Contribuyendo a un proyecto
En estos momentos conoces las diferentes formas de trabajar, y tienes ya un generoso conocimiento de los fundamentos de Git. En esta sección, aprenderás acerca de las formas más habituales de contribuir a un proyecto.
El mayor problema al intentar describir este proceso es el gran número de variaciones que se pueden presentar. Por la gran flexibilidad de Git, la gente lo suele utilizar de multiples maneras; siendo problemático intentar describir la forma en que deberías contribuir a un proyecto --cada proyecto tiene sus peculiaridades--. Algunas de las variables a considerar son: la cantidad de colaboradores activos, la forma de trabajo escogida, el nivel de acceso que tengas, y, posiblemente, el sistema de colaboración externa implantado.
La primera variable es el número de colaboradores activos. ¿Cuántos usuarios están enviando activamente código a este proyecto?, y ¿con qué frecuencia?. En muchas ocasiones, tendrás dos o tres desarrolladores, con tan solo unas pocas confirmaciones de cambios (commits) diarias; e incluso menos en algunos proyectos durmientes. En proyectos o empresas verdaderamente grandes puedes tener cientos de desarrolladores, con docenas o incluso cientos de parches llegando cada día. Esto es importante, ya que cuantos más desarrolladores haya, mayores serán los problemas para asegurarte de que tu código se integre limpiamente. Los cambios que envies pueden quedar obsoletos o severamente afectados por otros trabajos que han sido integrados previamente mientras tú estabas trabajando o mientras tus cambios aguardaban a ser aprobados para su integración. ¿Cómo puedes mantener consistentemente actualizado tu código, y asegurarte así de que tus parches son válidos?
La segunda variable es la forma de trabajo que se utilice para el proyecto. ¿Es centralizado, con iguales derechos de acceso en escritura para cada desarrollador?. ¿Tiene un gestor de integraciones que comprueba todos los parches?. ¿Se revisan y aprueban los parches entre los propios desarrolladores?. ¿Participas en ese proceso de aprobación?. ¿Existe un sistema de tenientes, a los que has de enviar tu trabajo en primer lugar?.
La tercera variable es el nivel de acceso que tengas. La forma de trabajar y de contribuir a un proyecto es totalmente diferente dependiendo de si tienes o no acceso de escritura al proyecto. Si no tienes acceso de escritura, ¿cuál es el sistema preferido del proyecto para aceptar contribuciones?. Es más, ¿tiene un sistema para ello?. ¿Con cuánto trabajo contribuyes?. ¿Con qué frecuencia?.
Todas estas preguntas afectan a la forma efectiva de contribuir a un proyecto, y a la forma de trabajo que prefieras o esté disponible para tí. Vamos a cubrir ciertos aspectos de todo esto, en una serie de casos de uso; desde los más sencillos hasta los más complejos. A partir de dichos ejemplos, tendrías que ser capaz de construir la forma de trabajo específica que necesites para cada caso.
Reglas para las confirmaciones de cambios (commits)
Antes de comenzar a revisar casos de uso específicos, vamos a dar una pincelada sobre los mensajes en las confirmaciones de cambios (commits). Disponer unas reglas claras para crear confirmaciones de cambios, y seguirlas fielmente, facilta enormemente tanto el trabajo con Git y como la colaboración con otras personas. El propio proyecto Git suministra un documento con un gran número de buenas sugerencias sobre la creación de confirmaciones de cambio destinadas a enviar parches --puedes leerlo en el código fuente de Git, en el archivo 'Documentation/SubmittingPatches'--.
En primer lugar, no querrás enviar ningún error de espaciado. Git nos permite buscarlos facilmente. Previamente a realizar una confirmación de cambios, lanzar el comando 'git diff --check' para identificar posibles errores de espaciado. Aquí van algunos ejemplos, en los que hemos sustituido las marcas rojas por 'X's:
$ git diff --check
lib/simplegit.rb:5: trailing whitespace.
+ @git_dir = File.expand_path(git_dir)XX
lib/simplegit.rb:7: trailing whitespace.
+ XXXXXXXXXXX
lib/simplegit.rb:26: trailing whitespace.
+ def command(git_cmd)XXXX
Lanzando este comando antes de confirmar cambios, puedes estar seguro de si vas o no a incluir problemas de espaciado que puedan molestar a otros desarrolladores.
En segundo lugar, intentar hacer de cada confirmación (commit) un grupo lógico e independiente de cambios. Siempre que te sea posible, intenta hacer digeribles tus cambios --no estés trabajando todo el fin de semana, sobre cuatro o cinco asuntos diferentes, y luego confirmes todo junto el lunes--. Aunque no hagas ninguna confirmación durante el fin de semana, el lunes puedes utilizar el área de preparación (staging area) para ir dividiendo tu trabajo y hacer una confirmación de cambios (commit) separada para cada asunto; con un mensaje adecuado para cada una de ellas. Si algunos de los cambios modifican un mismo archivo, utiliza el comando 'git add --patch' para almacenar parcialmente los archivos (tal y como se verá detalladamente en el Capítulo 6). El estado del proyecto al final de cada rama será idéntico si haces una sola confirmación o si haces cinco, en tanto en cuanto todos los cambios estén confirmados en un determinado momento. Por consiguiente, intenta facilitar las cosas a tus compañeros y compañeras desarroladores cuando vayan a revisar tus cambios. Además, esta manera de trabajar facilitará la integración o el descarte individual de alguno de los cambios, en caso de ser necesario. El Capítulo 6 contiene un gran número de trucos para reescribir el historial e ir preparando archivos interactivamente --utilizalos para ayudarte a crear un claro y comprensible historial--.
