Sélection des versions
Git vous permet d'adresser certains commits ou un ensemble de commits de différentes façons. Si elles ne sont pas toutes évidentes, il est bon de les connaître.
Révisions ponctuelles
Naturellement, vous pouvez référencer un commit par sa signature SHA-1, mais il existe des méthodes plus confortables pour les humains. Cette section présente les méthodes pour référencer un commit simple.
Empreinte SHA courte
Git est capable de deviner de quel commit vous parlez si vous ne fournissez que quelques caractères du début de la signature, tant que votre SHA-1 partiel comporte au moins 4 caractères et ne correspond pas à plusieurs commits. Dans ces conditions, un seul objet correspondra à ce SHA-1 partiel.
Par exemple, pour afficher un commit précis, supposons que vous exécutiez git log et que vous identifiiez le commit où vous avez introduit une fonctionnalité précise.
$ git log
commit 734713bc047d87bf7eac9674765ae793478c50d3
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 14:58:32 2008 -0800
added some blame and merge stuff
Pour cet exemple, choisissons 1c002dd....
Si vous affichez le contenu de ce commit via git show, les commandes suivantes sont équivalentes (en partant du principe que les SHA-1 courts ne sont pas ambigus).
$ git show 1c002dd4b536e7479fe34593e72e6c6c1819e53b
$ git show 1c002dd4b536e7479f
$ git show 1c002d
Git peut déterminer une référence SHA-1 tout à la fois la plus courte possible et non ambigüe.
Ajoutez l'option --abbrev-commit à la commande git log et le résultat affiché utilisera des valeurs plus courtes mais uniques ; par défaut Git retiendra 7 caractères et augmentera au besoin :
$ git log --abbrev-commit --pretty=oneline
ca82a6d changed the version number
085bb3b removed unnecessary test code
a11bef0 first commit
En règle générale, entre 8 et 10 caractères sont largement suffisant pour assurer l'unicité dans un projet. Un des plus gros projets utilisant Git, le noyau Linux, nécessite de plus en plus fréquemment 12 caractères sur les 40 possibles pour assurer l'unicité.
Quelques mots sur SHA-1
Beaucoup de gens s'inquiètent qu'à un moment donné ils auront, par des circonstances hasardeuses, deux objets dans leur référentiel de hachage de même empreinte SHA-1. Qu'en est-il réellement ?
S'il vous arrivait de valider un objet qui se hache à la même empreinte SHA-1 qu'un objet existant dans votre référentiel, Git verrait l'objet existant déjà dans votre base de données et présumerait qu'il était déjà enregistré. Si vous essayez de récupérer l'objet de nouveau à un moment donné, vous auriez toujours les données du premier objet.
Quoi qu'il en soit, vous devriez être conscient à quel point ce scénario est ridiculement improbable.
Une empreinte SHA-1 porte sur 20 octets soit 160 bits.
Le nombre d'objets aléatoires à hacher requis pour assurer une probabilité de collision de 50 % vaut environ 2^80 (la formule pour calculer la probabilité de collision est p = (n(n-1)/2) * (1/2^160)).
2^80 vaut 1,2 × 10^24 soit 1 million de milliards de milliards.
Cela représente 1200 fois le nombre de grains de sable sur Terre.
Voici un exemple pour vous donner une idée de ce qui pourrait provoquer une collision du SHA-1. Si tous les 6,5 milliards d'humains sur Terre programmaient et que chaque seconde, chacun produisait du code équivalent à l'historique entier du noyau Linux (1 million d'objets Git) et le poussait sur un énorme dépôt Git, cela prendrait 5 ans pour que ce dépôt contienne assez d'objets pour avoir une probabilité de 50 % qu'une seule collision SHA-1 existe. Il y a une probabilité plus grande que tous les membres de votre équipe de programmation soient attaqués et tués par des loups dans des incidents sans relation la même nuit.
Références de branches
La méthode la plus commune pour désigner un commit est une branche y pointant.
Dès lors, vous pouvez utiliser le nom de la branche dans toute commande utilisant un objet de type commit ou un SHA-1.
Par exemple, si vous souhaitez afficher le dernier commit d'une branche, les commandes suivantes sont équivalentes, en supposant que la branche sujet1 pointe sur ca82a6d :
$ git show ca82a6dff817ec66f44342007202690a93763949
$ git show sujet1
Pour connaître l'empreinte SHA sur laquelle pointe une branche ou pour savoir parmi tous les exemples précédents ce que cela donne en terme de SHA, vous pouvez utiliser la commande de plomberie nommée rev-parse.
Référez-vous au chapitre 9 pour plus d'informations sur les commandes de plomberie ; rev-parse sert aux opérations de bas niveau et n'est pas conçue pour être utilisée au jour le jour.
