Enregistrer des modifications dans le dépôt
Vous avez à présent un dépôt Git valide et une extraction ou copie de travail du projet. Vous devez faire quelques modifications et valider des instantanés de ces modifications dans votre dépôt chaque fois que votre projet atteint un état que vous souhaitez enregistrer.
Souvenez-vous que chaque fichier de votre copie de travail peut avoir deux états : sous suivi de version ou non suivi. Les fichiers suivis sont les fichiers qui appartenaient déjà au dernier instantané ; ils peuvent être inchangés, modifiés ou indexés. Tous les autres fichiers sont non suivis — tout fichier de votre copie de travail qui n'appartenait pas à votre dernier instantané et n'a pas été indexé. Quand vous clonez un dépôt pour la première fois, tous les fichiers seront sous suivi de version et inchangés car vous venez tout juste de les enregistrer sans les avoir encore édités.
Au fur et à mesure que vous éditez des fichiers, Git les considère comme modifiés, car vous les avez modifiés depuis le dernier instantané. Vous indexez ces fichiers modifiés et vous enregistrez toutes les modifications indexées, puis ce cycle se répète. Ce cycle de vie est illustré par la figure 2-1.
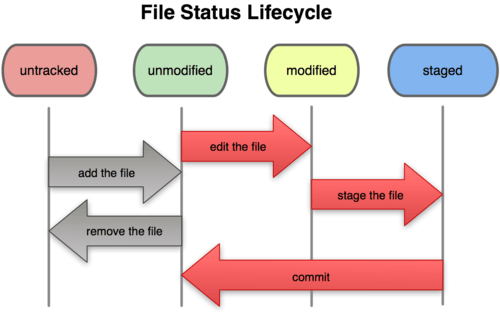
Figure 2-1. Le cycle de vie des états des fichiers.
Vérifier l'état des fichiers
L'outil principal pour déterminer quels fichiers sont dans quel état est la commande git status.
Si vous lancez cette commande juste après un clonage, vous devriez voir ce qui suit :
$ git status
# On branch master
nothing to commit (working directory clean)
Ce message signifie que votre copie de travail est propre, en d'autres mots, aucun fichier suivi n'a été modifié. Git ne voit pas non plus de fichiers non-suivis, sinon ils seraient listés ici. Enfin, la commande vous indique sur quelle branche vous êtes. Pour l'instant, c'est toujours master, qui correspond à la valeur par défaut ; nous ne nous en soucierons pas maintenant. Dans le chapitre suivant, nous parlerons plus en détail des branches et des références.
Supposons que vous ajoutiez un nouveau fichier à votre projet, un simple fichier LISEZMOI.
Si ce fichier n'existait pas auparavant, et que vous lancez la commande git status, vous verrez votre fichier non suivi comme ceci :
$ vim LISEZMOI
$ git status
# On branch master
# Untracked files:
# (use "git add <file>..." to include in what will be committed)
#
# LISEZMOI
nothing added to commit but untracked files present (use "git add" to track)
Vous pouvez constater que votre nouveau fichier LISEZMOI n'est pas en suivi de version, car il apparaît dans la section « Untracked files » de l'état de la copie de travail.
« Untracked » signifie simplement que Git détecte un fichier qui n'était pas présent dans le dernier instantané ; Git ne le placera sous suivi de version que quand vous lui indiquerez de le faire.
Ce comportement permet de ne pas placer accidentellement sous suivi de version des fichiers binaires générés ou d'autres fichiers que vous ne voulez pas inclure.
Mais vous voulez inclure le fichier LISEZMOI dans l'instantané, alors commençons à suivre ce fichier.
Placer de nouveaux fichiers sous suivi de version
Pour commencer à suivre un nouveau fichier, vous utilisez la commande git add.
Pour commencer à suivre le fichier LISEZMOI, vous pouvez entrer ceci :
$ git add LISEZMOI
Si vous lancez à nouveau la commande git status, vous pouvez constater que votre fichier LISEZMOI est maintenant suivi et indexé :
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: LISEZMOI
#
Vous pouvez affirmer qu'il est indexé car il apparaît dans la section « Changes to be committed » (Modifications à valider).
Si vous enregistrez à ce moment, la version du fichier à l'instant où vous lancez git add est celle qui appartiendra à l'instantané.
