Contribution à un projet
Vous savez ce que sont les différents modes de gestion et vous devriez connaître suffisamment l'utilisation de Git. Dans cette section, vous apprendrez les moyens les plus utilisés pour contribuer à un projet.
La principale difficulté à décrire ce processus réside dans l'extraordinaire quantité de variations dans sa réalisation. Comme Git est très flexible, les gens peuvent collaborer de différentes façons et ils le font, et il devient problématique de décrire de manière unique comment devrait se réaliser la contribution à un projet. Chaque projet est légèrement différent. Les variables incluent la taille du corps des contributeurs, le choix du flux de gestion, les accès en validation et la méthode de contribution externe.
La première variable est la taille du corps de contributeurs. Combien de personnes contribuent activement du code sur ce projet et à quelle vitesse ? Dans de nombreux cas, vous aurez deux à trois développeurs avec quelques validations par jour, voire moins pour des projets endormis. Pour des sociétés ou des projets particulièrement grands, le nombre de développeurs peut chiffrer à des milliers, avec des dizaines, voire des centaines de patchs ajoutés chaque jour. Ce cas est important car avec de plus en plus de développeurs, les problèmes de fusion et d'application de patch deviennent de plus en plus courants. Les modifications soumises par un développeur peuvent être obsolètes ou impossibles à appliquer à cause de changements qui ont eu lieu dans l'intervalle de leur développement, de leur approbation ou de leur application. Comment dans ces conditions conserver son code en permanence synchronisé et ses patchs valides ?
La variable suivante est le mode de gestion utilisé pour le projet. Est-il centralisé avec chaque développeur ayant un accès égal en écriture sur la ligne de développement principale ? Le projet présente-t-il un mainteneur ou un gestionnaire d'intégration qui vérifie tous les patchs ? Tous les patchs doivent-ils subir une revue de pair et une approbation ? Faites-vous partie du processus ? Un système à lieutenants est-il en place et doit-on leur soumettre les modifications en premier ?
La variable suivante est la gestion des accès en écriture. Le mode de gestion nécessaire à la contribution au projet est très différent selon que vous avez ou non accès au dépôt en écriture. Si vous n'avez pas accès en écriture, quelle est la méthode préférée pour la soumission de modifications ? Y a-t-il seulement une politique en place ? Quelle est la quantité de modifications fournie à chaque fois ? Quelle est la périodicité de contribution ?
Toutes ces questions affectent la manière de contribuer efficacement à un projet et les modes de gestion disponibles ou préférables. Je vais traiter ces sujets dans une série de cas d'utilisation allant des plus simples aux plus complexes. Vous devriez pouvoir construire vos propres modes de gestion à partir de ces exemples.
Guides pour une validation
Avant de passer en revue les cas d'utilisation spécifiques, voici un point rapide sur les messages de validation.
La définition et l'utilisation d'une bonne ligne de conduite sur les messages de validation facilitent grandement l'utilisation de Git et la collaboration entre développeurs.
Le projet Git fournit un document qui décrit un certain nombre de bonnes pratiques pour créer des commits qui serviront à fournir des patchs — le document est accessible dans les sources de Git, dans le fichier Documentation/SubmittingPatches.
Premièrement, il ne faut pas soumettre de patchs comportant des erreurs d'espace (caractères espace inutiles en fin de ligne).
Git fournit un moyen simple de le vérifier — avant de valider, lancez la commande git diff --check qui identifiera et listera les erreurs d'espace.
Voici un exemple dans lequel les caractères en couleur rouge ont été remplacés par des X :
$ git diff --check
lib/simplegit.rb:5: trailing whitespace.
+ @git_dir = File.expand_path(git_dir)XX
lib/simplegit.rb:7: trailing whitespace.
+ XXXXXXXXXXX
lib/simplegit.rb:26: trailing whitespace.
