Gestionando un proyecto
Además de conocer cómo contribuir de forma efectiva a un proyecto, es posible que desees saber tambien cómo mantener uno. Lo cual implicará saber aceptar y aplicar parches generados vía format-patch, enviados a tí a través de correo electronico; o saber integrar cambios realizados en ramas de repositorios que añadirás como remotos a tu proyecto. Tanto si gestionas un repositorio canónico, como si deseas colaborar verificando o aprobando parches, necesitas saber cómo aceptar trabajo de otros de la forma más clara para tus contribuyentes y más sostenible para tí a largo plazo.
Trabajando con Ramas Puntuales
Cuando estás pensando en integrar nuevo trabajo, suele ser buena idea utilizar una rama puntual para cada tema concreto --una rama temporal creada específicamente para trabajar dicho tema-- De esta forma, es sencillo tratar cada parche de forma individualizada y poder "aparcar" uno concreto cuando no trabajamos en él, hasta cuando volvamos a tener tiempo para retomarlo. Si creas los nombres de ramas basandolos en el tema sobre el que vas a trabajar, por ejemplo 'ruby client' o algo así de descriptivo, podrás recordar de qué iba cada rama en caso de que la abandones por un tiempo y la retomes más tarde. La persona gestora del proyecto Git suele tender a nombrar cada rama de foma parecida --por ejemplo 'sc/ruby client', donde sc es la abreviatura para la persona que ha contribuido con ese trabajo--. Como recordarás, la forma de crear una rama basandola en tu rama master es:
$ git branch sc/ruby_client master
O, si deseas crearla y saltar inmediatamente a ella, puedes también utilizar la opción '-b' del comando 'checkout':
$ git checkout -b sc/ruby_client master
Tras esto, estarás listo para añadir tu trabajo a esa rama puntual y ver si deseas o no fusionarla luego con alguna otra de tus ramas de más largo recorrido.
Aplicar parches recibidos por correo electronico
Si vas a integrar en tu proyecto un parche recibido a través de un correo electrónico. Antes de poder evaluarlo, tendrás que incorporarlo a una de tus ramas puntuales. Tienes dos caminos para incorporar un parche recibido por correo electronico: usando el comando 'git apply' o usando el comando 'git am'.
Incorporando un parche con apply
Si recibes un parche de alguien que lo ha generado con el comando 'git diff' o con un comando 'diff' de Unix, puedes incorporalo con el comando 'git apply'. Suponiendo que has guardado el parche en '/tmp/patch-ruby-client.patch', puedes incorporarlo con una orden tal como:
$ git apply /tmp/patch-ruby-client.patch
Esto modificará los archivos en tu carpeta de trabajo. Es prácticamente idéntico a lanzar el comando 'patch -p1', aunque es más paranoico y acepta menos coincidencias aproximadas. Además, es capaz de manejar adicciones, borrados o renombrados de archivos, si vienen en formato 'git diff'. Mientras que 'patch' no puede hacerlo. Por ultimo, citar que 'git apply' sigue un modelo de "aplicar todo o abortar todo", incorporando todos los cambios o no incorporando ninguno. Mientras que 'patch' puede incorporar cambios parcialmente, dejando tu carpeta de trabajo en un estado inconsistente. 'git apply' es, de lejos, mucho más paranoico que 'patch'. Nunca creará una confirmación de cambios (commit) por tí, --tras ejecutar el comando, tendrás que preparar (stage) y confirmar (commit) manualmente todos los cambios introducidos--.
Tambien puedes utilizar 'git apply' para comprobar si un parche se puede incorporar limpiamente; antes de intentar incorporarlo. Puedes lanzar el comando 'git apply --check':
$ git apply --check 0001-seeing-if-this-helps-the-gem.patch
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
Si obtienes una salida vacia, el parche se podrá incorporar limpiamente. Además, este comando retorna con un status no-cero en caso de fallar la comprobación, por lo que puedes utilizarlo en scripts si lo deseas.
Incorporando un parche con am
Si la persona que contribuye es usuaria de Git y conoce lo suficiente como para utilizar el comando 'format-patch' al generar su parche, tendrás mucho camino recorrido al incorporarlo; ya que el parche traerá consigo información sobre el o la autora, además de un mensaje de confirmación de cambios. Si puedes, anima a tus colaboradoras a utilizar 'format-patch' en lugar de 'diff' cuando vayan a generar parches. Solo deberías utilizar 'git apply' en caso de parches antiguos y similares.