Y, por último, prestar atención al mensaje de confirmación. Si nos acostumbramos a poner siempre mensajes de calidad en las confirmaciones de cambios, facilitaremos en gran medida el trabajo y la colaboración con Git. Como regla general, tus mensajes han de comenzar con una ĺínea, de no más de 50 caracteres, donde se resuma el grupo de cambios; seguida de una línea en blanco; y seguida de una detallada explicación en las líneas siguientes. El proyecto Git obliga a incluir una explicación detallada; incluyendo tus motivaciones para los cambios realizados; y comentarios sobre las diferencias, tras su implementación, respecto del comportamiento anterior del programa. Esta recomendación es una buena regla a seguir. Es también buena idea redactar los mensajes utilizando el imperativo, en tiempo presente. Es decir, dá órdenes. Por ejemplo, en vez de escribir "He añadido comprobaciones para" o "Añadiendo comprobaciones para", utilizar la frase "Añadir comprobaciones para". Como plantilla de referencia, podemos utilizar la que escribió Tim Pope en tpope.net:
Un resumen de cambios, corto (50 caracteres o menos).
Seguido de un texto más detallado, si es necesario. Limitando las líneas a 72 caracteres mas o menos. En algunos contextos, la primera línea se tratará como si fuera el asundo de un correo electrónico y el resto del texto como si fuera el cuerpo. La línea en blanco separando el resumen del cuerpo es crítica (a no ser que se omita totalmente el cuerpo); algunas herramientas como 'rebase' pueden tener problemas si no los separas adecuadamente.
Los siguientes párrafos van tras la línea en blanco.
- Los puntos con bolo también están permitidos.
- Habitualmente se emplea un guión o un asterisco como bolo, seguido de un espacio, con líneas en blanco intermedias; pero las convenciones pueden variar.
Si todas tus confirmaciones de cambio (commit) llevan mensajes de este estilo, facilitarás las cosas tanto para tí como para las personas que trabajen contigo. El proyecto Git tiene los mensajes adecuadamente formateados. Te animo a lanzar el comando 'git log --no-merges' en dicho proyecto, para que veas la pinta que tiene un historial de proyecto limpio y claro.
En los ejemplos siguientes, y a lo largo de todo este libro, por razones de brevedad no formatearé correctamente los mensajes; sino que emplearé la opción '-m' en los comandos 'git commit'. Observa mis palabras, no mis hechos.
Pequeño Grupo Privado
Lo más simple que te puedes encontrar es un proyecto privado con uno o dos desarrolladores. Por privado, me refiero a código propietario --no disponible para ser leido por el mundo exterior--. Tanto tu como el resto del equipo teneis acceso de envio (push) al repositorio.
En un entorno como este, puedes seguir un flujo de trabajo similar al que adoptarías usando Subversion o algún otro sistema centralizado. Sigues disfrutando de ventajas tales como las confirmaciones offline y la mayor simplicidad en las ramificaciones/fusiones. Pero, en el fondo, la forma de trabajar será bastante similar; la mayor diferencia radica en que las fusiones (merge) se hacen en el lado cliente en lugar de en el servidor. Vamos a ver como actuarian dos desarrolladores trabajando conjuntamente en un repositorio compartido. El primero de ellos, John, clona el repositorio, hace algunos cambios y los confirma localmente: (en estos ejemplos estoy sustituyendo los mensajes del protocolo con '...' , para acortarlos)
# John's Machine
$ git clone john@githost:simplegit.git
Initialized empty Git repository in /home/john/simplegit/.git/
...
$ cd simplegit/
$ vim lib/simplegit.rb
$ git commit -am 'removed invalid default value'
[master 738ee87] removed invalid default value
1 files changed, 1 insertions(+), 1 deletions(-)
La segunda desarrolladora, Jessica, hace lo mismo: clona el repositorio y confirma algunos cambios:
# Jessica's Machine
$ git clone jessica@githost:simplegit.git
Initialized empty Git repository in /home/jessica/simplegit/.git/
...
$ cd simplegit/
$ vim TODO
$ git commit -am 'add reset task'
[master fbff5bc] add reset task
1 files changed, 1 insertions(+), 0 deletions(-)
Tras esto, Jessica envia (push) su trabajo al servidor:
# Jessica's Machine
$ git push origin master
...
To jessica@githost:simplegit.git
1edee6b..fbff5bc master -> master
John intenta enviar también sus cambios:
# John's Machine
$ git push origin master
To john@githost:simplegit.git
! [rejected] master -> master (non-fast forward)
error: failed to push some refs to 'john@githost:simplegit.git'
John no puede enviar porque Jessica ha enviado previamente. Entender bien esto es especialmente importante, sobre todo si estás acostumbrado a utilizar Subversion; porque habrás notado que ambos desarrolladores han editado archivos distintos. Mientras que Subversion fusiona automáticamente en el servidor cuando los cambios han sido aplicados sobre archivos distintos, en Git has de fusionar (merge) los cambios localmente. John se vé obligado a recuperar (fetch) los cambios de jessica y a fusionarlos (merge) con los suyos, antes de que se le permita enviar (push):
$ git fetch origin
...
