Los objetos Git
Git es un sistema de archivo orientado a contenidos. Estupendo. Y eso, ¿qué significa? Pues significa que el núcleo Git es un simple almacén de claves y valores. Cuando insertas cualquier tipo de contenido, él te devuelve una clave que puedes utilizar para recuperar de nuevo dicho contenido en cualquier momento. Para verlo en acción, puedes utilizar el comando de fontanería 'hash-object'. Este comando coge ciertos datos, los guarda en la carpeta '.git.' y te devuelve la clave bajo la cual se han guardado. Para empezar, inicializa un nuevo repositorio Git y comprueba que la carpeta 'objects' está vacia.
$ mkdir test
$ cd test
$ git init
Initialized empty Git repository in /tmp/test/.git/
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type f
$
Git ha inicializado la carpeta 'objects', creando en ella las subcarpetas 'pack' e 'info'; pero aún no hay archivos en ellas. Luego, guarda algo de texto en la base de datos de Git:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
La opción '-w' indica a 'hash-object' que ha de guardar el objeto; de otro modo, el comando solo te respondería cual sería su clave. La opción '--stdin' indica al comando de leer desde la entrada estandar stdin; si no lo indicas, 'hash-object' espera encontrar la ubicación de un archivo. La salida del comando es una suma de comprobación (checksum hash) de 40 caracteres. Este checksum hash SHA-1 es una suma de comprobación del contenido que estás guardando más una cabecera; cabecera sobre la que trataremos en breve. En estos momentos, ya puedes comprobar la forma en que Git ha guardado tus datos:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
Como puedes ver, hay un archivo en la carpeta 'objects'. En principio, esta es la forma en que guarda Git los contenidos; como un archivo por cada pieza de contenido, nombrado con la suma de comprobación SHA-1 del contenido y su cabecera. La subcarpeta se nombra con los primeros 2 caracteres del SHA, y el archivo con los restantes 38 caracteres.
Puedes volver a recuperar los contenidos usando el comando 'cat-file'. Este comando es algo así como una "navaja suiza" para inspeccionar objetos Git. Pasandole la opción '-p', puedes indicar al comando 'cat-file' que deduzca el tipo de contenido y te lo muestre adecuadamente:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content
Ahora que sabes cómo añadir contenido a Git y cómo recuperarlo de vuelta. Lo puedes hacer también con el propio contenido de los archivos. Por ejemplo, puedes realizar un control simple de versiones sobre un archivo. Para ello, crea un archivo nuevo y guarda su contenido en tu base de datos:
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30
A continuación, escribe algo más de contenido en el archivo y vuelvelo a guardar:
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
Tu base de datos contendrá las dos nuevas versiones del archivo, así como el primer contenido que habias guardado en ella antes:
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
Podrás revertir el archivo a su primera versión:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1
o a su segunda versión
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2
Pero no es práctico esto de andar recordando la clave SHA-1 para cada versión de tu archivo; es más, realmente no estás guardando el nombre de tu archivo en el sistema, --solo su contenido--. Este tipo de objeto se denomina un blob (binary large object). Con la orden 'cat-file -t' puedes comprobar el tipo de cualquier objeto almacenado en Git, sin mas que indicar su clave SHA-1':
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blob
Objetos tipo arbol
El siguiente tipo de objeto a revisar serán los objetos tipo arbol. Estos se encargan de resolver el problema de guardar un nombre de archivo, a la par que guardamos conjuntamente un grupo de archivos. Git guarda contenido de manera similar a un sistema de archivos UNIX, pero de forma algo más simple. Todo el contenido se guarda como objetos arbol (tree) u objetos binarios (blob). Correspondiendo los árboles a las entradas de carpetas; y correspondiendo los binarios, mas o menos, a los contenidos de los archivos (inodes). Un objeto tipo árbol tiene una o más entradas de tipo arbol. Y cada una de ellas consta de un puntero SHA-1 a un objeto binario (blob) o a un subárbol, más sus correspondientes datos de modo, tipo y nombre de archivo. Por ejemplo, el árbol que hemos utilizado recientemente en el proyecto simplegit, puede resultar algo así como:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 lib
La sentencia master^{tree} indica el objeto árbol apuntado por la última confirmación de cambios (commit) en tu rama principal (master). Fíjate en que la carpeta lib no es un objeto binario, sino un apuntador a otro objeto tipo árbol.
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb
Conceptualmente, la información almacenada por Git es algo similar a la Figura 9-1.