Para incorporar un parche generado con 'format-patch', utilizarás el comando 'git am'. Técnicamente, 'git am' se construyó para leer un archivo de buzón de correo (mbox file), que no es más que un simple formato de texto plano para almacenar uno o varios mensajes de correo electrónico en un solo archivo de texto. Es algo parecido a esto:
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] add limit to log function
Limit log functionality to the first 20Limit log functionality to the first 20Limit log functionality to the first 20
Esto es el comienzo de la salida del comando format-patch visto en la sección anterior. Es también un formato válido para un mbox. Si alguien te ha enviado correctamente un parche utilizando 'git send-email', y te lo has descargado a un formato mbox; podrás indicar dicho archivo mbox al comando 'git am', y este comenzará a incorporar todos los parches que encuentre dentro. Si tienes un cliente de correo electrónico capaz de guardar varios mensajes en formato mbox, podrás guardar series completas de parches en un mismo archivo; y luego usar 'git am' para irlos incorporando secuencialmente.
Sin embargo, si alguien sube su archivo de parche a un sistema de gestión de peticiones de servicio o similar; tendrás que descargartelo a un archivo local en tu disco y luego indicar ese archivo local al comando 'git am':
$ git am 0001-limit-log-function.patch
Applying: add limit to log function
Observarás que, tras incorporarlo limpiamente, crea automáticamente una nueva confirmación de cambios (commit). La información sobre el autor o autora la recoge de las cabeceras 'From' (Remitente) y 'Date' (Fecha). Y el mensaje para la confirmación (commit) lo recoge de 'Subject' (Asunto) y del cuerpo del correo electrónico. Por ejemplo, si consideramos el parche incorporado desde el mbox del ejemplo que acabamos de mostrar; la confirmación de camios (commit) generada será algo como:
$ git log --pretty=fuller -1
commit 6c5e70b984a60b3cecd395edd5b48a7575bf58e0
Author: Jessica Smith <jessica@example.com>
AuthorDate: Sun Apr 6 10:17:23 2008 -0700
Commit: Scott Chacon <schacon@gmail.com>
CommitDate: Thu Apr 9 09:19:06 2009 -0700
add limit to log function
Limit log functionality to the first 20Limit log functionality to the first 20Limit log functionality to the first 20
El campo 'Commit' muestra la persona que ha incorporado el parche y cuándo lo ha incorporado. El campo 'Author' muestra la persona que ha creado originalmente el parche y cuándo fue creado este.
Pero también podría suceder que el parche no se pudiera incorporar limpiamente. Es posible que tu rama principal diverja demasiado respecto de la rama sobre la que se construyó el parche; o que el parche tenga dependencias respecto de algún otro parche anterior que aún no hayas incorporado. En ese caso, el proceso 'git am' fallará y te preguntará qué deseas hacer:
$ git am 0001-seeing-if-this-helps-the-gem.patch
Applying: seeing if this helps the gem
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
Patch failed at 0001.
When you have resolved this problem run "git am --resolved".
If you would prefer to skip this patch, instead run "git am --skip".
To restore the original branch and stop patching run "git am --abort".
Este comando pondrá marcadores de conflicto en cualquier archivo con problemas, de forma similar a como lo haría una operación de fusión (merge) o de reorganización (rebase). Y resolverás los problemas de la misma manera: editar el archivo para resolver los conflictos, prepararlo (stage), y lanzar 'git am --resolved' para continuar con el siguiente parche:
$ (fix the file)
$ git add ticgit.gemspec
$ git am --resolved
Applying: seeing if this helps the gem
Si deseas más inteligencia por parte de Git al resolver conflictos, puedes pasarle la opción '-3', para que intente una fusión a tres bandas (three-way merge). Esta opción no se usa por defecto, porque no funcionará en caso de que la confirmación de cambios en que el parche dice estar basado no esté presente en tu repositorio. Sin embargo, si tienes dicha confirmación de cambios (commit), --si el parche está basado en una confirmación pública--, entonces la opción '-3' suele ser mucho más avispada cuando incorporas un parche conflictivo:
$ git am -3 0001-seeing-if-this-helps-the-gem.patch
Applying: seeing if this helps the gem
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
Using index info to reconstruct a base tree...