From john@githost:simplegit
+ 049d078...fbff5bc master -> origin/master
En este punto, el repositorio local de John será algo parecido a la Figura 5-4.
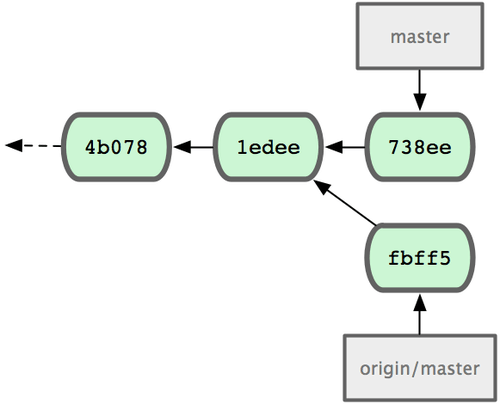
Figura 5-4. El repositorio inicial de John.
John tiene una referencia a los cambios enviados por Jessica, pero ha de fusionarlos en su propio trabajo antes de que se le permita enviar:
$ git merge origin/master
Merge made by recursive.
TODO | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
Si la fusión se realiza sin problemas, el historial de John será algo parecido a la Figura 5-5.
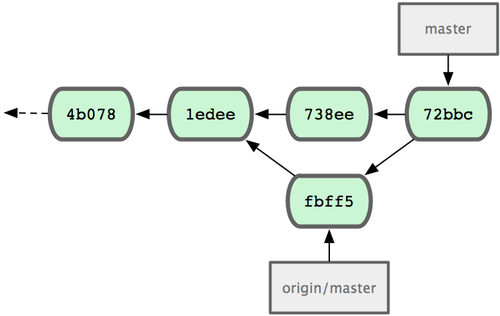
Figura 5-5. El repositorio de John tras fusionar origin/master.
En este momento, John puede comprobar su código para verificar que sigue funcionando correctamente, y luego puede enviar su trabajo al servidor:
$ git push origin master
...
To john@githost:simplegit.git
fbff5bc..72bbc59 master -> master
Finalmente, el historial de John es algo parecido a la Figura 5-6.
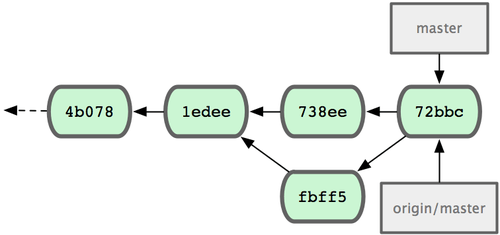
Figura 5-6. El historial de John tras enviar al servidor origen.
Mientras tanto, jessica ha seguido trabajando en una rama puntual (topic branch). Ha creado una rama puntual denominada 'issue54' y ha realizado tres confirmaciones de cambios (commit) en dicha rama. Como todavia no ha recuperado los cambios de John, su historial es como se muestra en la Figura 5-7.
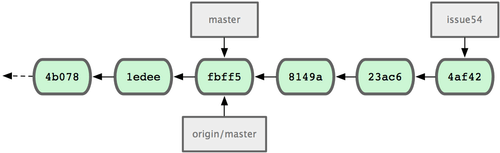
Figura 5-7. Historial inicial de Jessica.
Jessica desea sincronizarse con John, para lo cual:
# Jessica's Machine
$ git fetch origin
...
From jessica@githost:simplegit
fbff5bc..72bbc59 master -> origin/master
Esto recupera el trabajo enviado por John durante el tiempo en que Jessica estaba trabajando. El historial de Jessica es en estos momentos como se muestra en la figura 5-8.
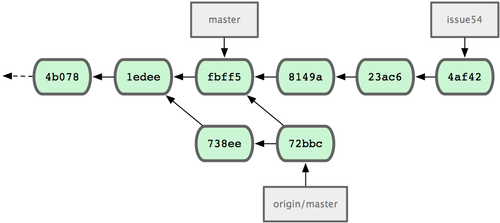
Figura 5-8. El historial de Jessica tras recuperar los cambios de John.
Jessica considera su rama puntual terminada, pero quiere saber lo que debe integrar con su trabajo antes de poder enviarla. Lo comprueba con el comando 'git log':
$ git log --no-merges origin/master ^issue54
commit 738ee872852dfaa9d6634e0dea7a324040193016
Author: John Smith <jsmith@example.com>
Date: Fri May 29 16:01:27 2009 -0700
removed invalid default value
Ahora, jessica puede fusionar (merge) su trabajo de la rama puntual 'issue54' en su rama 'master'l, fusionar (merge) el trabajo de John ('origin/master') en su rama 'master', y enviarla de vuelta al servidor. Primero, se posiciona de nuevo en su rama principal para integrar todo su trabajo:
$ git checkout master
Switched to branch "master"
Your branch is behind 'origin/master' by 2 commits, and can be fast-forwarded.