+ def command(git_cmd)XXXX
En lançant cette commande avant chaque validation, vous pouvez vérifier que vous ne commettez pas d'erreurs d'espace qui pourraient ennuyer les autres développeurs.
Ensuite, assurez-vous de faire de chaque validation une modification logiquement atomique. Si possible, rendez chaque modification digeste — ne codez pas pendant un week-end entier sur cinq sujets différents pour enfin les soumettre tous dans une énorme validation le lundi suivant.
Même si vous ne validez pas du week-end, utilisez la zone d'index le lundi pour découper votre travail en au moins une validation par problème, avec un message utile par validation.
Si certaines modifications touchent au même fichier, essayez d'utiliser git add --patch pour indexer partiellement des fichiers (cette fonctionnalité est traitée au chapitre 6).
L'instantané final sera identique, que vous utilisiez une validation unique ou cinq petites validations, à condition que toutes les modifications soient intégrées à un moment, donc n'hésitez pas à rendre la vie plus simple à vos compagnons développeurs lorsqu'ils auront à vérifier vos modifications.
Cette approche simplifie aussi le retrait ou l'inversion ultérieurs d'une modification en cas de besoin.
Le chapitre 6 décrit justement quelques trucs et astuces de Git pour réécrire l'historique et indexer interactivement les fichiers — utilisez ces outils pour fabriquer un historique propre et compréhensible.
Le dernier point à soigner est le message de validation. S'habituer à écrire des messages de validation de qualité facilite grandement l'emploi et la collaboration avec Git. En règle générale, les messages doivent débuter par une ligne unique d'au plus 50 caractères décrivant concisément la modification, suivie d'une ligne vide, suivie d'une explication plus détaillée. Le projet Git exige que l'explication détaillée inclue la motivation de la modification en contrastant le nouveau comportement par rapport à l'ancien — c'est une bonne règle de rédaction. Une bonne règle consiste aussi à utiliser le présent de l'impératif ou des verbes substantivés dans le message. En d'autres termes, utilisez des ordres. Au lieu d'écrire « J'ai ajouté des tests pour » ou « En train d'ajouter des tests pour », utilisez juste « Ajoute des tests pour » ou « Ajout de tests pour ».
Voici ci-dessous un modèle écrit par Tim Pope at tpope.net :
Court résumé des modifications (50 caractères ou moins)
Explication plus détaillée, si nécessaire. Retour à la ligne vers 72
caractères. Dans certains contextes, la première ligne est traitée
comme le sujet d'un e-mail et le reste comme le corps. La ligne
vide qui sépare le titre du corps est importante (à moins d'omettre
totalement le corps). Des outils tels que rebase peuvent être gênés
si vous les laissez collés.
Paragraphes supplémentaires après des lignes vides.
- Les listes à puce sont aussi acceptées
- Typiquement, un tiret ou un astérisque précédés d'un espace unique
séparés par des lignes vides mais les conventions peuvent varier
Si tous vos messages de validation ressemblent à ceci, les choses seront beaucoup plus simples pour vous et les développeurs avec qui vous travaillez.
Le projet Git montre des messages de commit bien formatés — je vous encourage à y lancer un git log --no-merges pour pouvoir voir comment rend un historique de messages bien formatés.
Dans les exemples suivants et à travers tout ce livre, par souci de simplification, je ne formaterai pas les messages aussi proprement.
J'utiliserai plutôt l'option -m de git commit.
Faites ce que je dis, pas ce que je fais.
Cas d'une petite équipe privée
Le cas le plus probable que vous rencontrerez est celui du projet privé avec un ou deux autres développeurs. Par privé, j'entends code source fermé non accessible au public en lecture. Vous et les autres développeurs aurez accès en poussée au dépôt.
Dans cet environnement, vous pouvez suivre une méthode similaire à ce que vous feriez en utilisant Subversion ou tout autre système centralisé.
Vous bénéficiez toujours d'avantages tels que la validation hors-ligne et la gestion de branche et de fusion grandement simplifiée mais les étapes restent similaires.