Vous pouvez vous souvenir que lorsque vous avez précédemment lancé git init, vous avez ensuite lancé git add (fichiers) — c'était bien sûr pour commencer à placer sous suivi de version les fichiers de votre répertoire de travail.
La commande git add accepte en paramètre un chemin qui correspond à un fichier ou un répertoire ; dans le cas d'un répertoire, la commande ajoute récursivement tous les fichiers de ce répertoire.
Indexer des fichiers modifiés
Maintenant, modifions un fichier qui est déjà sous suivi de version.
Si vous modifiez le fichier sous suivi de version appelé benchmarks.rb et que vous lancez à nouveau votre commande git status, vous verrez ceci :
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: LISEZMOI
#
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
#
# modified: benchmarks.rb
#
Le fichier benchmarks.rb apparaît sous la section nommée « Changes not staged for commit » ce qui signifie que le fichier sous suivi de version a été modifié dans la copie de travail mais n'est pas encore indexé.
Pour l'indexer, il faut lancer la commande git add (qui est une commande multi-usage — elle peut être utilisée pour placer un fichier sous suivi de version, pour indexer un fichier ou pour d'autres actions telles que marquer comme résolus des conflits de fusion de fichiers).
Lançons maintenant git add pour indexer le fichier benchmarks.rb, et relançons la commande git status :
$ git add benchmarks.rb
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: LISEZMOI
# modified: benchmarks.rb
#
À présent, les deux fichiers sont indexés et feront partie de la prochaine validation.
Mais supposons que vous souhaitiez apporter encore une petite modification au fichier benchmarks.rb avant de réellement valider la nouvelle version.
Vous l'ouvrez à nouveau, réalisez la petite modification et vous voilà prêt à valider.
Néanmoins, vous lancez git status une dernière fois :
$ vim benchmarks.rb
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: LISEZMOI
# modified: benchmarks.rb
#
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
#
# modified: benchmarks.rb
#
Que s'est-il donc passé ? À présent, benchmarks.rb apparaît à la fois comme indexé et non indexé.
En fait, Git indexe un fichier dans son état au moment où la commande git add est lancée.
Si on valide les modifications maintenant, la version de benchmarks.rb qui fera partie de l'instantané est celle correspondant au moment où la commande git add benchmarks.rb a été lancée, et non la version actuellement présente dans la copie de travail au moment où la commande git commit est lancée.
Si le fichier est modifié après un git add, il faut relancer git add pour prendre en compte l'état actuel de la copie de travail :
$ git add benchmarks.rb
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: LISEZMOI
# modified: benchmarks.rb
#
Ignorer des fichiers
Il apparaît souvent qu'un type de fichiers présent dans la copie de travail ne doit pas être ajouté automatiquement ou même ne doit pas apparaître comme fichier potentiel pour le suivi de version.
Ce sont par exemple des fichiers générés automatiquement tels que les fichiers de journaux ou de sauvegardes produits par l'outil que vous utilisez.
Dans un tel cas, on peut énumérer les patrons de noms de fichiers à ignorer dans un fichier .gitignore.
Voici ci-dessous un exemple de fichier .gitignore :
$ cat .gitignore
*.[oa]
*~
La première ligne ordonne à Git d'ignorer tout fichier se terminant en .o ou .a — des fichiers objet ou archive qui sont généralement produits par la compilation d'un programme.
La seconde ligne indique à Git d'ignorer tous les fichiers se terminant par un tilde (~), ce qui est le cas des noms des fichiers temporaires pour de nombreux éditeurs de texte tels qu'Emacs.
On peut aussi inclure un répertoire log, tmp ou pid, ou le répertoire de documentation générée automatiquement, ou tout autre fichier.
Renseigner un fichier .gitignore avant de commencer à travailler est généralement une bonne idée qui évitera de valider par inadvertance des fichiers qui ne doivent pas apparaître dans le dépôt Git.
Les règles de construction des patrons à placer dans le fichier .gitignore sont les suivantes :
- les lignes vides ou commençant par
#sont ignorées ; - les patrons standards de fichiers sont utilisables ;
- si le patron se termine par une barre oblique (
/), il indique un répertoire ; - un patron commençant par un point d'exclamation (
!) indique des fichiers à inclure malgré les autres règles.
Les patrons standards de fichiers sont des expressions régulières simplifiées utilisées par les shells.