Puede fusionar primero tanto 'origin/master' o como 'issue54', ya que ambos están aguas arriba. La situación final (snapshot) será la misma, indistintamente del orden elegido; tan solo el historial variará ligeramente. Elige fusionar primero 'issue54':
$ git merge issue54
Updating fbff5bc..4af4298
Fast forward
README | 1 +
lib/simplegit.rb | 6 +++++-
2 files changed, 6 insertions(+), 1 deletions(-)
No hay ningún problema; como puedes observar, es un simple avance rápido (fast-forward). Tras esto, jessica fusiona el trabajo de John ('origin/master'):
$ git merge origin/master
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
Todo se integra limpiamente, y el historial de Jessica queda como en la Figura 5-9.
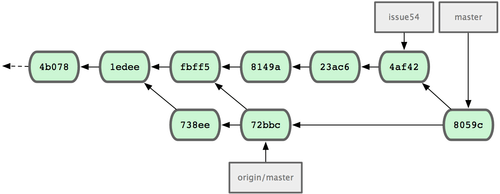
Figura 5-9. El historial de Jessica tras fusionar los cambios de John.
En este punto, la rama 'origin/master' es alcanzable desde la rama 'master' de Jessica, permitiendole enviar (push) --asumiendo que John no haya enviado nada más durante ese tiempo--:
$ git push origin master
...
To jessica@githost:simplegit.git
72bbc59..8059c15 master -> master
Cada desarrollador ha confirmado algunos cambios y ambos han fusionado sus trabajos correctamente; ver Figura 5-10.
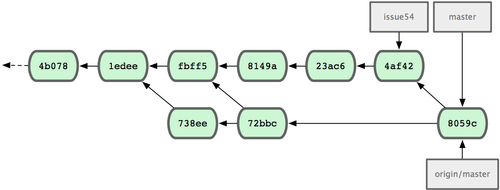
Figura 5-10. El historial de Jessica tras enviar de vuelta todos los cambios al servidor.
Este es uno de los flujos de trabajo más simples. Trabajas un rato, normalmente en una rama puntual de un asunto concreto, y la fusionas con tu rama principal cuando la tienes lista para integrar. Cuando deseas compartir ese trabajo, lo fusionas (merge) en tu propia rama 'master'; luego recuperas (fetch) y fusionas (merge) la rama 'origin/master', por si hubiera cambiado; y finalmente envias (push) la rama 'master' de vuelta al servidor. La secuencia general es algo así como la mostrada en la Figura 5-11.
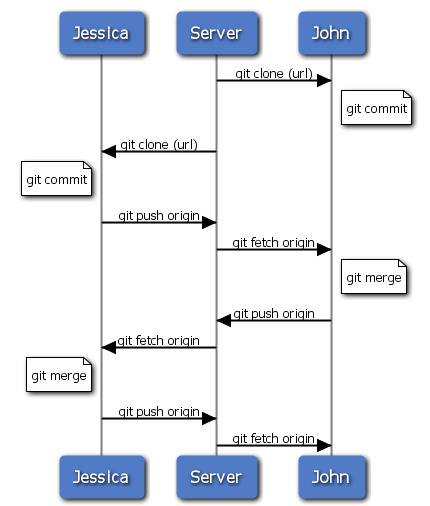
Figura 5-11. Secuencia general de eventos en un flujo de trabajo multidesarrollador simple.
Grupo Privado Gestionado
En este próximo escenario, vamos a hechar un vistazo al rol de colaborador en un gran grupo privado. Aprenderás cómo trabajar en un entorno donde pequeños grupos colaboran en algunas funcionalidades, y luego todas las aportaciones de esos equipos son integradas por otro grupo.
Supongamos que John y Jessica trabajan conjuntamente en una funcionalidad, mientras que jessica y Josie trabajan en una segunda funcionalidad. En este caso, la compañia está utilizando un flujo de trabajo del tipo gestor-de-integración, donde el trabajo de algunos grupos individuales es integrado por unos ingenieros concretos; siendo solamente estos últimos quienes pueden actualizar la rama 'master' del repositorio principal. En este escenario, todo el trabajo se realiza en ramas propias de cada grupo y es consolidado por los integradores más tarde.
Vamos a seguir el trabajo de Jessica, a medida que trabaja en sus dos funcionalidade; colaborando en paralelo con dos desarrolladores distintos. Suponiendo que tiene su repositorio ya clonado, ella decide trabajar primero en la funcionalidad A (featureA). Crea una nueva rama para dicha funcionalidad y trabaja en ella:
# Jessica's Machine
$ git checkout -b featureA
Switched to a new branch "featureA"
$ vim lib/simplegit.rb
$ git commit -am 'add limit to log function'
[featureA 3300904] add limit to log function
1 files changed, 1 insertions(+), 1 deletions(-)
En ese punto, necesita compartir su trabajo con John, por lo que envia (push) al servidor las confirmaciones (commits) en su rama 'featureA'. Como Jessica no tiene acceso de envio a la rama 'master' --solo los integradores lo tienen--, ha de enviar a alguna otra rama para poder colaborar con John:
$ git push origin featureA
...