Quoi qu'il en soit, elle se révèle utile pour comprendre ce qui se passe.
Je vous invite à tester rev-parse sur votre propre branche.
$ git rev-parse sujet1
ca82a6dff817ec66f44342007202690a93763949
Raccourcis RefLog
Git maintient en arrière-plan un historique des références où sont passés HEAD et vos branches sur les derniers mois — ceci s'appelle le reflog.
Vous pouvez le consulter avec la commande git reflog :
$ git reflog
734713b... HEAD@{0}: commit: fixed refs handling, added gc auto, updated
d921970... HEAD@{1}: merge phedders/rdocs: Merge made by recursive.
1c002dd... HEAD@{2}: commit: added some blame and merge stuff
1c36188... HEAD@{3}: rebase -i (squash): updating HEAD
95df984... HEAD@{4}: commit: # This is a combination of two commits.
1c36188... HEAD@{5}: rebase -i (squash): updating HEAD
7e05da5... HEAD@{6}: rebase -i (pick): updating HEAD
À chaque fois que l'extrémité de votre branche est modifiée, Git enregistre cette information pour vous dans son historique temporaire.
Vous pouvez référencer d'anciens commits avec cette donnée.
Si vous souhaitez consulter le n-ième antécédent de votre HEAD, vous pouvez utiliser la référence @{n} du reflog, 5 dans cet exemple :
$ git show HEAD@{5}
Vous pouvez également remonter le temps et savoir où en était une branche à une date donnée.
Par exemple, pour savoir où en était la branche master hier (yesterday en anglais), tapez :
$ git show master@{yesterday}
Cette technique fonctionne uniquement si l'information est encore présente dans le reflog et vous ne pourrez donc pas le consulter sur des commits trop anciens.
Pour consulter le reflog au format git log, exécutez: git log -g :
$ git log -g master
commit 734713bc047d87bf7eac9674765ae793478c50d3
Reflog: master@{0} (Scott Chacon <schacon@gmail.com>)
Reflog message: commit: fixed refs handling, added gc auto, updated
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Reflog: master@{1} (Scott Chacon <schacon@gmail.com>)
Reflog message: merge phedders/rdocs: Merge made by recursive.
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
Veuillez noter que le reflog ne stocke que des informations locales, c'est un historique de ce que vous avez fait dans votre dépôt.
Les références sont différentes pour un autre dépôt et juste après le clone d'un dépôt, votre reflog sera vide puisque qu'aucune activité ne s'y sera produite.
Exécuter git show HEAD@{2.months.ago} ne fonctionnera que si vous avez dupliqué ce projet depuis au moins 2 mois — si vous l'avez dupliqué il y a 5 minutes, vous n'obtiendrez rien.
Références passées
Une solution fréquente pour référencer un commit est d'utiliser sa descendance.
Si vous suffixez une référence par ^, Git la résoudra comme étant le parent de cette référence.
Supposons que vous consultiez votre historique :
$ git log --pretty=format:'%h %s' --graph
* 734713b fix sur la gestion des refs, ajout gc auto, mise à jour des tests
* d921970 Merge commit 'phedders/rdocs'
|\
| * 35cfb2b modifs minor rdoc
* | 1c002dd ajout blame and merge
|/
* 1c36188 ignore *.gem
* 9b29157 ajout open3_detach à la liste des fichiers gemspcec
Alors, vous pouvez consulter le commit précédent en spécifiant HEAD^, ce qui signifie « le parent de HEAD » :
$ git show HEAD^
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
Vous pouvez également spécifier un nombre après ^ — par exemple, d921970^2 signifie « le second parent de d921970 ».
Cette syntaxe ne sert que pour les commits de fusion, qui ont plus d'un parent.
Le premier parent est la branche où vous avez fusionné, et le second est le commit de la branche que vous avez fusionnée :
$ git show d921970^
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 14:58:32 2008 -0800
ajout blame and merge
$ git show d921970^2
commit 35cfb2b795a55793d7cc56a6cc2060b4bb732548
Author: Paul Hedderly <paul+git@mjr.org>
Date: Wed Dec 10 22:22:03 2008 +0000
modifs minor rdoc
Une autre solution courante pour spécifier une référence est le ~.
Il fait également référence au premier parent, donc HEAD~ et HEAD^ sont équivalents.
La différence se fait sentir si vous spécifiez un nombre.
HEAD~2 signifie « le premier parent du premier parent », ou bien « le grand-parent » ; on remonte les premiers parents autant de fois que demandé.