La différence principale reste que les fusions ont lieu du côté client plutôt que sur le serveur au moment de valider.
Voyons à quoi pourrait ressembler la collaboration de deux développeurs sur un dépôt partagé.
Le premier développeur, John, clone le dépôt, fait une modification et valide localement.
Dans les exemples qui suivent, les messages de protocole sont remplacés par ... pour les raccourcir.
# Ordinateur de John
$ git clone john@githost:simplegit.git
Initialized empty Git repository in /home/john/simplegit/.git/
...
$ cd simplegit/
$ vim lib/simplegit.rb
$ git commit -am 'Eliminer une valeur par defaut invalide'
[master 738ee87] Eliminer une valeur par defaut invalide
1 files changed, 1 insertions(+), 1 deletions(-)
La deuxième développeuse, Jessica, fait la même chose. Elle clone le dépôt et valide une modification :
# Ordinateur de Jessica
$ git clone jessica@githost:simplegit.git
Initialized empty Git repository in /home/jessica/simplegit/.git/
...
$ cd simplegit/
$ vim TODO
$ git commit -am 'Ajouter une tache reset'
[master fbff5bc] Ajouter une tache reset
1 files changed, 1 insertions(+), 0 deletions(-)
À présent, Jessica pousse son travail sur le serveur :
# Ordinateur de Jessica
$ git push origin master
...
To jessica@githost:simplegit.git
1edee6b..fbff5bc master -> master
John tente aussi de pousser ses modifications :
# Ordinateur de John
$ git push origin master
To john@githost:simplegit.git
! [rejected] master -> master (non-fast forward)
error: failed to push some refs to 'john@githost:simplegit.git'
John n'a pas le droit de pousser parce que Jessica a déjà poussé dans l'intervalle. Il est très important de comprendre ceci si vous avez déjà utilisé Subversion, parce qu'il faut remarquer que les deux développeurs n'ont pas modifié le même fichier. Quand des fichiers différents ont été modifiés, Subversion réalise cette fusion automatiquement sur le serveur alors que Git nécessite une fusion des modifications locale. John doit récupérer les modifications de Jessica et les fusionner avant d'être autorisé à pousser :
$ git fetch origin
...
From john@githost:simplegit
+ 049d078...fbff5bc master -> origin/master
À présent, le dépôt local de John ressemble à la figure 5-4.
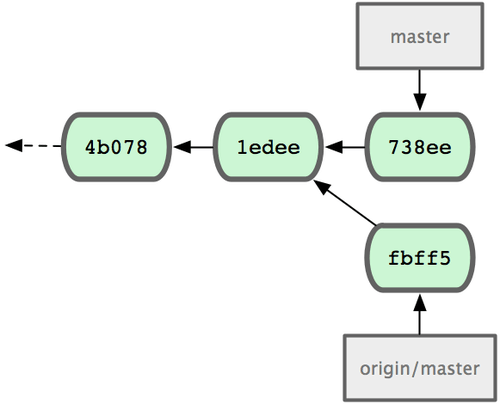
Figure 5-4. État initial du dépôt de John.
John a une référence aux modifications que Jessica a poussées, mais il doit les fusionner dans sa propre branche avant de pouvoir pousser :
$ git merge origin/master
Merge made by recursive.
TODO | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
Cette fusion se passe sans problème — l'historique de commits de John ressemble à présent à la figure 5-5.
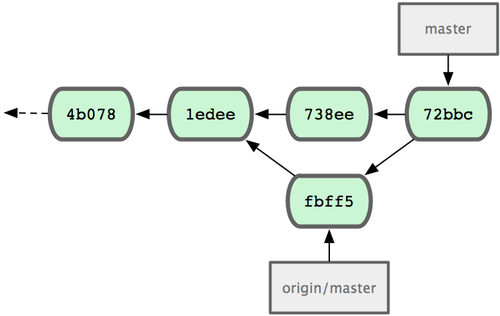
Figure 5-5. Le dépôt local de John après la fusion d'origin/master.