Un astérisque (*) correspond à un ou plusieurs caractères ; [abc] correspond à un des trois caractères listés dans les crochets, donc a ou b ou c ; un point d'interrogation (?) correspond à un unique caractère ; des crochets entourant des caractères séparés par un signe moins ([0-9]) correspond à un caractère dans l'intervalle des deux caractères indiqués, donc ici de 0 à 9.
Voici un autre exemple de fichier .gitignore :
# un commentaire, cette ligne est ignorée
# pas de fichier .a
*.a
# mais suivre lib.a malgré la règle précédente
!lib.a
# ignorer uniquement le fichier TODO à la racine du projet
/TODO
# ignorer tous les fichiers dans le répertoire build
build/
# ignorer doc/notes.txt, mais pas doc/server/arch.txt
doc/*.txt
# ignorer tous les fichiers .txt sous le répertoire doc/
doc/**/*.txt
Le patron **/ est disponible dans Git depuis la version 1.8.2.
Inspecter les modifications indexées et non indexées
Si le résultat de la commande git status est encore trop vague — lorsqu'on désire savoir non seulement quels fichiers ont changé mais aussi ce qui a changé dans ces fichiers — on peut utiliser la commande git diff.
Cette commande sera traitée en détail plus loin ; mais elle sera vraisemblablement utilisée le plus souvent pour répondre aux questions suivantes : qu'est-ce qui a été modifié mais pas encore indexé ? Quelle modification a été indexée et est prête pour la validation ? Là où git status répond de manière générale à ces questions, git diff montre les lignes exactes qui ont été ajoutées, modifiées ou effacées — le patch en somme.
Supposons que vous éditez et indexez le fichier LISEZMOI et que vous éditez le fichier benchmarks.rb sans l'indexer.
Si vous lancez la commande git status, vous verrez ceci :
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: LISEZMOI
#
# Changes not staged for commit:
# (use "git add <file>..." to update what will be committed)
#
# modified: benchmarks.rb
#
Pour visualiser ce qui a été modifié mais pas encore indexé, tapez git diff sans autre argument :
$ git diff
diff --git a/benchmarks.rb b/benchmarks.rb
index 3cb747f..da65585 100644
--- a/benchmarks.rb
+++ b/benchmarks.rb
@@ -36,6 +36,10 @@ def main
@commit.parents[0].parents[0].parents[0]
end
+ run_code(x, 'commits 1') do
+ git.commits.size
+ end
+
run_code(x, 'commits 2') do
log = git.commits('master', 15)
log.size
Cette commande compare le contenu du répertoire de travail avec la zone d'index. Le résultat vous indique les modifications réalisées mais non indexées.
Si vous souhaitez visualiser les modifications indexées qui feront partie de la prochaine validation, vous pouvez utiliser git diff --cached (avec les versions 1.6.1 et supérieures de Git, vous pouvez aussi utiliser git diff --staged, qui est plus mnémotechnique).
Cette commande compare les fichiers indexés et le dernier instantané :
$ git diff --cached
diff --git a/LISEZMOI b/LISEZMOI
new file mode 100644
index 0000000..03902a1
--- /dev/null
+++ b/LISEZMOI2
@@ -0,0 +1,5 @@
+grit
+ by Tom Preston-Werner, Chris Wanstrath
+ http://github.com/mojombo/grit
+
+Grit is a Ruby library for extracting information from a Git repository
Il est important de noter que git diff ne montre pas les modifications réalisées depuis la dernière validation — seulement les modifications qui sont non indexées.
Cela peut introduire une confusion car si tous les fichiers modifiés ont été indexés, git diff n'indiquera aucun changement.
