Les objets Git
Git est un système de fichier adressables par contenu.
Super !
Mais qu'est-ce que ça veut dire ?
Ça veut dire que le cœur de Git est une simple base de paires clé/valeur.
Vous pouvez y insérer n'importe quelle sorte de données et il vous retournera une clé que vous pourrez utiliser à n'importe quel moment pour récupérer ces données.
Pour illustrer cela, vous pouvez utiliser la commande de plomberie hash-object, qui prend des données, les stocke dans votre répertoire .git, puis retourne la clé sous laquelle les données sont stockées.
Tout d'abord, créez un nouveau dépôt Git et vérifiez que rien ne se trouve dans le répertoire object :
$ mkdir test
$ cd test
$ git init
Initialized empty Git repository in /tmp/test/.git/
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type f
$
Git a initialisé le répertoire objects et y a créé les sous-répertoires pack et info, mais ils ne contiennent pas de fichier régulier.
Maintenant, stockez du texte dans votre base de données Git :
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
L'option -w spécifie à hash-object de stocker l'objet, sinon la commande répondrait seulement quelle serait la clé.
--stdin spécifie à la commande de lire le contenu depuis l'entrée standard, sinon hash-object s'attend à trouver un chemin vers un fichier.
La sortie de la commande est une empreinte de 40 caractères.
C'est l'empreinte SHA-1 : une somme de contrôle du contenu du fichier que vous stockez plus un en-tête, dont les détails sont un peu plus bas.
Voyez maintenant comment Git a stocké vos données :
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
Vous pouvez voir un fichier dans le répertoire objects.
C'est comme cela que Git stocke initialement du contenu : un fichier par contenu, nommé d'après la somme de contrôle SHA-1 du contenu et de son en-tête.
Le sous-répertoire est nommé d'après les 2 premiers caractères de l'empreinte et le fichier d'après les 38 caractères restants.
Vous pouvez récupérer le contenu avec la commande cat-file.
Cette commande est un peu le couteau suisse pour l'inspection des objets Git.
Utiliser l'option -p avec cat-file vous permet de connaître le type de contenu et de l'afficher clairement :
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content
Vous pouvez maintenant ajouter du contenu à Git et le récupérer. Vous pouvez aussi faire ceci avec des fichiers. Par exemple, vous pouvez mettre en œuvre une gestion de version simple d'un fichier. D'abord, créez un nouveau fichier et enregistrez son contenu dans la base de données :
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30
Puis, modifiez le contenu du fichier et enregistrez-le à nouveau :
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
Votre base de données contient les 2 versions du fichier, ainsi que le premier contenu que vous avez stocké ici :
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
Vous pouvez restaurer le fichier à sa première version :
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1
ou à sa seconde version :
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2
Se souvenir de la clé SHA-1 de chaque version de votre fichier n'est pas pratique.
En plus, vous ne stockez pas le fichier lui-même, mais seulement son contenu, dans votre base.
Ce type d'objet est appelé un blob (Binary Large OBject, soit en français : Gros Objet Binaire).
Git peut vous donner le type d'objet de n'importe quel objet Git, étant donné sa clé SHA-1, avec cat-file -t :
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blob
Objets arbre
Le prochain type que vous allez étudier est l'objet arbre (tree) qui résout le problème de stockage d'un groupe de fichiers. Git stocke du contenu de la même manière, mais plus simplement, qu'un système de fichier UNIX. Tout le contenu est stocké comme des objets de type arbre ou blob : un arbre correspondant à un répertoire UNIX et un blob correspond à peu près à un i-nœud ou au contenu d'un fichier. Un unique arbre contient une ou plusieurs entrées de type arbre, chacune incluant un pointeur SHA-1 vers un blob, un sous-arbre (sub-tree), ainsi que les droits d'accès (mode), le type et le nom de fichier. L'arbre le plus récent du projet simplegit pourrait ressembler, par exemple à ceci :
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 lib
La syntaxe master^{tree} signifie l'objet arbre qui est pointé par le dernier commit de la branche master.
Remarquez que le sous-répertoire lib n'est pas un blob, mais un pointeur vers un autre arbre :
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb
Conceptuellement, les données que Git stocke ressemblent à la figure 9-1.
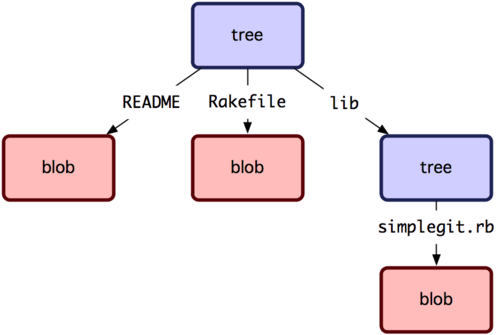
Figure 9-1. Une version simple du modèle de données Git.