Falling back to patching base and 3-way merge...
No changes -- Patch already applied.
En este caso, estamos intentando incorporar un parche que ya tenemos incorporado. Sin la opción '-3', tendríamos problemas.
Al aplicar varios parches desde un mbox, puedes lanzar el comando 'am' en modo interactivo; haciendo que se detenga en cada parche y preguntandote si aplicarlo o no:
$ git am -3 -i mbox
Commit Body is:
--------------------------
seeing if this helps the gem
--------------------------
Apply? [y]es/[n]o/[e]dit/[v]iew patch/[a]ccept all
Es una utilidad interesante si tienes tienes almacenados unos cuantos parches, porque puedes ir revisando previamente cada parche y aplicarlos selectivamente.
Cuando tengas integrados y confirmados todos los parches relativos al tema puntual en que estas trabajando, puedes plantearte cómo y cuándo lo vas a integar en alguna otra rama de más largo recorrido.
Recuperando ramas remotas
Si recibes una contribución de un usuario que ha preparado su propio repositorio, ha guardado unos cuantos cambios en este, y luego te ha enviado la URL del repositorio y el nombre de la rama remota donde se encuentran los cambios. Puedes añadir dicho repositorio como un remoto y fusionar los cambios localmente.
Por ejemplo, si Jessica te envia un correo electrónico comentandote que tiene una nueva e interesante funcionalidad en la rama 'ruby-client' de su repositorio. Puedes probarla añadiendo el remoto correspondiente y recuperando localmente dicha rama.
$ git remote add jessica git://github.com/jessica/myproject.git
$ git fetch jessica
$ git checkout -b rubyclient jessica/ruby-client
Si más tarde vuelva a enviarte otro correo electronico avisandote de otra gran funcionalidad que ha incorporado, puedes recuperarla (fetch y checkout) directamente, porque tienes el remoto ya definido.
Es muy util cuando trabajas regularmente con una persona. En cambio, si alguien tiene un solo parche para enviarte, una sola vez, puede ser más efectivo aceptarlo directamente por correo electronico; en lugar de pedir a todo el mundo que tenga cada uno su propio servidor y tener nosotros que estar continuamente añadiendo y quitando remotos para cada parche. También es muy posible que no quieras tener cientos de remotos, cada uno contribuyendo tan solo con un parche o dos. De todas formas, los scripts y los servicios albergados pueden hacerte la vida más facil en esto, --todo depende de cómo desarrolles tú y de como desarrollan las personas que colaboran contigo--.
Otra ventaja de esta forma de trabajar es que recibes también el histórico de confirmaciones de cambio (commits). A pesar de poder seguir teniendo los habituales problemas con la fusión, por lo menos conoces en qué punto de tu historial han basado su trabajo. Por defecto, se aplicará una genuina fusión a tres bandas, en lugar de tener que poner un '-3' y esperar que el parche haya sido generado a partir de una confirmación de cambios (commit) pública a la que tengas tú también acceso.
Si no trabajas habitualmente con una persona, pero deseas recuperar de ella por esta vía, puedes indicar directamente el URL del repositorio remoto en el comando 'git pull'. Esto efectua una recuperación (pull) puntual y no conserva la URL como una referencia remota:
$ git pull git://github.com/onetimeguy/project.git
From git://github.com/onetimeguy/project
* branch HEAD -> FETCH_HEAD
Merge made by recursive.
Revisando lo introducido
Ahora que tienes una rama puntual con trabajo aportado por otras personas. Tienes que decidir lo que deseas hacer con él. En esta sección revisaremos un par de comandos, que te ayudarán a ver exactamente los cambios que introducirás si fusionas dicha rama puntual con tu rama principal.
Suele ser util revisar todas las confirmaciones de cambios (commits) que esten es esta rama, pero no en tu rama principal. Puedes excluir de la lista las confirmaciones de tu rama principal añadiendo la opción '--not' delante del nombre de la rama. Por ejemplo, si la persona colaboradora te envia dos parches y tu creas una rama 'contrib' donde aplicar dichos parches; puedes lanzar algo como esto:
$ git log contrib --not master
commit 5b6235bd297351589efc4d73316f0a68d484f118
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Oct 24 09:53:59 2008 -0700
seeing if this helps the gem
commit 7482e0d16d04bea79d0dba8988cc78df655f16a0
Author: Scott Chacon <schacon@gmail.com>
Date: Mon Oct 22 19:38:36 2008 -0700
updated the gemspec to hopefully work better
Para ver en detalle los cambios introducidos por cada confirmación (commit), recuerda que pasando la opción '-p' al comando 'git log', obtendrás un listado extendido con las diferencias introducidas por cada confirmación.