To jessica@githost:simplegit.git
* [new branch] featureA -> featureA
Jessica notifica a John por correo electrónico que ha enviado trabajo a una rama denominada 'featureA' y que puede hecharle un vistazo allí. Mientras espera noticias de John, Jessica decide comenzar a trabajar en la funcionalidad B (featureB) con Josie. Para empezar, arranca una nueva rama puntual, basada en la rama 'master' del servidor:
# Jessica's Machine
$ git fetch origin
$ git checkout -b featureB origin/master
Switched to a new branch "featureB"
Y realiza un par de confirmaciones de cambios (commits) en la rama 'featureB':
$ vim lib/simplegit.rb
$ git commit -am 'made the ls-tree function recursive'
[featureB e5b0fdc] made the ls-tree function recursive
1 files changed, 1 insertions(+), 1 deletions(-)
$ vim lib/simplegit.rb
$ git commit -am 'add ls-files'
[featureB 8512791] add ls-files
1 files changed, 5 insertions(+), 0 deletions(-)
Quedando su repositorio como se muestra en la Figura 5-12
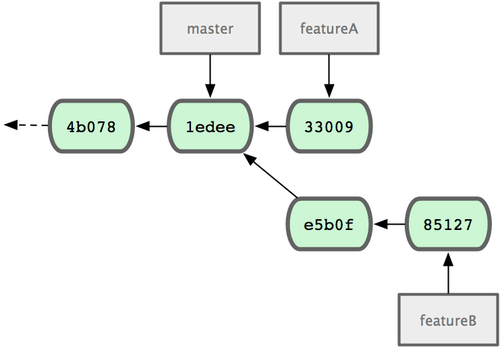
Figura 5-12. Historial inicial de Jessica.
Cuando está preparada para enviar (push) su trabajo, recibe un correo electronico de Josie de que ha puesto en el servidor una rama denominada 'featureBee', con algo de trabajo. Jessica necesita fusionar (merge) dichos cambios con los suyos antes de poder enviarlos al servidor. Por tanto, recupera (fetch) los cambios de Josie:
$ git fetch origin
...
From jessica@githost:simplegit
* [new branch] featureBee -> origin/featureBee
Y los fusiona con su propio trabajo:
$ git merge origin/featureBee
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 4 ++++
1 files changed, 4 insertions(+), 0 deletions(-)
Pero hay un pequeño problema, necesita enviar el trabajo fusionado en su rama 'featureB' a la rama 'featureBee' del servidor. Puede hacerlo usando el comando 'git push' e indicando específicamente el nombre de la rama local seguida de dos puntos (:) y seguida del nombre de la rama remota:
$ git push origin featureB:featureBee
...
To jessica@githost:simplegit.git
fba9af8..cd685d1 featureB -> featureBee
Esto es lo que se denomina un refspec. Puedes ver el Capítulo 9 para una discusión más detallada acerca de los refspecs de Git y los distintos usos que puedes darles.
A continuación, John envia un correo electronico a jessica comentandole que ha enviado algunos cambios a la rama 'featureA' y pidiendole que los verifique. Ella lanza un 'git fetch' para recuperar dichos cambios:
$ git fetch origin
...
From jessica@githost:simplegit
3300904..aad881d featureA -> origin/featureA
A continuación, puede ver las modificaciones realizadas, lanzando el comando 'git log':
$ git log origin/featureA ^featureA
commit aad881d154acdaeb2b6b18ea0e827ed8a6d671e6
Author: John Smith <jsmith@example.com>
Date: Fri May 29 19:57:33 2009 -0700
changed log output to 30 from 25
Para terminar, fusiona el trabajo de John en su propia rama 'featureA':
$ git checkout featureA
Switched to branch "featureA"
$ git merge origin/featureA
Updating 3300904..aad881d
Fast forward
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)
Jessica realiza algunos ajustes, los confirma (commit) y los envia (push) de vuelta al servidor:
$ git commit -am 'small tweak'
[featureA ed774b3] small tweak
1 files changed, 1 insertions(+), 1 deletions(-)
$ git push origin featureA
...
To jessica@githost:simplegit.git
3300904..ed774b3 featureA -> featureA
Quedando su historial como se muestra en la Figura 5-13.
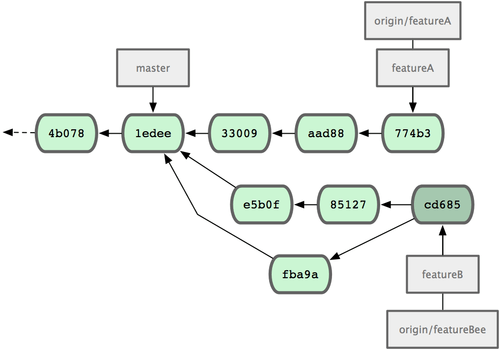
Figura 5-13. El historial de Jessica después de confirmar cambios en una rama puntual.
Jessica, Josie y John informan a los integradores de que las ramas 'featureA' y 'featureBee' del servidor están preparadas para su integración con la línea principal del programa. Despues de que dichas ramas sean integradas en la línea principal, una recuperación (fetch) traerá de vuelta las confirmaciones de cambios de las integraciones (merge commits), dejando un historial como el mostrado en la Figura 5-14.
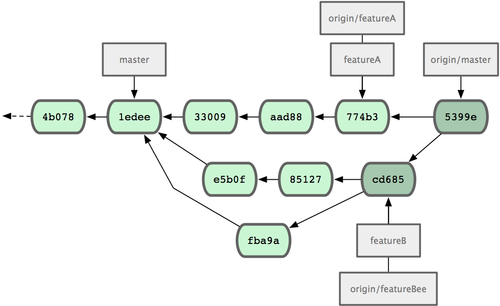
Figura 5-14. El historial de Jessica tras fusionar sus dos ramas puntuales.
