008 -0800
added some blame and merge stuff
In this case, choose 1c002dd.... If you git show that commit, the following commands are equivalent (assuming the shorter versions are unambiguous):
$ git show 1c002dd4b536e7479fe34593e72e6c6c1819e53b
$ git show 1c002dd4b536e7479f
$ git show 1c002d
Git can figure out a short, unique abbreviation for your SHA-1 values. If you pass --abbrev-commit to the git log command, the output will use shorter values but keep them unique; it defaults to using seven characters but makes them longer if necessary to keep the SHA-1 unambiguous:
$ git log --abbrev-commit --pretty=oneline
ca82a6d changed the version number
085bb3b removed unnecessary test code
a11bef0 first commit
Generally, eight to ten characters are more than enough to be unique within a project. One of the largest Git projects, the Linux kernel, is beginning to need 12 characters out of the possible 40 to stay unique.
A SHORT NOTE ABOUT SHA-1
A lot of people become concerned at some point that they will, by random happenstance, have two objects in their repository that hash to the same SHA-1 value. What then?
If you do happen to commit an object that hashes to the same SHA-1 value as a previous object in your repository, Git will see the previous object already in your Git database and assume it was already written. If you try to check out that object again at some point, you’ll always get the data of the first object.
However, you should be aware of how ridiculously unlikely this scenario is. The SHA-1 digest is 20 bytes or 160 bits. The number of randomly hashed objects needed to ensure a 50% probability of a single collision is about 2^80 (the formula for determining collision probability is p = (n(n-1)/2) * (1/2^160)). 2^80 is 1.2 x 10^24 or 1 million billion billion. That’s 1,200 times the number of grains of sand on the earth.
Here’s an example to give you an idea of what it would take to get a SHA-1 collision. If all 6.5 billion humans on Earth were programming, and every second, each one was producing code that was the equivalent of the entire Linux kernel history (1 million Git objects) and pushing it into one enormous Git repository, it would take 5 years until that repository contained enough objects to have a 50% probability of a single SHA-1 object collision. A higher probability exists that every member of your programming team will be attacked and killed by wolves in unrelated incidents on the same night.
Branch References
The most straightforward way to specify a commit requires that it have a branch reference pointed at it. Then, you can use a branch name in any Git command that expects a commit object or SHA-1 value. For instance, if you want to show the last commit object on a branch, the following commands are equivalent, assuming that the topic1 branch points to ca82a6d:
$ git show ca82a6dff817ec66f44342007202690a93763949
$ git show topic1
If you want to see which specific SHA a branch points to, or if you want to see what any of these examples boils down to in terms of SHAs, you can use a Git plumbing tool called rev-parse. You can see Chapter 9 for more information about plumbing tools; basically, rev-parse exists for lower-level operations and isn’t designed to be used in day-to-day operations. However, it can be helpful sometimes when you need to see what’s really going on. Here you can run rev-parse on your branch.
$ git rev-parse topic1
ca82a6dff817ec66f44342007202690a93763949
RefLog Shortnames
One of the things Git does in the background while you’re working away is keep a reflog — a log of where your HEAD and branch references have been for the last few months.
You can see your reflog by using git reflog:
$ git reflog
734713b... HEAD@{0}: commit: fixed refs handling, added gc auto, updated
d921970... HEAD@{1}: merge phedders/rdocs: Merge made by recursive.
1c002dd... HEAD@{2}: commit: added some blame and merge stuff
1c36188... HEAD@{3}: rebase -i (squash): updating HEAD
95df984... HEAD@{4}: commit: # This is a combination of two commits.
1c36188... HEAD@{5}: rebase -i (squash): updating HEAD
7e05da5... HEAD@{6}: rebase -i (pick): updating HEAD
Every time your branch tip is updated for any reason, Git stores that information for you in this temporary history. And you can specify older commits with this data, as well. If you want to see the fifth prior value of the HEAD of your repository, you can use the @{n} reference that you see in the reflog output:
$ git show HEAD@{5}
You can also use this syntax to see where a branch was some specific amount of time ago. For instance, to see where your master branch was yesterday, you can type
$ git show master@{yesterday}
That shows you where the branch tip was yesterday. This technique only works for data that’s still in your reflog, so you can’t use it to look for commits older than a few months.
To see reflog information formatted like the git log output, you can run git log -g:
$ git log -g master
commit 734713bc047d87bf7eac9674765ae793478c50d3
Reflog: master@{0} (Scott Chacon <schacon@gmail.com>)
Reflog message: commit: fixed refs handling, added gc auto, updated
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Reflog: master@{1} (Scott Chacon <schacon@gmail.com>)
Reflog message: merge phedders/rdocs: Merge made by recursive.
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
It’s important to note that the reflog information is strictly local — it’s a log of what you’ve done in your repository. The references won’t be the same on someone else’s copy of the repository; and right after you initially clone a repository, you’ll have an empty reflog, as no activity has occurred yet in your repository. Running git show HEAD@{2.months.ago} will work only if you cloned the project at least two months ago — if you cloned it five minutes ago, you’ll get no results.
