Ce qu'est une branche
Pour réellement comprendre comment Git gère les branches, nous devons revenir en arrière et examiner de plus près comment Git stocke ses données. Comme vous pouvez vous en souvenir du chapitre 1, Git ne stocke pas ses données comme une série d'ensembles de modifications ou différences, mais comme une série d'instantanés.
Lorsqu'on valide dans Git, Git stocke un objet commit qui contient un pointeur vers l'instantané du contenu qui a été indexé, les méta-données d'auteur et de message et zéro ou plusieurs pointeurs vers le ou les commits qui sont les parents directs de ce commit : zéro parent pour la première validation, un parent pour un commit normal et des parents multiples pour des commits qui sont le résultat de la fusion d'une ou plusieurs branches.
Pour visualiser ce concept, supposons un répertoire contenant trois fichiers, ces trois fichiers étant indexés puis validés. Indexer les fichiers signifie calculer la somme de contrôle pour chacun (la fonction de hachage SHA-1 mentionnée au chapitre 1), stocker cette version du fichier dans le dépôt Git (Git les nomme blobs) et ajouter la somme de contrôle à la zone d'index :
$ git add LISEZMOI test.rb LICENCE
$ git commit -m 'commit initial de mon projet'
Lorsque vous créez le commit en lançant la commande git commit, Git calcule la somme de contrôle de chaque répertoire (ici, seulement pour le répertoire racine) et stocke ces objets arbres dans le dépôt Git.
Git crée alors un objet commit qui contient les méta-données et un pointeur vers l'arbre projet d'origine de manière à pouvoir recréer l'instantané si besoin.
Votre dépôt Git contient à présent cinq objets : un blob pour le contenu de chacun des trois fichiers, un arbre qui liste le contenu du répertoire et spécifie quels noms de fichiers sont attachés à quels blobs et un objet commit avec le pointeur vers l'arbre d'origine et toutes les méta-données attachées au commit. Conceptuellement, les données contenues dans votre dépôt Git ressemblent à la figure 3-1.
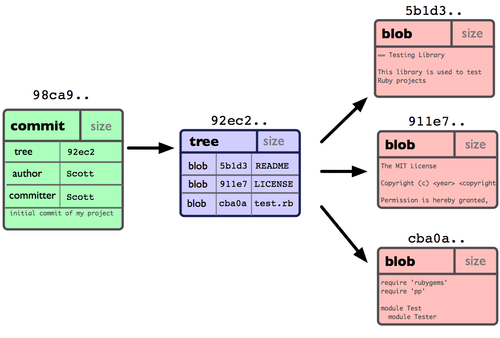
Figure 3-1. Données d'un commit unique.
Si vous réalisez des modifications et validez à nouveau, le prochain commit stocke un pointeur vers le commit immédiatement précédent. Après deux autres validations, l'historique pourrait ressembler à la figure 3-2.
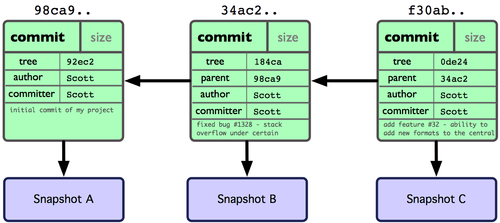
Figure 3-2. Données et objets Git pour des validations multiples.
Une branche dans Git est tout simplement un pointeur mobile léger vers un de ces objets commit.
La branche par défaut dans Git s'appelle master.
Au fur et à mesure des validations, la branche master pointe vers le dernier des commits réalisés.
À chaque validation, le pointeur de la branche master avance automatiquement.
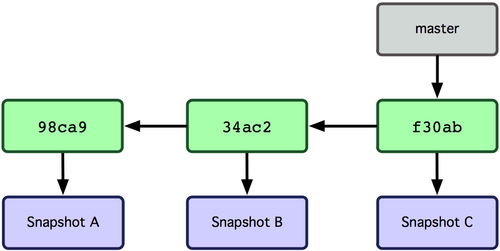
Figure 3-3. Branche pointant dans l'historique des données de commit.
Que se passe-t-il si vous créez une nouvelle branche ?
Et bien, cela crée un nouveau pointeur à déplacer.
Supposons que vous créez une nouvelle branche nommée test.
Vous utilisez la commande git branch :
$ git branch test
Cela crée un nouveau pointeur vers le commit actuel (cf. figure 3-4).
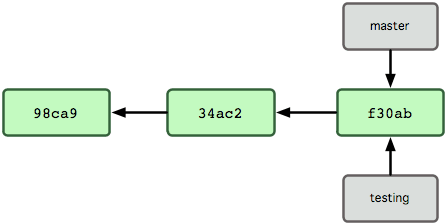
Figure 3-4. Branches multiples pointant dans l'historique des données de commit.
Comment Git connaît-il la branche sur laquelle vous vous trouvez ?
Il conserve un pointeur spécial appelé HEAD.
Remarquez que sous cette appellation se cache un concept très différent de celui utilisé dans les autres VCS tels que Subversion ou CVS.
Dans Git, c'est un pointeur sur la branche locale où vous vous trouvez.
Dans notre cas, vous vous trouvez toujours sur master.
La commande git branch n'a fait que créer une nouvelle branche — elle n'a pas fait basculer la copie de travail vers cette branche (cf. figure 3-5).