Muchos grupos se están pasando a trabajar con Git, debido a su habilidad para mantener multiples equipos trabajando en paralelo, fusionando posteriormente las diferentes líneas de trabajo. La habilidad para que pequeños subgrupos de un equipo colaboren a través de ramas remotas, sin necesidad de tener en cuenta o de perturbar el equipo completo, es un gran beneficio de trabajar con Git. La secuencia del flujo de trabajo que hemos visto es algo así como lo mostrado en la Figura 5-15.
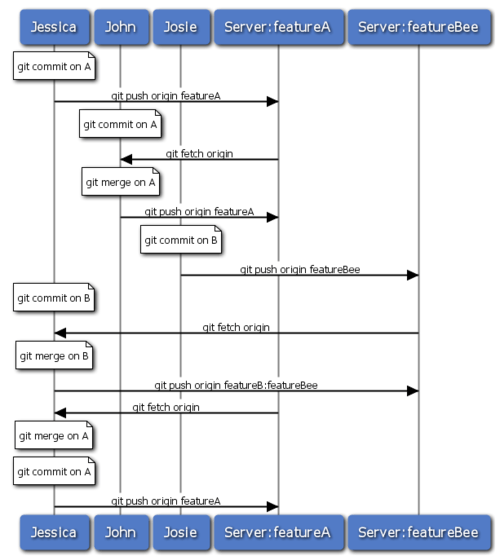
Figura 5-15. Secuencia básica de este flujo de trabajo en equipo gestionado.
Pequeño Proyecto Público
Contribuir a proyectos públicos es ligeramente diferente. Ya que no tendrás permisos para actualizar ramas directamente sobre el proyecto, has de enviar el trabajo a los gestores de otra manera. En este primer ejemplo, veremos cómo contribuir a través de bifurcaciones (forks) en servidores Git que soporten dichas bifurcaciones. Los sitios como repo.or.cz ó GitHub permiten realizar esto, y muchos gestores de proyectos esperan este estilo de contribución. En la siguiente sección, veremos el caso de los proyectos que prefieren aceptar contribuciones a través del correo electrónico.
Para empezar, problemente desees clonar el repositorio principal, crear una rama puntual para el parche con el que piensas contribuir, y ponerte a trabajar sobre ella. La secuencia será algo parecido a esto:
$ git clone (url)
$ cd project
$ git checkout -b featureA
$ (work)
$ git commit
$ (work)
$ git commit
Puedes querer utilizar 'rebase -i' para reducir tu trabajo a una sola confirmación de cambios (commit), o reorganizar el trabajo en las diversas confirmaciones para facilitar la revisión de parche por parte del gestor del proyecto --ver el Capítulo 6 para más detalles sobre reorganizaciones interactivas--.
Cuando el trabajo en tu rama puntual está terminado y estás listo para enviarlo al gestor del proyecto, vete a la página del proyecto original y clica sobre el botón "Fork" (bifurcar), para crear así tu propia copia editable del proyecto. Tendrás que añadir la URL a este nuevo repositorio como un segundo remoto, y en este caso lo denominaremos 'myfork':
$ git remote add myfork (url)
Tu trabajo lo enviarás (push) a este segundo remoto. Es más sencillo enviar (push) directamente la rama puntual sobre la que estás trabajando, en lugar de fusionarla (merge) previamente con tu rama principal y enviar esta última. Y la razón para ello es que, si el trabajo no es aceptado o se integra solo parcialmente, no tendrás que rebobinar tu rama principal. Si el gestor del proyecto fusiona (merge), reorganiza (rebase) o integra solo parcialmente tu trabajo, aún podrás recuperarlo de vuelta a través de su repositorio:
$ git push myfork featureA
Tras enviar (push) tu trabajo a tu copia bifurcada (fork), has de notificarselo al gestor del proyecto. Normalmente se suele hacer a través de una solicitud de recuperación/integración (pull request). La puedes generar directamente desde el sitio web, --GitHub tiene un botón "pull request" que notifica automáticamente al gestor--, o puedes lanzar el comando 'git request-pull' y enviar manualmente su salida por correo electrónico al gestor del proyecto.
Este comando 'request-pull' compara la rama base donde deseas que se integre tu rama puntual y el repositorio desde cuya URL deseas que se haga, para darte un resumen de todos los cambios que deseas integrar. Por ejemplo, si Jessica quiere enviar a John una solicitud de recuperación, y ha realizado dos confirmaciones de cambios sobre la rama puntual que desea enviar, lanzará los siguientes comandos:
$ git request-pull origin/master myfork
The following changes since commit 1edee6b1d61823a2de3b09c160d7080b8d1b3a40:
John Smith (1):
added a new function
are available in the git repository at:
git://githost/simplegit.git featureA
Jessica Smith (2):
add limit to log function
change log output to 30 from 25
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)
Esta salida puede ser enviada al gestor del proyecto, --le indica el punto donde se ramificó, resume las confirmaciones de cambio, y le dice desde dónde recuperar estos cambios--.