Vous pouvez créer votre propre arbre.
Git crée habituellement un arbre à partir de l'état de la zone d'attente ou de l'index.
Pour créer un objet arbre, vous devez donc d'abord mettre en place un index en mettant quelques fichiers en attente.
Pour créer un index contenant une entrée, la première version de votre fichier test.txt par exemple, utilisons la commande de plomberie update-index.
Vous pouvez utiliser cette commande pour ajouter artificiellement une version plus ancienne à une nouvelle zone d'attente.
Vous devez utiliser les options --add car le fichier n'existe pas encore dans votre zone d'attente (vous n'avez même pas encore mis en place une zone d'attente) et --cacheinfo car le fichier que vous ajoutez n'est pas dans votre répertoire, mais dans la base de données.
Vous pouvez ensuite préciser le mode, SHA-1 et le nom de fichier :
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txt
Dans ce cas, vous précisez le mode 100644, qui signifie que c'est un fichier normal.
Les alternatives sont 100755, qui signifie que c'est un exécutable et 120000, qui précise que c'est un lien symbolique.
Le concept de « mode » a été repris des mode UNIX, mais est beaucoup moins flexible : ces trois modes sont les seuls valides pour Git, pour les fichiers (blobs) (bien que d'autres modes soient utilisés pour les répertoires et sous-modules).
Vous pouvez maintenant utiliser la commande write-tree pour écrire la zone d'attente dans un objet arbre.
L'option' -w est inutile (appeler write-tree crée automatiquement un objet arbre à partir de l'état de l'index si cet arbre n'existe pas) :
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
Vous pouvez également vérifier que c'est un objet arbre :
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree
Vous allez créer maintenant un nouvel arbre avec la seconde version de test.txt et un nouveau fichier :
$ echo 'new file' > new.txt
$ git update-index test.txt
$ git update-index --add new.txt
Votre zone d'attente contient maintenant la nouvelle version de test.txt ainsi qu'un nouveau fichier new.txt.
Enregistrez cet arbre (c'est-à-dire enregistrez l'état de la zone d'attente ou de l'index dans un objet arbre) :
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
Remarquez que cet arbre contient des entrées pour les deux fichiers et que l'empreinte SHA de test.txt est l'empreinte de la « version 2 » de tout à l'heure (1f7a7a).
Pour le plaisir, ajoutez le premier arbre à celui-ci, en tant que sous-répertoire.
Vous pouvez maintenant récupérer un arbre de votre zone d'attente en exécutant read-tree.
Dans ce cas, vous pouvez récupérer un arbre existant dans votre zone d'attente comme étant un sous-arbre en utilisant l'option --prefix de read-tree :
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
Si vous créez un répertoire de travail à partir du nouvel arbre que vous venez d'enregistrer, vous aurez deux fichiers à la racine du répertoire de travail, ainsi qu'un sous-répertoire appelé bak qui contient la première version du fichier test.txt.
Vous pouvez vous représenter les données que Git utilise pour ces structures comme sur la figure 9-2.
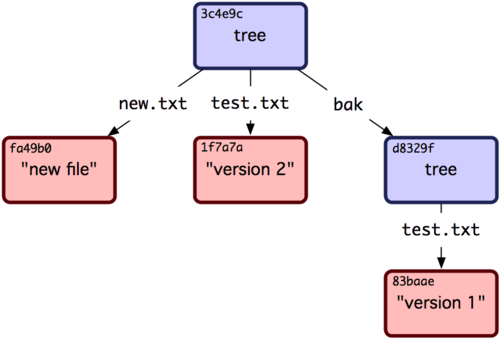
Figure 9-2. Structure du contenu de vos données Git actuelles.
Objets Commit
Vous avez trois arbres qui définissent différents instantanés du projet que vous suivez, mais certains problèmes persistent : vous devez vous souvenir des valeurs des trois empreintes SHA-1 pour accéder aux instantanés. Vous n'avez pas non plus d'information sur qui a enregistré les instantanés, quand et pourquoi. Ce sont les informations élémentaires qu'un objet commit stocke pour vous.
Pour créer un objet commit, il suffit d'exécuter commit-tree, de préciser l'empreinte SHA-1 et quel objet commit, s'il y en a, le précède directement.