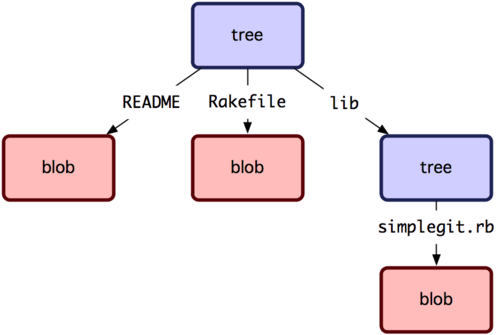
Figura 9-1. Versión simplificada del modelo de datos de Git.
Puedes crear tu propio árbol. Habitualmente Git suele crear un árbol a partir del estado de tu área de preparación (staging area) o índice, escribiendo un objeto árbol con él. Por tanto, para crear un objeto árbol, previamente has de crear un índice preparando algunos archivos para ser almacenados. Puedes utilizar el comando de "fontaneria" update-index para crear un índice con una sola entrada, --la primera version de tu archivo text.txt--. Este comando se utiliza para añadir artificialmente la versión anterior del archivo test.txt. a una nueva área de preparación Has de utilizar la opción --add, porque el archivo no existe aún en tu área de preparación (es más, ni siquiera tienes un área de preparación). Y has de utilizar también la opción --cacheinfo, porque el archivo que estas añadiendo no está en tu carpeta, sino en tu base de datos. Para terminar, has de indicar el modo, la clave SHA-1 y el nombre de archivo:
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txt
En este caso, indicas un modo 100644, el modo que denota un archivo normal. Otras opciones son 100755, para un achivo ejecutable; o 120000, para un enlace simbólico. Estos modos son como los modos de UNIX, pero mucho menos flexibles. Solo estos tres modos son válidos para archivos (blobs) en Git; (aunque también se permiten otros modos para carpetas y submódulos).
Tras esto, puedes usar el comando write-tree para escribir el área de preparacón a un objeto tipo árbol. Sin necesidad de la opción -w, solo llamando al comando write-tree, y si dicho árbol no existiera ya, se crea automáticamente un objeto tipo árbol a partir del estado del índice.
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
También puedes comprobar si realmente es un objeto tipo árbol:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree
Vamos a crear un nuevo árbol con la segunda versión del archivo test.txt y con un nuevo archivo.
$ echo 'new file' > new.txt
$ git update-index test.txt
$ git update-index --add new.txt
El área de preparación contendrá ahora la nueva versión de test.txt, así como el nuevo archivo new.txt. Escribiendo este árbol, (guardando el estado del área de preparación o índice), podrás ver que aparece algo así como:
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
Aquí se vén las entradas para los dos archivos y también el que la suma de comprobación SHA-1 de test.txt es la "segunda versión" de la anterior (1f7a7a). Simplemente por diversión, puedes añadir el primer árbol como una subcarpeta de este otro. Para leer árboles al área de preparación puedes utilizar el comando read-tree. Y, en este caso, puedes hacerlo como si fuera una subcarpeta utilizando la opción --prefix:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
Si crearas una carpeta de trabajo a partir de este nuevo árbol que acabas de escribir, obtendrías los dos archivos en el nivel principal de la carpeta de trabajo y una subcarpeta llamada bak conteniendo la primera versión del archivo test.txt. Puedes pensar en algo parecido a la Figura 9-2 para representar los datos guardados por Git para estas estructuras.
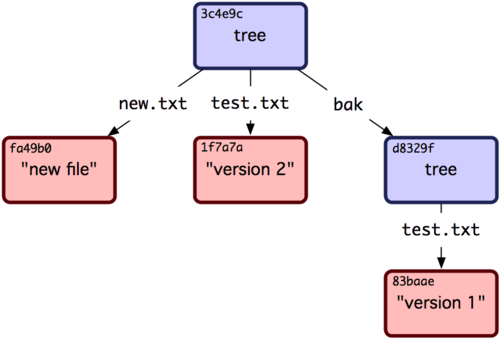
Figura 9-2. La estructura del contenido Git para tus datos actuales.
Objetos de confirmación de cambios
Tienes tres árboldes que representan diferentes momentos interesantes de tu proyecto, pero el problema principal sigue siendo el estar obligado a recordar los tres valores SHA-1 para poder recuperar cualquiera de esos momentos. Asimismo, careces de información alguna sobre quién guardó las instantáneas de esos momentos, cuándo fueron guardados o por qué se guardaron. Este es el tipo de información que almacenan para tí los objetos de confirmación de cambios.
Para crearlos, tan solo has de llamar al comando commit-tree, indicando uno de los árboles SHA-1 y los objetos de confirmación de cambios que lo preceden (si es que lo precede alguno). Empezando por el primer árbol que has escrito:
$ echo 'first commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Con el comando cat-file puedes revisar el nuevo objeto de confirmación de cambios recién creado:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
first commit
El formato para un objeto de confirmación de cambios (commit) es sencillo, contemplando: el objeto tipo árbol para la situación del proyecto en ese momento puntual; la información sobre el autor/confirmador, recogida desde las opciones de configuraciónuser.name y user.email; la fecha y hora actuales; una línea en blanco; y el mensaje de la confirmación de cambios.