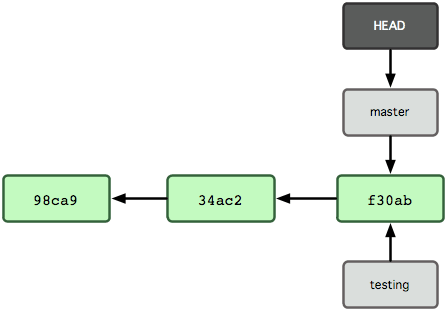
Figure 3-5. fichier HEAD pointant sur la branche active.
Pour basculer vers une branche existante, il suffit de lancer la commande git checkout.
Basculons vers la nouvelle branche test :
$ git checkout test
Cela déplace HEAD pour le faire pointer vers la branche test (voir figure 3-6).
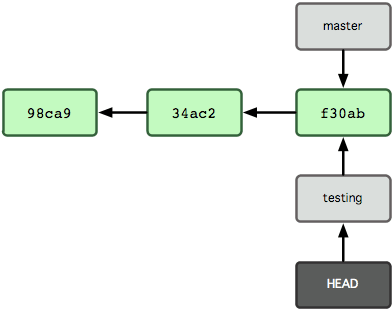
Figure 3-6. HEAD pointe vers une autre branche quand on bascule entre les branches.
Qu'est-ce que cela signifie ? Et bien, faisons une autre validation :
$ vim test.rb
$ git commit -a -m 'petite modification'
La figure 3-7 illustre le résultat.
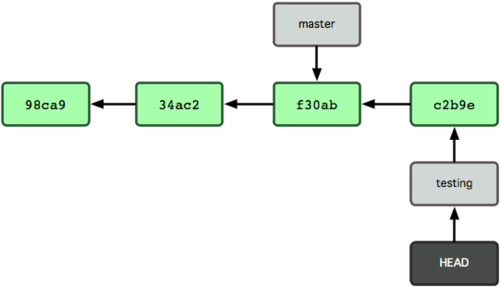
Figure 3-7. La branche sur laquelle HEAD pointe avance avec chaque nouveau commit.
C'est intéressant parce qu'à présent, votre branche test a avancé, tandis que la branche master pointe toujours sur le commit sur lequel vous étiez lorsque vous avez lancé git checkout pour basculer de branche.
Retournons sur la branche master :
$ git checkout master
La figure 3-8 montre le résultat.
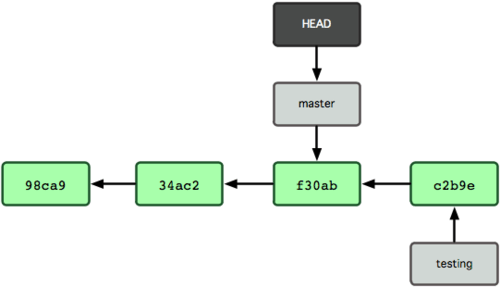
Figure 3-8. HEAD se déplace sur une autre branche lors d'un checkout.
Cette commande a réalisé deux actions.
Elle a remis le pointeur HEAD sur la branche master et elle a replacé les fichiers de la copie de travail dans l'état pointé par master.
Cela signifie aussi que les modifications que vous réalisez à partir de maintenant divergeront de l'ancienne version du projet.
Cette commande retire les modifications réalisées dans la branche test pour vous permettre de repartir dans une autre direction de développement.
Réalisons quelques autres modifications et validons à nouveau :
$ vim test.rb
$ git commit -a -m 'autres modifications'
Maintenant, l'historique du projet a divergé (voir figure 3-9).
Vous avez créé une branche et basculé dessus, avez réalisé des modifications, puis avez rebasculé sur la branche principale et réalisé d'autres modifications.
Ces deux modifications sont isolées dans des branches séparées.
Vous pouvez basculer d'une branche à l'autre et les fusionner quand vous êtes prêt.
Vous avez fait tout ceci avec de simples commandes branch et checkout.
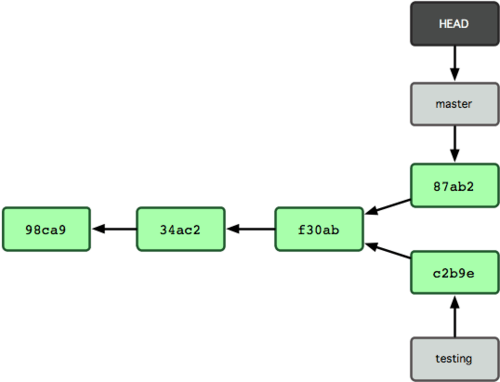
Figure 3-9. Les historiques de branche ont divergé.
Parce que dans Git, une branche n'est en fait qu'un simple fichier contenant les 40 caractères de la somme de contrôle SHA-1 du commit sur lequel elle pointe, les branches ne coûtent rien à créer et détruire. Créer une branche est aussi rapide qu'écrire un fichier de 41 caractères (40 caractères plus un retour chariot).
C'est une différence de taille avec la manière dont la plupart des VCS gèrent les branches, qui implique de copier tous les fichiers du projet dans un second répertoire. Cela peut durer plusieurs secondes ou même quelques minutes selon la taille du projet, alors que pour Git, le processus est toujours instantané. De plus, comme nous enregistrons les parents quand nous validons les modifications, la détermination de l'ancêtre commun pour la fusion est réalisée automatiquement et de manière très facile. Ces fonctionnalités encouragent naturellement les développeurs à créer et utiliser souvent des branches.
Voyons pourquoi vous devriez en faire autant.