Maintenant, John peut tester son code pour s'assurer qu'il fonctionne encore correctement et peut pousser son travail nouvellement fusionné sur le serveur :
$ git push origin master
...
To john@githost:simplegit.git
fbff5bc..72bbc59 master -> master
À la fin, l'historique des commits de John ressemble à la figure 5-6.
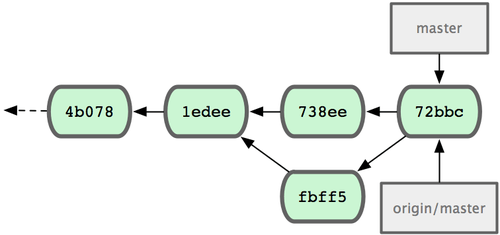
Figure 5-6. L'historique de John après avoir poussé sur le serveur origin.
Dans l'intervalle, Jessica a travaillé sur une branche thématique.
Elle a créé une branche thématique nommée prob54 et réalisé trois validations sur cette branche.
Elle n'a pas encore récupéré les modifications de John, ce qui donne un historique semblable à la figure 5-7.
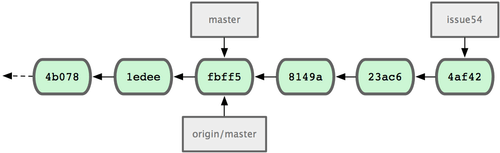
Figure 5-7. L'historique initial des commits de Jessica.
Jessica souhaite se synchroniser sur le travail de John. Elle récupère donc ses modifications :
# Ordinateur de Jessica
$ git fetch origin
...
From jessica@githost:simplegit
fbff5bc..72bbc59 master -> origin/master
Cette commande tire le travail que John avait poussé dans l'intervalle. L'historique de Jessica ressemble maintenant à la figure 5-8.
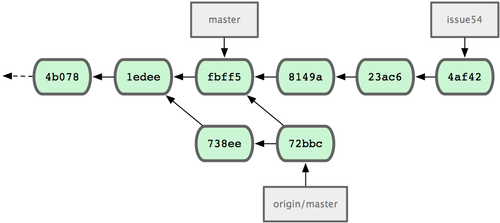
Figure 5-8. L'historique de Jessica après avoir récupéré les modifications de John.
Jessica pense que sa branche thématique est prête mais elle souhaite savoir si elle doit fusionner son travail avant de pouvoir pousser.
Elle lance git log pour s'en assurer :
$ git log --no-merges origin/master ^issue54
commit 738ee872852dfaa9d6634e0dea7a324040193016
Author: John Smith <jsmith@example.com>
Date: Fri May 29 16:01:27 2009 -0700
Eliminer une valeur par defaut invalide
Maintenant, Jessica peut fusionner sa branche thématique dans sa branche master, fusionner le travail de John (origin/master)dans sa branche master, puis pousser le résultat sur le serveur.
Premièrement, elle rebascule sur sa branche master pour intégrer son travail :
$ git checkout master
Switched to branch "master"
Your branch is behind 'origin/master' by 2 commits, and can be fast-forwarded.
Elle peut fusionner soit origin/master soit prob54 en premier — les deux sont en avance, mais l'ordre n'importe pas.
L'instantané final devrait être identique quel que soit l'ordre de fusion qu'elle choisit.
Seul l'historique sera légèrement différent.
Elle choisit de fusionner en premier prob54 :
$ git merge prob54
Updating fbff5bc..4af4298
Fast forward
LISEZMOI | 1 +
lib/simplegit.rb | 6 +++++-
2 files changed, 6 insertions(+), 1 deletions(-)
Aucun problème n'apparaît.
Comme vous pouvez le voir, c'est une simple avance rapide.