Par exemple, dans l'historique précédemment présenté, HEAD~3 serait :
$ git show HEAD~3
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <tom@mojombo.com>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gem
Cela peut aussi s'écrire HEAD^^^, qui là encore est le premier parent du premier parent du premier parent :
$ git show HEAD^^^
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <tom@mojombo.com>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gem
Vous pouvez également combiner ces syntaxes — vous pouvez obtenir le second parent de la référence précédente (en supposant que c'était un commit de fusion) en utilisant HEAD~3^2, etc.
Plages de commits
À présent que vous pouvez spécifier des commits individuels, voyons comment spécifier des plages de commits. Ceci est particulièrement pratique pour la gestion des branches — si vous avez beaucoup de branches, vous pouvez utiliser les plages pour répondre à des questions telles que « Quel travail sur cette branche n'ai-je pas encore fusionné sur ma branche principale ? ».
Double point
La spécification de plage de commits la plus fréquente est la syntaxe double-point. En gros, cela demande à Git de résoudre la plage des commits qui sont accessibles depuis un commit mais ne le sont pas depuis un autre. Par exemple, disons que votre historique ressemble à celui de la figure 6-1.
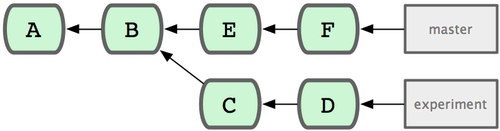
Figure 6-1. Exemple d'historique pour la sélection de plages de commits.
Si vous voulez savoir ce qui n'a pas encore été fusionné sur votre branche master depuis votre branche experience, vous pouvez demander à Git de vous montrer un listing des commits avec master..experience — ce qui signifie « tous les commits accessibles par experience qui ne le sont pas par master ».
Dans un souci de brièveté et de clarté de ces exemples, je vais utiliser les lettres des commits issus du diagramme à la place du vrai listing dans l'ordre où ils auraient dû être affichés :
$ git log master..experiment
D
C
D'un autre côté, si vous souhaitez voir l'opposé — tous les commits dans master mais pas encore dans experience — vous pouvez inverser les noms de branches, experience..master vous montre tout ce que master accède mais qu'experience ne voit pas :
$ git log experience..master
F
E
C'est pratique si vous souhaitez maintenir experience à jour et anticiper les fusions.
Un autre cas d'utilisation fréquent consiste à voir ce que vous vous apprêtez à pousser sur une branche distante :
$ git log origin/master..HEAD
Cette commande vous affiche tous les commits de votre branche courante qui ne sont pas sur la branche master du dépôt distant origin.
Si vous exécutez git push et que votre branche courante suit origin/master, les commits listés par git log origin/master..HEAD sont les commits qui seront transférés sur le serveur.
Vous pouvez également laisser tomber une borne de la syntaxe pour faire comprendre à Git que vous parlez de HEAD.
Par exemple, vous pouvez obtenir les mêmes résultats que précédemment en tapant git log origin/master.. — Git utilise HEAD si une des bornes est manquante.
Emplacements multiples
La syntaxe double-point est pratique comme raccourci ; mais peut-être souhaitez-vous utiliser plus d'une branche pour spécifier une révision, comme pour voir quels commits sont dans plusieurs branches mais sont absents de la branche courante.
Git vous permet cela avec ^ ou --not en préfixe de toute référence de laquelle vous ne souhaitez pas voir les commits.
Les 3 commandes ci-après sont équivalentes :
$ git log refA..refB
$ git log ^refA refB
$ git log refB --not refA
C'est utile car cela vous permet de spécifier plus de 2 références dans votre requête, ce que vous ne pouvez accomplir avec la syntaxe double-point.
Par exemple, si vous souhaitez voir les commits qui sont accessibles depuis refA et refB mais pas depuis refC, vous pouvez taper ces 2 commandes :
$ git log refA refB ^refC
$ git log refA refB --not refC
Ceci vous fournit un système de requêtage des révisions très puissant, pour vous aider à saisir ce qui se trouve sur vos branches.
Triple point
La dernière syntaxe majeure de sélection de plage de commits est la syntaxe triple-point qui spécifie tous les commits accessibles par l'une des deux références, exclusivement.
Toujours avec l'exemple d'historique à la figure 6-1, si vous voulez voir ce qui se trouve sur master ou experience mais pas sur les deux, exécutez :
$ git log master...experience
F
E
D
C
Encore une fois, cela vous donne un log normal mais ne vous montre les informations que pour ces quatre commits, dans l'ordre naturel des dates de validation.
Une option courante à utiliser avec la commande log dans ce cas est --left-right qui vous montre la borne de la plage à laquelle ce commit appartient.
Cela rend les données plus utiles :
$ git log --left-right master...experience
< F
< E
> D
> C
Avec ces outils, vous pourrez spécifier à Git les commits que vous souhaitez inspecter.