En un proyecto del que no seas gestor, suele ser más sencillo tener una rama tal como 'master' siguiendo siempre a la rama 'origin/master'; mientras realizas todo tu trabajo en otras ramas puntuales, que podrás descartar facilmente en caso de que alguna de ellas sea rechazada. Manteniendo el trabajo de distintos temas aislados en sus respectivas ramas puntuales, te facilitas también el poder reorganizar tu trabajo si la cabeza del repositorio principal se mueve mientras tanto y tus confirmaciones de cambio (commits) ya no se pueden integrar limpiamente. Por ejemplo, si deseas contribuir al proyecto en un segundo tema, no continues trabajando sobre la rama puntual que acabas de enviar; comienza una nueva rama puntual desde la rama 'master' del repositorio principal:
$ git checkout -b featureB origin/master
$ (work)
$ git commit
$ git push myfork featureB
$ (email maintainer)
$ git fetch origin
De esta forma, cada uno de los temas está aislado dentro de un silo, --similar a una cola de parches--; permitiendote reescribir, reorganizar y modificar cada uno de ellos sin interferir ni crear interdependencias entre ellos.
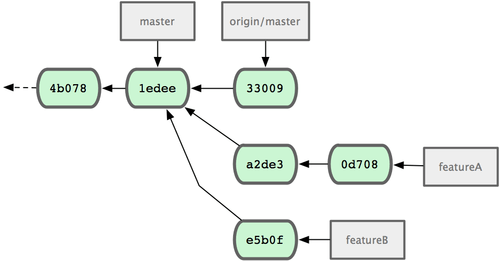
Figura 5-16. Historial inicial con el trabajo de la funcionalidad B.
Supongamos que el gestor del proyecto ha recuperado e integrado un grupo de otros parches y después lo intenta con tu primer parche, viendo que no se integra limpiamente. En este caso, puedes intentar reorganizar (rebase) tu parche sobre 'origin/master', arreglar los conflictos y volver a enviar tus cambios:
$ git checkout featureA
$ git rebase origin/master
$ git push –f myfork featureA
Esto reescribe tu historial, quedando como se vé en la Figura 5-17.
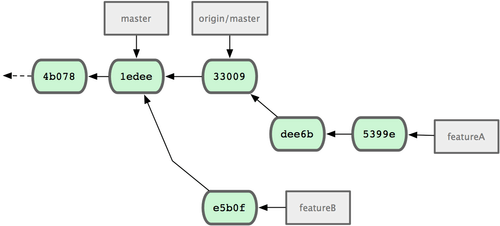
Figura 5-17. Historial tras el trabajo en la funcionalidad A.
Debido a que has reorganizado (rebase) tu rama de trabajo, tienes que indicar la opción '-f' en tu comando de envio (push), para permitir que la rama 'featureA' del servidor sea reemplazada por una confirmación de cambios (commit) que no es hija suya. Una alternativa podría ser el enviar (push) este nuevo trabajo a una rama diferente del servidor (por ejemplo a 'featureAv2').
Vamos a ver otro posible escenario: el gestor del proyecto ha revisado tu trabajo en la segunda rama y le ha gustado el concepto, pero desea que cambies algunos detalles de la implementación. Puedes aprovechar también esta oportunidad para mover el trabajo y actualizarlo sobre la actual rama 'master' del proyecto. Para ello, inicias una nueva rama basada en la actual 'origin/master', aplicas (squash) sobre ella los cambios de 'featureB', resuelves los posibles conflictos que se pudieran presentar, realizas los cambios en los detalles, y la envias de vuelta como una nueva rama:
$ git checkout -b featureBv2 origin/master
$ git merge --no-commit --squash featureB
$ (change implementation)
$ git commit
$ git push myfork featureBv2
La opción '--squash' coge todo el trabajo en la rama fusionada y lo aplica, en una sola confirmación de cambios sin fusión (no-merge commit), sobre la rama en la que estés situado. La opción '--no-commit' indica a Git que no debe registrar automáticamente una confirmación de cambios. Esto te permitirá el aplicar todos los cambios de la otra rama y después hacer más cambios, antes de guardarlos todos ellos en una nueva confirmación (commit).
En estos momentos, puedes notificar al gestor del proyecto que has realizado todos los cambios solicitados y que los puede encontrar en tu rama 'featureBv2' (ver Figura 5-18).
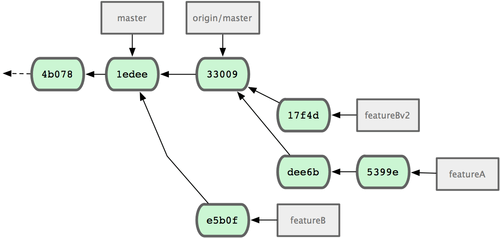
Figura 5-18. Historial tras el trabajo en la versión 2 de la funcionalidad B.
Proyecto Público Grande
Muchos grandes proyectos suelen tener establecidos los procedimientos para aceptar parches; --es necesario que compruebes las normas específicas para cada proyecto, ya que pueden variar de uno a otro--. De todas formas, muchos de los proyectos públicos más grandes aceptar parches a través de una lista de correo electrónico, por lo que veremos un ejemplo de dicho procedimiento.
El flujo de trabajo es similar a los casos de uso vistos anteriormente; --creando ramas puntuales para cada serie de parches en los que vayas a trabajar--. La diferencia está en la forma de enviarlos al proyecto. En lugar de bifurcar (fork) el proyecto y enviar a tu propia copia editable, generarás correos electrónicos para cada serie de parches y os enviarás a la lista de correo.