Maintenant, Jessica fusionne le travail de John (origin/master) :
$ git merge origin/master
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
Tout a fusionné proprement et l'historique de Jessica ressemble à la figure 5-9.
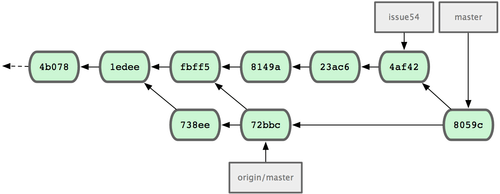
Figure 5-9. L'historique de Jessica après avoir fusionné les modifications de John.
Maintenant origin/master est accessible depuis la branche master de Jessica, donc elle devrait être capable de pousser (en considérant que John n'a pas encore poussé dans l'intervalle) :
$ git push origin master
...
To jessica@githost:simplegit.git
72bbc59..8059c15 master -> master
Chaque développeur a validé quelques fois et fusionné les travaux de l'autre avec succès (voir figure 5-10).
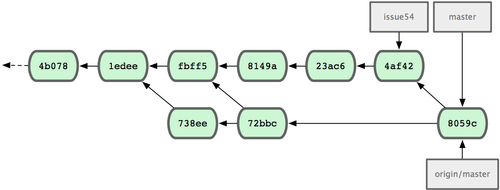
Figure 5-10. L'historique de Jessica après avoir poussé toutes ses modifications sur le serveur.
C'est un des schémas les plus simples.
Vous travaillez pendant quelque temps, généralement sur une branche thématique, et fusionnez dans votre branche master quand elle est prête à être intégrée.
Quand vous souhaitez partager votre travail, vous récupérez origin/master et la fusionnez si elle a changé, puis finalement vous poussez le résultat sur la branche master du serveur.
La séquence est illustrée par la figure 5-11.
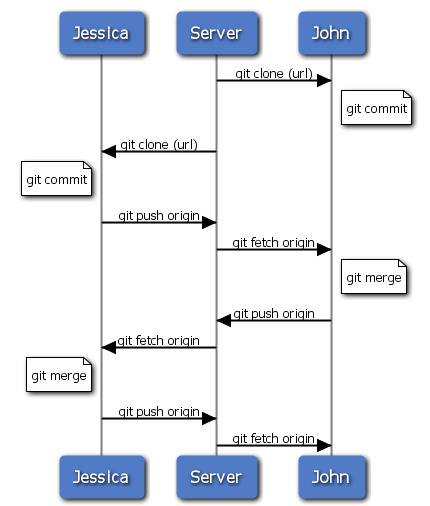
Figure 5-11. Séquence générale des évènements pour une utilisation simple multi-développeur de Git.
Équipe privée importante
Dans le scénario suivant, nous aborderons les rôles de contributeur dans un groupe privé plus grand. Vous apprendrez comment travailler dans un environnement où des petits groupes collaborent sur des fonctionnalités, puis les contributions de chaque équipe sont intégrées par une autre entité.
Supposons que John et Jessica travaillent ensemble sur une première fonctionnalité, tandis que Jessica et Josie travaillent sur une autre.
Dans ce cas, l'entreprise utilise un mode d'opération de type « gestionnaire d'intégration » où le travail des groupes est intégré par certains ingénieurs, et la branche master du dépôt principal ne peut être mise à jour que par ces ingénieurs.
Dans ce scénario, tout le travail est validé dans des branches orientées équipe, et tiré plus tard par les intégrateurs.
Suivons le cheminement de Jessica tandis qu'elle travaille sur les deux nouvelles fonctionnalités, collaborant en parallèle avec deux développeurs différents dans cet environnement.
En supposant qu'elle ait cloné son dépôt, elle décide de travailler sur la fonctionA en premier.