Para ver plenamente todas las diferencias y lo que sucederá realmente si fusionas esta rama puntual con otra rama, tendrás que utilizar un pequeño truco para obtener los resultados correctos. Puedes pensar en lanzar esto:
$ git diff master
Este comando te dará las diferencias, pero puede ser engañoso. Si tu rama 'master' ha avanzado con respecto al momento en que se creó la rama puntual a partir de ella, puedes obtener resultados realmente extraños. Debido a que Git compara directamente las instantáneas de la última confirmación de cambios en la rama puntual donde te encuentras y en la rama 'master'. Por ejemplo, si en la rama 'master' habias añadido una línea a un archivo, la comparación directa de instantáneas te llevará a pensar que la rama puntual va a borrar dicha línea.
Si 'master' es un ancestro directo de tu rama puntual, no tendrás problemas. Pero si los historiales de las dos ramas son divergentes, la comparación directa de diferencias dará la apariencia de estar añadiendo todo el material nuevo en la rama puntual y de estar borrando todo el material nuevo en la rama 'master'.
Y lo que realmente querías ver eran los cambios introducidos por la rama puntual, --el trabajo que vas a introducir si la fusionas con la rama 'master'--. Lo puedes hacer indicando a Git que compare la última confirmación de cambios en la rama puntual, con el más reciente ancestro común que tenga esta respecto de la rama 'master'.
Técnicamente, lo puedes hacer descubriendo tu mismo dicho ancestro común y lanzando la comprobación de diferencias respecto de él:
$ git merge-base contrib master
36c7dba2c95e6bbb78dfa822519ecfec6e1ca649
$ git diff 36c7db
Pero esto no es lo más conveniente. De ahí que Git suministre otro atajo para hacerlo: la sintaxis del triple-punto. Estando en el contexto del comando 'diff', puedes indicar tres puntos entre los nombres de las dos ramas; para comparar entre la última confirmación de cambios de la rama donde estás y la respectiva confirmación común con la otra rama:
$ git diff master...contrib
Este comando mostrará únicamente el trabajo en tu actual rama puntual que haya sido introducido a partir de su ancestro común con la rama 'master'. Es una sintaxis muy util, que merece recordar.
Integrando el trabajo aportado por otros
Cuando todo el trabajo presente en tu rama puntual esté listo para ser integrado en una rama de mayor rango, la cuestión es cómo hacerlo. Yendo aún más lejos, ?cual es el sistema de trabajo que deseas utilizar para el mantenimiento de tu proyecto? Tienes bastantes opciones, y vamos a ver algunas de ellas.
Fusionando flujos de trabajo
Una forma simple de trabajar es fusionandolo todo en tu rama 'master'. En este escenario, tienes una rama 'master' que contiene, principalmente, código estable. Cuando en una rama puntual tienes trabajo ya terminado o contribuciones ya verificadas de terceros, los fusionas en tu rama 'master', borras la rama puntual, y continuas trabajando en otra/s rama/s. Si, tal y como se muestra en la Figura 5-19, tenemos un repositorio con trabajos en dos ramas, denominadas 'ruby client' y 'php client'; y fusionamos primero la rama 'ruby client' y luego la 'php client', obtendremos un historial similar al de la Figura 5-20.
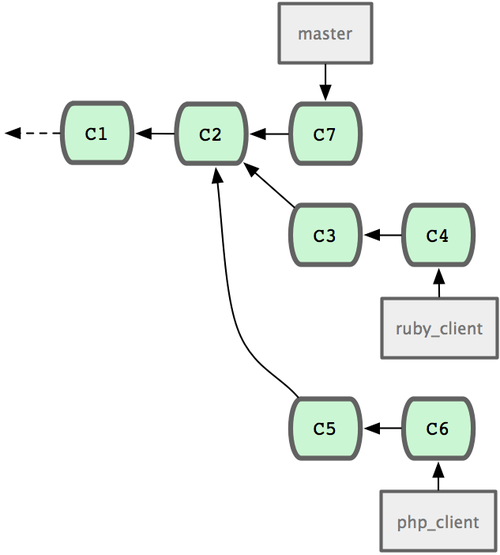
Figura 5-19. Historial con varias ramas puntuales.