Commencez avec le premier arbre que vous avez créé :
$ echo 'first commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Vous pouvez voir votre nouvel objet commit avec cat-file :
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
first commit
Le format d'un commit est simple : il contient l'arbre racine de l'instantané du projet à ce moment, les informations sur l'auteur et le validateur qui sont extraites des variables de configuration user.name et user.email accompagnées d'un horodatage, une ligne vide et le message de validation.
Ensuite, vous enregistrez les deux autres objets commit, chacun référençant le commit dont il est issu :
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9
Chacun des trois objets commit pointe sur un arbre de l'instantané que vous avez créé.
Curieusement, vous disposez maintenant d'un historique Git complet que vous pouvez visualiser avec la commande git log, si vous la lancez sur le SHA-1 du dernier commit :
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletions(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
Fantastique.
Vous venez d'effectuer les opérations bas niveau pour construire un historique Git sans avoir utilisé aucune des commandes haut niveau.
C'est l'essence de ce que fait Git quand vous exécutez les commandes git add et git commit.
Il stocke les blobs correspondant aux fichiers modifiés, met à jour l'index, écrit les arbres et ajoute les objets commit qui référencent les arbres racines venant juste avant eux.
Ces trois objets principaux (le blob, l'arbre et le commit) sont initialement stockés dans des fichiers séparés du répertoire .git/objects.
Voici tous les objets contenus dans le répertoire exemple, commentés d'après leur contenu :
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1
Si vous suivez les pointeurs internes de ces objets, vous obtenez un graphe comme celui de la figure 9-3.
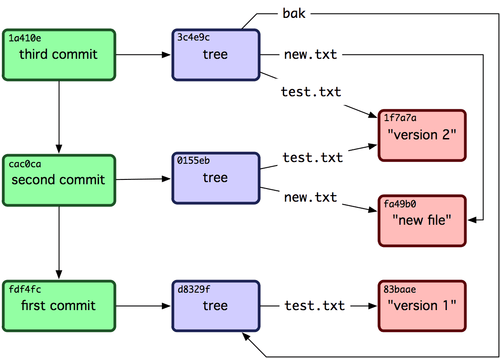
Figure 9-3. Tous les objets de votre répertoire Git.
Stockage des objets
On a parlé plus tôt de l'en-tête présent avec le contenu.
Prenons un moment pour étudier la façon dont Git stocke les objets.
On verra comment stocker interactivement un objet Blob (ici, la chaîne « what is up, doc? ») avec le langage Ruby.
Vous pouvez démarrer Ruby en mode interactif avec la commande irb :
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"
Git construit un en-tête qui commence avec le type de l'objet, ici un blob. Ensuite, il ajoute un espace suivi de taille du contenu et enfin un octet nul :
>> header = "blob #{content.length}\0"
=> "blob 16\000"
Git concatène l'en-tête avec le contenu original et calcule l'empreinte SHA-1 du nouveau contenu.
En Ruby, vous pouvez calculer l'empreinte SHA-1 d'une chaîne, en incluant la bibliothèque « digest/SHA-1 » via la commande require, puis en appelant Digest::SHA1.hexdigest() sur la chaîne :
>> store = header + content
=> "blob 16\000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"
Git compresse le nouveau contenu avec zlib, ce que vous pouvez faire avec la bibliothèque zlib de Ruby.
Vous devez inclure la bibliothèque et exécuter Zlib::Deflate.deflate() sur le contenu :
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\234K\312\311OR04c(\317H,Q\310,V(-\320QH\311O\266\a\000_\034\a\235"
Finalement, vous enregistrerez le contenu compressé dans un objet sur le disque.
Vous déterminerez le chemin de l'objet que vous voulez enregistrer (les deux premiers caractères de l'empreinte SHA-1 formeront le nom du sous-répertoire et les 38 derniers formeront le nom du fichier dans ce répertoire).
En Ruby, on peut utiliser la fonction FileUtils.mkdir_p() pour créer un sous-répertoire s'il n'existe pas.
Ensuite, ouvrez le fichier avec File.open() et enregistrez le contenu compressé en appelant la fonction write() sur la référence du fichier :
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32
C'est tout ! Vous venez juste de créer un objet Blob valide. Tout les objets Git sont stockés de la même façon, mais avec des types différents : l'en-tête commencera par « commit » ou « tree » au lieu de la chaîne « blob ». Bien que le contenu d'un blob puisse être presque n'importe quoi, le contenu d'un commit ou d'un arbre est formaté d'une façon particulière.