Elle crée une nouvelle branche pour cette fonction et travaille un peu dessus :
# Ordinateur de Jessica
$ git checkout -b fonctionA
Switched to a new branch "fonctionA"
$ vim lib/simplegit.rb
$ git commit -am 'Ajouter une limite à la fonction de log'
[fonctionA 3300904] Ajouter une limite à la fonction de log
1 files changed, 1 insertions(+), 1 deletions(-)
À ce moment, elle a besoin de partager son travail avec John, donc elle pousse les commits de sa branche fonctionA sur le serveur.
Jessica n'a pas le droit de pousser sur la branche master — seuls les intégrateurs l'ont — et elle doit donc pousser sur une autre branche pour collaborer avec John :
$ git push origin fonctionA
...
To jessica@githost:simplegit.git
* [new branch] fonctionA -> fonctionA
Jessica envoie un e-mail à John pour lui indiquer qu'elle a poussé son travail dans la branche appelée fonctionA et qu'il peut l'inspecter.
Pendant qu'elle attend le retour de John, Jessica décide de commencer à travailler sur la fonctionB avec Josie.
Pour commencer, elle crée une nouvelle branche thématique, à partir de la base master du serveur :
# Ordinateur de Jessica
$ git fetch origin
$ git checkout -b fonctionB origin/master
Switched to a new branch "fonctionB"
À présent, Jessica réalise quelques validations sur la branche fonctionB :
$ vim lib/simplegit.rb
$ git commit -am 'Rendre la fonction ls-tree recursive'
[fonctionB e5b0fdc] Rendre la fonction ls-tree recursive
1 files changed, 1 insertions(+), 1 deletions(-)
$ vim lib/simplegit.rb
$ git commit -am 'Ajout de ls-files'
[fonctionB 8512791] Ajout ls-files
1 files changed, 5 insertions(+), 0 deletions(-)
Le dépôt de Jessica ressemble à la figure 5-12.
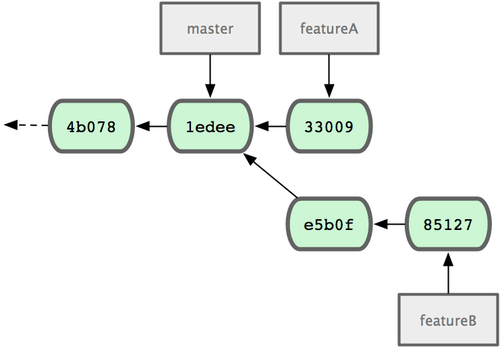
Figure 5-12. L'historique initial de Jessica.
Elle est prête à pousser son travail, mais elle reçoit un mail de Josie indiquant qu'une branche avec un premier travail a déjà été poussé sur le serveur en tant que fonctionBee.
Jessica doit d'abord fusionner ces modifications avec les siennes avant de pouvoir pousser sur le serveur.
Elle peut récupérer les modifications de Josie avec git fetch :
$ git fetch origin
...
From jessica@githost:simplegit
* [new branch] fonctionBee -> origin/fonctionBee
Jessica peut à présent fusionner ceci dans le travail qu'elle a réalisé grâce à git merge :
$ git merge origin/fonctionBee
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 4 ++++
1 files changed, 4 insertions(+), 0 deletions(-)
Mais il y a un petit problème — elle doit pousser son travail fusionné dans sa branche fonctionB sur la branche fonctionBee du serveur.
Elle peut le faire en spécifiant la branche locale suivie de deux points (:) suivi de la branche distante à la commande git push :
$ git push origin fonctionB:fonctionBee
...
To jessica@githost:simplegit.git
fba9af8..cd685d1 fonctionB -> fonctionBee
Cela s'appelle une refspec. Référez-vous au chapitre 9 pour une explication plus détaillée des refspecs Git et des possibilités qu'elles offrent.
Ensuite, John envoie un e-mail à Jessica pour lui indiquer qu'il a poussé des modifications sur la branche fonctionA et lui demander de les vérifier.
Elle lance git fetch pour tirer toutes ces modifications :
$ git fetch origin
...