$ git checkout -b topicA
$ (work)
$ git commit
$ (work)
$ git commit
Tienes dos confirmaciones de cambios (commits) a enviar a la lista de correo. Utilizarás el comando git format-patch para generar archivos formateados para poder ser enviados por correo electrónico. Este comando convierte cada confirmación de cambios (commit) en un mensaje de correo; con la primera línea del mensaje de confirmación puesto como asunto, y el resto del mensaje mas el parche como cuerpo. Lo bonito de este procedimiento es que, al aplicar un parche desde un correo electrónico generado por format-patch, se preserva íntegramente la información de la confirmación de cambios (commit). Lo veremos más adelante, en la próxima sección, cuando veamos como aplicarlos:
$ git format-patch -M origin/master
0001-add-limit-to-log-function.patch
0002-changed-log-output-to-30-from-25.patch
El comando format-patch lista los nombres de los archivos de parche que crea. La opción -M indica a Git que ha de mirar por si hay algo renombrado. Los archivos serán algo como:
$ cat 0001-add-limit-to-log-function.patch
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] add limit to log function
Limit log functionality to the first 20Limit log functionality to the first 20Limit log functionality to the first 20
---
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index 76f47bc..f9815f1 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -14,7 +14,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log #{treeish}")
+ command("git log -n 20 #{treeish}")
end
def ls_tree(treeish = 'master')
--
1.6.2.rc1.20.g8c5b.dirty
Puedes incluso editar esos archivos de parche, para añadirles más información , específica para la lista de correo, y que no desees mostrar en el propio mensaje de la confirmación de cambios. Si añades texto entre la línea que comienza por --- y el comienzo del parche (la línea lib/simplegit.rb). Los desarrolladores de la lista de correo podrán leerlo. Pero será ignorado al aplicar el parche al proyecto.
Para enviar estos archivos a la lista de correo,puedes tanto pegar directamente el archivo en tu programa de correo electrónico, como enviarlo a través de algún programa basado en línea de comandos. Pegar el texto directamente suele causar problemas de formato. Especialmente con los clientes de correo más "inteligentes", que no preservan adecuadamente los saltos de línea y otros espaciados. Afortunadamente, Git suministra una herramienta que nos puede ser de gran ayuda para enviar parches correctamente formateados a través de protocolo IMAP, facilitandonos así las cosas. Voy a indicar cómo enviar un parche usando Gmail, que da la casualidad de que es el agente de correo utilizado por mí. En el final del anteriormente citado documento, Documentation/SubmittingPatches, puedes leer instrucciones detalladas para otros agentes de correo.
Lo primero es configurar correctamente el apartado imap de tu archivo ~/.gitconfig. Puedes ir ajustando cada valor individualmente, a través de comandos git config; o puedes añadirlos todos manualmente. Pero, al final, tu archivo de configuración ha de quedar más o menos como esto:
[imap]
folder = "[Gmail]/Drafts"
host = imaps://imap.gmail.com
user = user@gmail.com
pass = p4ssw0rd
port = 993
sslverify = false
Las dos últimas líneas probablente no sean necesarias si tu servidor IMAP no utiliza SSL; y, en ese caso, el valor para host deberá de ser imap:// en lugar de imaps://.
Cuando tengas esto ajustado, podrás utilizar el comando git send-email para poner series de parches en la carpeta de borradores (Drafts) de tu servidor IMAP:
$ git send-email *.patch
0001-added-limit-to-log-function.patch
0002-changed-log-output-to-30-from-25.patch
Who should the emails appear to be from? [Jessica Smith <jessica@example.com>]
Emails will be sent from: Jessica Smith <jessica@example.com>
Who should the emails be sent to? jessica@example.com
Message-ID to be used as In-Reply-To for the first email? y
Tras esto, Git escupirá una serie de información de registro, con pinta más o menos como esta:
(mbox) Adding cc: Jessica Smith <jessica@example.com> from
\line 'From: Jessica Smith <jessica@example.com>'
OK. Log says:
Sendmail: /usr/sbin/sendmail -i jessica@example.com
From: Jessica Smith <jessica@example.com>
To: jessica@example.com
Subject: [PATCH 1/2] added limit to log function
Date: Sat, 30 May 2009 13:29:15 -0700
Message-Id: <1243715356-61726-1-git-send-email-jessica@example.com>
X-Mailer: git-send-email 1.6.2.rc1.20.g8c5b.dirty
In-Reply-To: <y>
References: <y>
Result: OK
En estos momentos, deberías poder ir a tu carpeta de borradores (Drafts), cambiar el destinatario (To) para apuntar a la lista de correo donde estés enviando el parche, puede que poner en copia (CC) al gestor o persona responsable, y enviar el mensaje.
Recapitulación
En esta sección hemos visto unos cuantos de los flujos de trabajo más habituales para lidiar con distintos tipos de proyectos Git. Y hemos introducido un par de nuevas herramientas para ayudarte a gestionar estos procesos. A continuación veremos cómo trabajar en el otro lado de la moneda: manteniendo y gestionando un proyecto Git. Vas a aprender cómo ser un dictador benevolente o un gestor de integración.