Puedes seguir adelante, escribiendo los otros dos objetos de confirmación de cambios. Y relacionando cada uno de ellos con su inmediato anterior:
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9
Cada uno de estos tres objetos de confirmación de cambios apunta a uno de los tres objetos tipo árbol que habias creado previamente. Más aún, en estos momentos tienes ya un verdadero historial Git. Lo puedes comprobar con el comando git log. Lanzandolo mientras estás en la última de las confirmaciones de cambio.
$ git log --stat 1a410e commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletions(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
¡Sorprendente!. Acabas de confeccionar un historial Git utilizando solamente operaciones de bajo nivel, sin usar ninguno de los interfaces principales. Esto es básicamente lo que hace Git cada vez que utilizas los comandos git add y git commit: guardar objetos binarios (blobs) para los archivos modificados, actualizar el índice, escribir árboles (trees), escribir objetos de confirmación de cambios (commits) que los referencian y relacionar cada uno de ellos con su inmediato precedente. Estos tres objetos Git, -binario, árbol y confirmación de cambios--, se guardan como archivos separados en la carpeta .git/objects. Aquí se muestran todos los objetos presentes en este momento en la carpeta del ejemplo, con comentarios acerca de lo que almacena cada uno de ellos:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1
Siguiendo todos los enlaces internos, puedes llegar a un gráfico similar al de la figura 9-3.
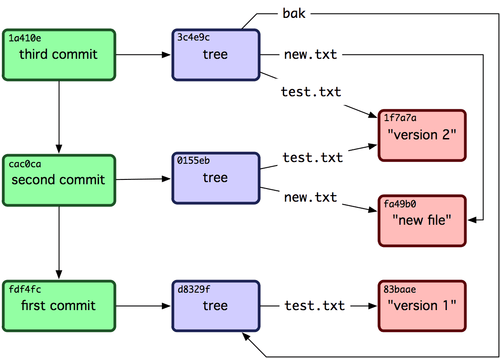
Figura 9-3. Todos los objetos en tu carpeta Git.
Almacenamiento de los objetos
He citado anteriormente que siempre se almacena una cabecera junto al contenido. Vamos a hechar un vistazo a cómo Git almacena sus objetos. Te mostraré el proceso de guardar un objeto binario grande (blob), --en este caso la cadena de texto "what is up, doc?" (¿qué hay de nuevo, viejo?)--, interactivamente, en el lenguaje de script Ruby. Puedes arrancar el modo interactivo de Ruby con el comando irb:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"
Git construye la cabecera comenzando por el tipo de objeto, en este caso un objeto binario grande (blob). Después añade un espacio, seguido del tamaño del contenido y termina con un byte nulo:
>> header = "blob #{content.length}\0"
=> "blob 16\000"
Git concatena la cabecera y el contenido original, para calcular la suma de control SHA-1 conjunta. En Ruby, para calcular el valor SHA-1 de una cadena de texto: has de incluir la libreria de generación SHA1 con el comando require y llamar luego a la orden Digest::SHA1.hexdigest():
>> store = header + content
=> "blob 16\000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"
Git comprime todo el contenido con zlib. Y tu puedes hacer lo mismo en Ruby con la libreria zlib. Primero has de incluir la libreria y luego lanzar la orden Zlib::Deflate.deflate() sobre el contenido:
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\234K\312\311OR04c(\317H,Q\310,V(-\320QH\311O\266\a\000_\034\a\235"
Para terminar, has de escribir el contenido comprimido en un objeto en disco. Para fijar el lugar donde almacenarlo, utilizaremos como nombre de carpeta los dos primeros caracteres del valor SHA-1 y como nombre de archivo los restantes 38 caracteres de dicho valor SHA-1. En Ruby, puedes utilizar la función FileUtils.mkdir_p() para crear una carpeta. Después, puedes abrir un archivo con la orden File.open() y escribir contenido en él con la orden write():
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32
Y ¡esto es todo!. --acabas de crear un auténtico objeto Git binario grande (blob)--. Todos los demas objetos Git se almacenan de forma similar, pero con la diferencia de que sus cabeceras comienzan con un tipo diferente. En lugar de 'blob' (objeto binario grande), comenzarán por 'commit' (confirmación de cambios), o por 'tree' (árbol). Además, el contenido de un binario (blob) puede ser prácticamente cualquier cosa. Mientras que el contenido de una confirmación de cambios (commit) o de un árbol (tree) han de seguir unos formatos internos muy concretos.