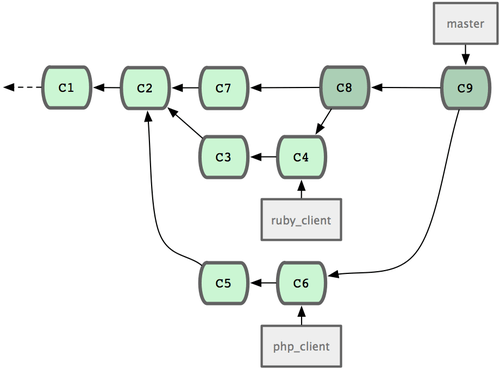
Figura 5-20. Tras fusionar una rama puntual.
Este es probablemente el flujo de trabajo más sencillo. Pero puede dar problemas cuando estás tratando con grandes repositorios o grandes proyectos.
Teniendo muchos desarrolladores o proyectos muy grandes, muy posiblemente desees utilizar un ciclo con por lo menos dos fases. En este escenario, se dispone de dos ramas de largo recorrido: 'master' y 'develop'. La primera de ellas, 'master', será actualizada únicamente por los lanzamientos de código muy estable. La segunda rama, 'develop', es donde iremos integrando todo el código nuevo. Ambas ramas se enviarán periodicamente al repositorio público. Cada vez que tengas una nueva rama puntual lista para integrar (Figura 5-21), la fusionarás en la rama 'develop'. Y cuando marques el lanzamiento de una versión estable, avanzarás la rama 'master' hasta el punto donde la rama 'develop' se encuentre en ese momento (Figura 5-23).
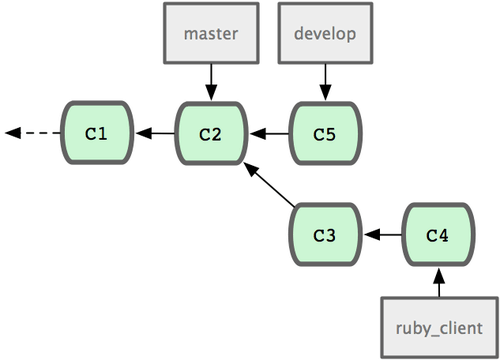
Figura 5-21. Antes de fusionar una rama puntual.
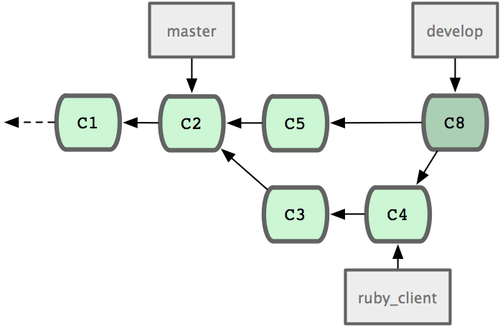
Figura 5-22. Tras fusionar una rama puntual.
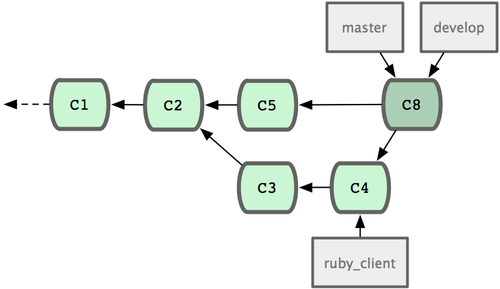
Figura 5-23. Tras un lanzamiento puntual.
De esta forma, cuando alguien clone el repositorio de tu proyecto, podrá recuperar (checkout) y mantener actualizadas tanto la última version estable como la versión con el material más avanzado; en las ramas 'master' y 'develop', respectivamente. Puedes continuar ampliando este concepto, disponiendo de una rama 'integrate' donde ir fusionando todo el trabajo entre sí. A continuación, cuando el código en dicha rama sea estable y pase todas las pruebas, la fusionarás con la rama 'develop'; y, cuando se demuestre que permanece estable durante un cierto tiempo, avanzarás la rama 'master' hasta ahí.