From jessica@githost:simplegit
3300904..aad881d fonctionA -> origin/fonctionA
Elle peut alors voir ce qui a été modifié avec git log :
$ git log origin/fonctionA ^fonctionA
commit aad881d154acdaeb2b6b18ea0e827ed8a6d671e6
Author: John Smith <jsmith@example.com>
Date: Fri May 29 19:57:33 2009 -0700
largeur du log passee de 25 a 30
Finalement, elle fusionne le travail de John dans sa propre branche fonctionA :
$ git checkout fonctionA
Switched to branch "fonctionA"
$ git merge origin/fonctionA
Updating 3300904..aad881d
Fast forward
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)
Jessica veut régler quelques détails. Elle valide donc encore et pousse ses changements sur le serveur :
$ git commit -am 'details regles'
[fonctionA 774b3ed] details regles
1 files changed, 1 insertions(+), 1 deletions(-)
$ git push origin fonctionA
...
To jessica@githost:simplegit.git
3300904..774b3ed fonctionA -> fonctionA
L'historique des commits de Jessica ressemble à présent à la figure 5-13.
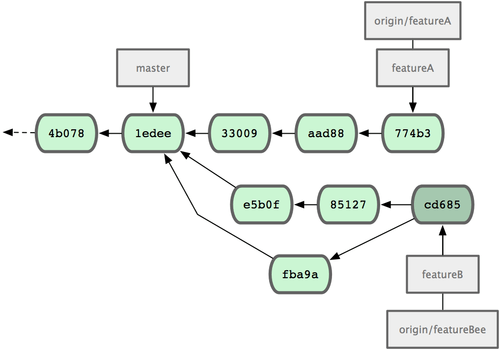
Figure 5-13. L'historique de Jessica après la validation dans la branche thématique.
Jessica, Josie et John informent les intégrateurs que les branches fonctionA et fonctionB du serveur sont prêtes pour une intégration dans la branche principale.
Après cette intégration, une synchronisation apportera les commits de fusion, ce qui donnera un historique comme celui de la figure 5-14.
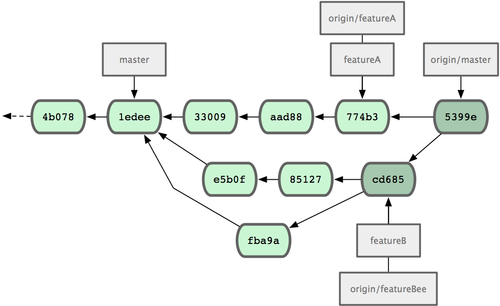
Figure 5-14. L'historique de Jessica après la fusion de ses deux branches thématiques.
De nombreuses équipes basculent vers Git du fait de cette capacité à gérer plusieurs équipes travaillant en parallèle, fusionnant plusieurs lignes de développement très tard dans le processus de livraison. La capacité donnée à plusieurs sous-groupes d'équipes de collaborer au moyen de branches distantes sans nécessairement impacter le reste de l'équipe est un grand bénéfice apporté par Git. La séquence de travail qui vous a été décrite ressemble à la figure 5-15.
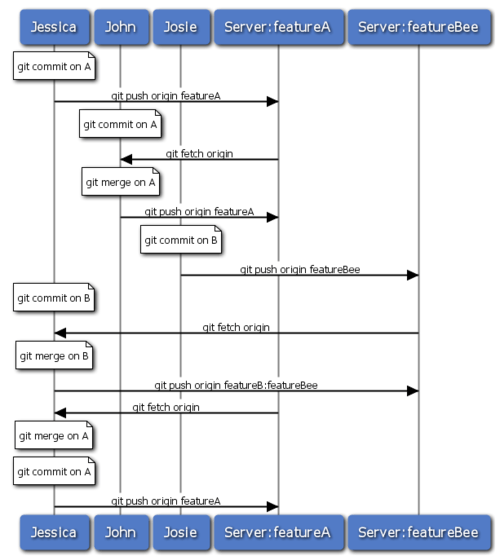
Figure 5-15. Une séquence simple de gestion orientée équipe.