Ancestry References
The other main way to specify a commit is via its ancestry. If you place a ^ at the end of a reference, Git resolves it to mean the parent of that commit.
Suppose you look at the history of your project:
$ git log --pretty=format:'%h %s' --graph
* 734713b fixed refs handling, added gc auto, updated tests
* d921970 Merge commit 'phedders/rdocs'
|\
| * 35cfb2b Some rdoc changes
* | 1c002dd added some blame and merge stuff
|/
* 1c36188 ignore *.gem
* 9b29157 add open3_detach to gemspec file list
Then, you can see the previous commit by specifying HEAD^, which means "the parent of HEAD":
$ git show HEAD^
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
You can also specify a number after the ^ — for example, d921970^2 means "the second parent of d921970." This syntax is only useful for merge commits, which have more than one parent. The first parent is the branch you were on when you merged, and the second is the commit on the branch that you merged in:
$ git show d921970^
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 14:58:32 2008 -0800
added some blame and merge stuff
$ git show d921970^2
commit 35cfb2b795a55793d7cc56a6cc2060b4bb732548
Author: Paul Hedderly <paul+git@mjr.org>
Date: Wed Dec 10 22:22:03 2008 +0000
Some rdoc changes
The other main ancestry specification is the ~. This also refers to the first parent, so HEAD~ and HEAD^ are equivalent. The difference becomes apparent when you specify a number. HEAD~2 means "the first parent of the first parent," or "the grandparent" — it traverses the first parents the number of times you specify. For example, in the history listed earlier, HEAD~3 would be
$ git show HEAD~3
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <tom@mojombo.com>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gem
This can also be written HEAD^^^, which again is the first parent of the first parent of the first parent:
$ git show HEAD^^^
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <tom@mojombo.com>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gem
You can also combine these syntaxes — you can get the second parent of the previous reference (assuming it was a merge commit) by using HEAD~3^2, and so on.
Commit Ranges
Now that you can specify individual commits, let’s see how to specify ranges of commits. This is particularly useful for managing your branches — if you have a lot of branches, you can use range specifications to answer questions such as, "What work is on this branch that I haven’t yet merged into my main branch?"
Double Dot
The most common range specification is the double-dot syntax. This basically asks Git to resolve a range of commits that are reachable from one commit but aren’t reachable from another. For example, say you have a commit history that looks like Figure 6-1.
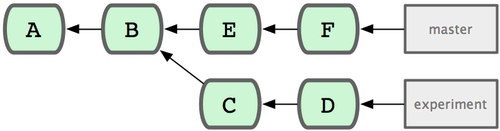
Figure 6-1. Example history for range selection.
You want to see what is in your experiment branch that hasn’t yet been merged into your master branch. You can ask Git to show you a log of just those commits with master..experiment — that means "all commits reachable by experiment that aren’t reachable by master." For the sake of brevity and clarity in these examples, I’ll use the letters of the commit objects from the diagram in place of the actual log output in the order that they would display:
$ git log master..experiment
D
C
If, on the other hand, you want to see the opposite — all commits in master that aren’t in experiment — you can reverse the branch names. experiment..master shows you everything in master not reachable from experiment:
$ git log experiment..master
F
E
This is useful if you want to keep the experiment branch up to date and preview what you’re about to merge in. Another very frequent use of this syntax is to see what you’re about to push to a remote:
$ git log origin/master..HEAD
This command shows you any commits in your current branch that aren’t in the master branch on your origin remote. If you run a git push and your current branch is tracking origin/master, the commits listed by git log origin/master..HEAD are the commits that will be transferred to the server.
You can also leave off one side of the syntax to have Git assume HEAD. For example, you can get the same results as in the previous example by typing git log origin/master.. — Git substitutes HEAD if one side is missing.
Multiple Points
The double-dot syntax is useful as a shorthand; but perhaps you want to specify more than two branches to indicate your revision, such as seeing what commits are in any of several branches that aren’t in the branch you’re currently on. Git allows you to do this by using either the ^ character or --not before any reference from which you don’t want to see reachable commits. Thus these three commands are equivalent:
$ git log refA..refB
$ git log ^refA refB
$ git log refB --not refA
This is nice because with this syntax you can specify more than two references in your query, which you cannot do with the double-dot syntax. For instance, if you want to see all commits that are reachable from refA or refB but not from refC, you can type one of these:
$ git log refA refB ^refC
$ git log refA refB --not refC
This makes for a very powerful revision query system that should help you figure out what is in your branches.
Triple Dot
The last major range-selection syntax is the triple-dot syntax, which specifies all the commits that are reachable by either of two references but not by both of them. Look back at the example commit history in Figure 6-1.
If you want to see what is in master or experiment but not any common references, you can run
$ git log master...experiment
F
E
D
C
Again, this gives you normal log output but shows you only the commit information for those four commits, appearing in the traditional commit date ordering.
A common switch to use with the log command in this case is --left-right, which shows you which side of the range each commit is in. This helps make the data more useful:
$ git log --left-right master...experiment
< F
< E
> D
> C
With these tools, you can much more easily let Git know what commit or commits you want to inspect.