Flujos de trabajo con grandes fusiones
El proyecto Git tiene cuatro ramas de largo recorrido: 'master', 'next', 'pu' (proposed updates) para el trabajo nuevo, y 'maint' (maintenance) para trabajos de mantenimiento de versiones previas. A medida que vamos introduciendo nuevos trabajos de las personas colaboradoras, estos se van recolectando en ramas puntuales en el repositorio de una persona gestora; de forma similar a como se ha ido describiendo (ver Figura 5-24). En un momento dado, las funcionalidades introducidas se evaluan; comprobando si son seguras y si están preparadas para los consumidores; o si, por el contrario, necesitan dedicarles más trabajo. Las funcionalidades que resultan ser seguras y estar preparadas se fusionan (merge) en la rama 'next'; y esta es enviada (push) al repositorio público, para que cualquiera pueda probarlas.
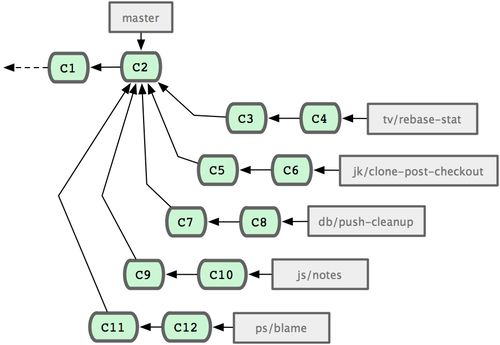
Figura 5-24. Gestionando complejas series de ramas puntuales paralelas con funcionalidades varias.
Si las funcionalidades necesitan ser más trabajadas, se fusionan (merge) en la rama 'pu'. Y cuando las funcionalidades permanecen totalmente estables, se refusionan en la rama 'master'; componiendolas desde las funcionalidades en la rama 'next' aún sin promocionar a 'master'. Esto significa que 'master' prácticamente siempre avanza; 'next' se reorganiza (rebase) de vez en cuando; y 'pu' es reorganizada con más frecuencia (ver Figura 5-25).
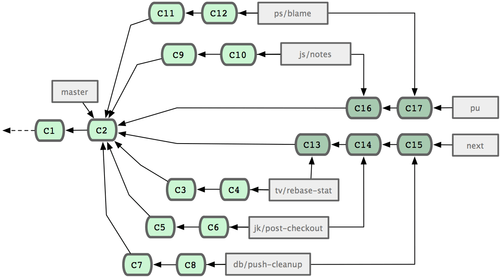
Figura 5-25. Fusionando aportaciones de ramas puntuales en ramas de más largo recorrido.
Una rama puntual se borra del repositorio cuando, finalmente, es fusionada en la rama 'master'. El proyecto Git dispone también de una rama 'maint' que se bifurca (fork) a partir de la última versión ya lanzada; para trabajar en parches, en caso de necesitarse alguna versión intermedia de mantenimiento. Así, cuando clonas el repositorio de Git, obtienes cuatro ramas que puedes recuperar (checkout); pudiendo evaluar el proyecto en distintos estadios de desarrollo, dependiendo de cuán avanzado desees estar o cómo desees contribuir. Y así, los gestores de mantenimiento disponen de un flujo de trabajo estructurado, para ayudarles en el procesado e incorporación de nuevas contribuciones.
Flujos de trabajo reorganizando o entresacando
Otros gestores de mantenimiento, al procesar el trabajo recibido de las personas colaboradoras, en lugar de fusiones (merge), suelen preferir reorganizar (rebase) o entresacar (cherry-pick) sobre su propia rama principal; obteniendo así un historial prácticamente lineal. Cuando desees integrar el trabajo que tienes en una rama puntual, te puedes situar sobre ella y lanzar el comando 'rebase'; de esta forma recompondrás los cambios encima de tu actual rama 'master' (o 'develop' o lo que corresponda). Si funciona, se realizará un avance rápido (fast-forward) en tu rama 'master', y acabarás teniendo un historial lineal en tu proyecto.
El otro camino para introducir trabajo de una rama en otra, es entresacarlo. Entresacar (cherry-pick) en Git es como reorganizar (rebase) una sola confirmación de cambios (commit). Se trata de coger el parche introducido por una determinada confirmación de cambios e intentar reaplicarlo sobre la rama donde te encuentres en ese momento. Puede ser util si tienes varias confirmaciones de cambios en una rama puntual, y tan solo deseas integar una de ellas; o si tienes una única confirmación de cambios en una rama puntual, y prefieres entresacarla en lugar de reorganizar. Por ejemplo, suponiendo que tienes un proyecto parecido al ilustrado en la Figura 5-26.