Par exemple, si vous indexez le fichier benchmarks.rb et l'éditez ensuite, vous pouvez utiliser git diff pour visualiser les modifications indexées et non indexées de ce fichier :
$ git add benchmarks.rb
$ echo '# test line' >> benchmarks.rb
$ git status
# On branch master
#
# Changes to be committed:
#
# modified: benchmarks.rb
#
# Changes not staged for commit:
#
# modified: benchmarks.rb
#
À présent, vous pouvez utiliser git diff pour visualiser les modifications non indexées :
$ git diff
diff --git a/benchmarks.rb b/benchmarks.rb
index e445e28..86b2f7c 100644
--- a/benchmarks.rb
+++ b/benchmarks.rb
@@ -127,3 +127,4 @@ end
main()
##pp Grit::GitRuby.cache_client.stats
+# test line
et git diff --cached pour visualiser ce qui a été indexé jusqu'à maintenant :
$ git diff --cached
diff --git a/benchmarks.rb b/benchmarks.rb
index 3cb747f..e445e28 100644
--- a/benchmarks.rb
+++ b/benchmarks.rb
@@ -36,6 +36,10 @@ def main
@commit.parents[0].parents[0].parents[0]
end
+ run_code(x, 'commits 1') do
+ git.commits.size
+ end
+
run_code(x, 'commits 2') do
log = git.commits('master', 15)
log.size
Valider vos modifications
Maintenant que votre zone d'index est dans l'état désiré, vous pouvez valider vos modifications.
Souvenez-vous que tout ce qui est encore non indexé — tous les fichiers qui ont été créés ou modifiés mais n'ont pas subi de git add depuis que vous les avez modifiés — ne feront pas partie de la prochaine validation.
Ils resteront en tant que fichiers modifiés sur votre disque.
Dans notre cas, la dernière fois que vous avez lancé git status, vous avez vérifié que tout était indexé, et vous êtes donc prêt à valider vos modifications.
La manière la plus simple de valider est de taper git commit :
$ git commit
Cette action lance votre éditeur par défaut (qui est paramétré par la variable d'environnement $EDITOR de votre shell — habituellement vim ou Emacs, mais vous pouvez le paramétrer spécifiquement pour Git en utilisant la commande git config --global core.editor comme nous l'avons vu au chapitre 1).
L'éditeur affiche le texte suivant :
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# On branch master
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# new file: LISEZMOI
# modified: benchmarks.rb
~
~
~
".git/COMMIT_EDITMSG" 10L, 283C
Vous constatez que le message de validation par défaut contient une ligne vide suivie en commentaire par le résultat de la commande git status.
Vous pouvez effacer ces lignes de commentaire et saisir votre propre message de validation, ou vous pouvez les laisser en place pour vous aider à vous rappeler de ce que vous êtes en train de valider (pour un rappel plus explicite de ce que vous avez modifié, vous pouvez aussi passer l'option -v à la commande git commit.
Cette option place le résultat du diff en commentaire dans l'éditeur pour vous permettre de visualiser exactement ce que vous avez modifié.
Quand vous quittez l'éditeur (après avoir sauvegardé le message), Git crée votre commit avec ce message de validation (après avoir retiré les commentaires et le diff).
D'une autre manière, vous pouvez spécifier votre message de validation en ligne avec la commande git commit en le saisissant après l'option -m, comme ceci :
$ git commit -m "Story 182: Fix benchmarks for speed"
[master]: created 463dc4f: "Fix benchmarks for speed"
2 files changed, 3 insertions(+), 0 deletions(-)
create mode 100644 LISEZMOI
À présent, vous avez créé votre premier commit ! Vous pouvez constater que le commit vous fournit quelques informations sur lui-même : sur quelle branche vous avez validé (master), quelle est sa somme de contrôle SHA-1 (463dc4f), combien de fichiers ont été modifiés, et quelques statistiques sur les lignes ajoutées et effacées dans ce commit.
Souvenez-vous que la validation enregistre l'instantané que vous avez préparé dans la zone d'index. Tout ce que vous n'avez pas indexé est toujours en état modifié ; vous pouvez réaliser une nouvelle validation pour l'ajouter à l'historique. À chaque validation, vous enregistrez un instantané du projet en forme de jalon auquel vous pourrez revenir ou avec lequel comparer votre travail ultérieur.
Éliminer la phase d'indexation
Bien qu'il soit incroyablement utile de pouvoir organiser les commits exactement comme on l'entend, la gestion de la zone d'index est parfois plus complexe que nécessaire dans le cadre d'une utilisation normale.
Si vous souhaitez éviter la phase de placement des fichiers dans la zone d'index, Git fournit un raccourci très simple.
L'ajout de l'option -a à la commande git commit ordonne à Git de placer automatiquement tout fichier déjà en suivi de version dans la zone d'index avant de réaliser la validation, évitant ainsi d'avoir à taper les commandes git add :
$ git status
# On branch master
#
# Changes not staged for commit:
#
# modified: benchmarks.rb
#
$ git commit -a -m 'added new benchmarks'
[master 83e38c7] added new benchmarks
1 files changed, 5 insertions(+), 0 deletions(-)
Notez bien que vous n'avez pas eu à lancer git add sur le fichier benchmarks.rb avant de valider.