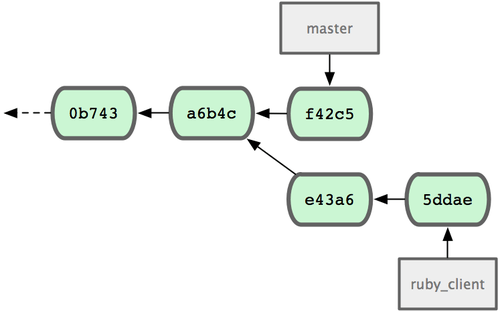
Figura 5-26. Historial de ejemplo, antes de entresacar.
Si deseas integar únicamente la confirmación 'e43a6' en tu rama 'master', puedes lanzar:
$ git cherry-pick e43a6fd3e94888d76779ad79fb568ed180e5fcdf
Finished one cherry-pick.
[master]: created a0a41a9: "More friendly message when locking the index fails."
3 files changed, 17 insertions(+), 3 deletions(-)
Esto introduce exactamente el mismo cambio introducido por 'e43a6', pero con un nuevo valor SHA-1 de confirmación; ya que es diferente la fecha en que ha sido aplicado. Tu historial quedará tal como ilustra la Figura 5-27.
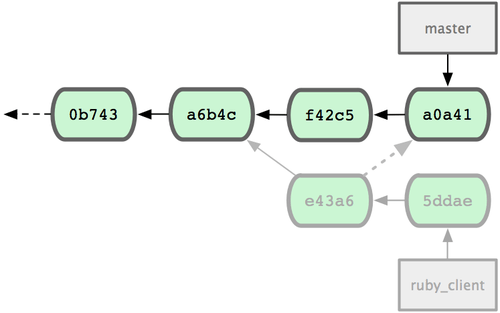
Figura 5-27. Historial tras entresacar una confirmación de cambios de una rama puntual.
Ahora, ya puedes borrar la rama puntual y descartar las confirmaciones de cambios que no deseas integrar.
Marcando tus lanzamientos de versiones
Cuando decides dar por preparada una versión, probablemente querrás etiquetar dicho punto de algún modo; de tal forma que, más adelante, puedas volver a generar esa versión en cualquier momento. Puedes crear una nueva etiqueta tal y como se ha comentado en el capítulo 2. Si decides firmar la etiqueta como gestor de mantenimientos que eres, el proceso será algo como:
$ git tag -s v1.5 -m 'my signed 1.5 tag'
You need a passphrase to unlock the secret key for
user: "Scott Chacon <schacon@gmail.com>"
1024-bit DSA key, ID F721C45A, created 2009-02-09
Si firmas tus etiquetas, puedes tener un problema a la hora de distribuir la clave PGP pública utilizada en la firma. Los gestores del proyeto Git ha resuelto este problema incluyendo sus claves públicas como un objeto en el repositorio, añadiendo luego una etiqueta apuntando directamente a dicho contenido. Para ello, has de seleccionar cada clave que deseas incluir, lanzando el comando 'gpg ---list-keys':
$ gpg --list-keys
/Users/schacon/.gnupg/pubring.gpg
---------------------------------
pub 1024D/F721C45A 2009-02-09 [expires: 2010-02-09]
uid Scott Chacon <schacon@gmail.com>
sub 2048g/45D02282 2009-02-09 [expires: 2010-02-09]
Tras esto, puedes importar directamente la clave en la base de datos Git, exportandola y redirigiendola a través del comando 'git hash-object'. Para, de esta forma, escribir un nuevo objeto dentro de Git y obtener de vuelta la firma SHA-1 de dicho objeto.
$ gpg -a --export F721C45A | git hash-object -w --stdin
659ef797d181633c87ec71ac3f9ba29fe5775b92
Una vez tengas el contenido de tu clave guardado en Git, puedes crear una etiquta que apunte directamente al mismo; indicando para ello el nuevo valor SHA-1 que te ha devuelto el objeto 'hash-object':
$ git tag -a maintainer-pgp-pub 659ef797d181633c87ec71ac3f9ba29fe5775b92
Si lanzas el comando 'git push --tags', la etiqueta 'maintainer-pgp-pub' será compartida por todos. Cualquiera que desee verificar la autenticidad de una etiqueta, no tiene más que importar tu clave PGP, sacando el objecto directamente de la base de datos e importandolo en GPG:,
$ git show maintainer-pgp-pub | gpg --import
De esta forma, pueden utilizar esa clave para verificar todas las etiquetas que firmes. Además, si incluyes instrucciones en el mensaje de etiquetado, con el comando git show <tag>, los usuarios podrán tener directrices específicas acerca de la verificación de etiquetas.
Generando un número de ensamblado
Debido a que Git no dispone de una serie monótona ascendente de números para cada confirmación de cambios (commit), si deseas tener un nombre humanamente comprensible por cada confirmación, has de utilizar el comando 'git describe'. Git te dará el nombre de la etiqueta más cercana, mas el número de confirmaciones de cambios entre dicha etiqueta y la confirmación que estas describiendo, más una parte de la firma SHA-1 de la confirmación:
$ git describe master
v1.6.2-rc1-20-g8c5b85c
De esta forma, puedes exportar una instantánea u obtener un nombre comprensible por cualquier persona. Es más, si compilas Git desde código fuente clonado desde el repositorio Git, el comando 'git --version' te dará algo parecido. Si solicitas descripción de una confirmación de cambios (commit) etiquetada directamente con su propia etiqueta particular, obtendrás dicha etiqueta como descripción.
El comando 'git describe' da preferencia a las etiquetas anotativas (etiquetas creadas con las opciones '-a' o '-s'). De esta forma las etiquetas para las versiones pueden ser creadas usando 'git describe', asegurandose el que las confirmaciones de cambios (commit) son adecuadamente nombradas cuando se describen. Tambien puedes utilizar esta descripción para indicar lo que deseas activar (checkout) o mostrar (show); pero realmente estarás usando solamente la parte final de la firma SHA-1 abreviada, por lo que no siempre será válida. Por ejemplo, el kernel de Linux ha saltado recientemente de 8 a 10 caracteres, para asegurar la unicidad de los objetos SHA-1; dando como resultado que los nombres antiguos de 'git describe' han dejado de ser válidos.
Preparando un lanzamiento de versión
Si quieres lanzar una nueva versión. Una de las cosas que desearas crear es un archivo con la más reciente imagen de tu código, para aquellas pobres almas que no utilizan Git. El comando para hacerlo es 'git archive':
$ git archive master --prefix='project/' | gzip > `git describe master`.tar.gz
$ ls *.tar.gz
v1.6.2-rc1-20-g8c5b85c.tar.gz
Quien abra ese archivo tarball, obtendrá la más reciente imagen de tu proyecto; puesta bajo una carpeta de proyecto. También puedes crear un archivo zip de la misma manera, tan solo indicando la opción '--format=zip' al comando 'git archive':
$ git archive master --prefix='project/' --format=zip > `git describe master`.zip
Así, tendrás sendos archivos tarball y zip con tu nueva versión, listos para subirlos a tu sitio web o para ser enviados por correo electrónico a tus usuarios.
El registro rápido
Ya va siendo hora de enviar un mensaje a tu lista de correo, informando a las personas que desean conocer la marcha de tu proyecto. Una manera elegante de generar rápidamente una lista con los principales cambios añadidos a tu proyecto desde la anterior versión, es utilizando el comando 'git shortlog'. Este comando resume todas las confirmaciones de cambios (commits) en el rango que le indiques. Por ejemplo, si tu último lanzamiento de versión lo fué de la v1.0.1:
$ git shortlog --no-merges master --not v1.0.1
Chris Wanstrath (8):
Add support for annotated tags to Grit::Tag
Add packed-refs annotated tag support.
Add Grit::Commit#to_patch
Update version and History.txt
Remove stray `puts`
Make ls_tree ignore nils
Tom Preston-Werner (4):
fix dates in history
dynamic version method
Version bump to 1.0.2
Regenerated gemspec for version 1.0.2
Obtendrás un claro resumen de todas las confirmaciones de cambios (commit) desde la versión v1.0.1, agrupadas por autor, y listas para ser incorporadas en un mensaje a tu lista de correo.