Effacer des fichiers
Pour effacer un fichier de Git, vous devez l'éliminer des fichiers en suivi de version (plus précisément, l'effacer dans la zone d'index) puis valider.
La commande git rm réalise cette action mais efface aussi ce fichier de votre copie de travail de telle sorte que vous ne le verrez pas réapparaître comme fichier non suivi en version à la prochaine validation.
Si vous effacez simplement le fichier dans votre copie de travail, il apparaît sous la section « Changes not staged for commit » (c'est-à-dire, non indexé) dans le résultat de git status :
$ rm grit.gemspec
$ git status
# On branch master
#
# Changes not staged for commit:
# (use "git add/rm <file>..." to update what will be committed)
#
# deleted: grit.gemspec
#
Ensuite, si vous lancez git rm, l'effacement du fichier est indexé :
$ git rm grit.gemspec
rm 'grit.gemspec'
$ git status
# On branch master
#
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# deleted: grit.gemspec
#
Lors de la prochaine validation, le fichier sera absent et non-suivi en version.
Si vous avez auparavant modifié et indexé le fichier, son élimination doit être forcée avec l'option -f.
C'est une mesure de sécurité pour empêcher un effacement accidentel de données qui n'ont pas encore été enregistrées dans un instantané et qui seraient définitivement perdues.
Un autre scénario serait de vouloir abandonner le suivi de version d'un fichier tout en le conservant dans la copie de travail.
Ceci est particulièrement utile lorsqu'on a oublié de spécifier un patron dans le fichier .gitignore et on a accidentellement indexé un fichier, tel qu'un gros fichier de journal ou une série d'archives de compilation .a.
Pour réaliser ce scénario, utilisez l'option --cached :
$ git rm --cached readme.txt
Vous pouvez spécifier des noms de fichiers ou de répertoires, ou des patrons de fichiers à la commande git rm.
Cela signifie que vous pouvez lancer des commandes telles que :
$ git rm log/\*.log
Notez bien la barre oblique inverse (\) devant *.
Il est nécessaire d'échapper le caractère * car Git utilise sa propre expansion de nom de fichier en addition de l'expansion du shell. Ce caractère d'échappement doit être omis sous Windows si vous utilisez le terminal système.
Cette commande efface tous les fichiers avec l'extension .log présents dans le répertoire log/.
Vous pouvez aussi lancer une commande telle que :
$ git rm \*~
Cette commande élimine tous les fichiers se terminant par ~.
Déplacer des fichiers
À la différence des autres VCS, Git ne suit pas explicitement les mouvements des fichiers. Si vous renommez un fichier suivi par Git, aucune méta-donnée indiquant le renommage n'est stockée par Git. Néanmoins, Git est assez malin pour s'en apercevoir après coup — la détection de mouvement de fichier sera traitée plus loin.
De ce fait, que Git ait une commande mv peut paraître trompeur.
Si vous souhaitez renommer un fichier dans Git, vous pouvez lancer quelque chose comme :
$ git mv nom_origine nom_cible
et cela fonctionne.
En fait, si vous lancez quelque chose comme ceci et inspectez le résultat d'une commande git status, vous constaterez que Git gère le renommage de fichier :
$ git mv LISEZMOI.txt LISEZMOI
$ git status
# On branch master
# Your branch is ahead of 'origin/master' by 1 commit.
#
# Changes to be committed:
# (use "git reset HEAD <file>..." to unstage)
#
# renamed: LISEZMOI.txt -> LISEZMOI
#
Néanmoins, cela revient à lancer les commandes suivantes :
$ mv LISEZMOI.txt LISEZMOI
$ git rm LISEZMOI.txt
$ git add LISEZMOI
Git trouve implicitement que c'est un renommage, donc cela importe peu si vous renommez un fichier de cette manière ou avec la commande mv.
La seule différence réelle est que mv ne fait qu'une commande à taper au lieu de trois — c'est une commande de convenance.
Le point principal est que vous pouvez utiliser n'importe quel outil pour renommer un fichier, et traiter les commandes add/rm plus tard, avant de valider la modification.