Petit projet public
Contribuer à un projet public est assez différent. Il faut présenter le travail au mainteneur d'une autre manière parce que vous n'avez pas la possibilité de mettre à jour directement des branches du projet. Ce premier exemple décrit un mode de contribution via des serveurs Git qui proposent facilement la duplication de dépôt. Les sites repo.or.cz ou GitHub proposent cette méthode, et de nombreux mainteneurs s'attendent à ce style de contribution. Le chapitre suivant traite des projets qui préfèrent accepter les contributions sous forme de patch via e-mail.
Premièrement, vous souhaiterez probablement cloner le dépôt principal, créer une nouvelle branche thématique pour le patch ou la série de patchs que seront votre contribution, et commencer à travailler. La séquence ressemble globalement à ceci :
$ git clone (url)
$ cd projet
$ git checkout -b fonctionA
$ (travail)
$ git commit
$ (travail)
$ git commit
Vous pouvez utiliser rebase -i pour réduire votre travail à une seule validation ou pour réarranger les modifications dans des commits qui rendront les patchs plus faciles à relire pour le mainteneur — référez-vous au chapitre 6 pour plus d'information sur comment rebaser de manière interactive.
Lorsque votre branche de travail est prête et que vous êtes prêt à la fournir au mainteneur, rendez-vous sur la page du projet et cliquez sur le bouton « Fork » pour créer votre propre projet dupliqué sur lequel vous aurez les droits en écriture.
Vous devez alors ajouter l'URL de ce nouveau dépôt en tant que second dépôt distant, dans notre cas nommé macopie :
$ git remote add macopie (url)
Vous devez pousser votre travail sur ce dépôt distant.
C'est beaucoup plus facile de pousser la branche sur laquelle vous travaillez sur une branche distante que de fusionner et de pousser le résultat sur le serveur.
La raison principale en est que si le travail n'est pas accepté ou s'il est picoré, vous n'aurez pas à faire marche arrière sur votre branche master.
Si le mainteneur fusionne, rebase ou picore votre travail, vous le saurez en tirant depuis son dépôt :
$ git push macopie fonctionA
Une fois votre travail poussé sur votre copie du dépôt, vous devez notifier le mainteneur.
Ce processus est souvent appelé une demande de tirage (pull request) et vous pouvez la générer soit via le site web — GitHub propose un bouton « pull request » qui envoie automatiquement un message au mainteneur — soit lancer la commande git request-pull et envoyer manuellement par e-mail le résultat au mainteneur de projet.
La commande request-pull prend en paramètres la branche de base dans laquelle vous souhaitez que votre branche thématique soit fusionnée et l'URL du dépôt Git depuis lequel vous souhaitez qu'elle soit tirée, et génère un résumé des modifications que vous demandez à faire tirer.
Par exemple, si Jessica envoie à John une demande de tirage et qu'elle a fait deux validations dans la branche thématique qu'elle vient de pousser, elle peut lancer ceci :
$ git request-pull origin/master macopie
The following changes since commit 1edee6b1d61823a2de3b09c160d7080b8d1b3a40:
John Smith (1):
ajout d'une nouvelle fonction
are available in the git repository at:
git://githost/simplegit.git fonctionA
Jessica Smith (2):
Ajout d'une limite à la fonction de log
change la largeur du log de 25 a 30
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)
Le résultat peut être envoyé au mainteneur — cela lui indique d'où la modification a été branchée, le résumé des validations et d'où tirer ce travail.
Pour un projet dont vous n'êtes pas le mainteneur, il est généralement plus aisé de toujours laisser la branche master suivre origin/master et de réaliser vos travaux sur des branches thématiques que vous pourrez facilement effacer si elles sont rejetées.
Garder les thèmes de travaux isolés sur des branches thématiques facilite aussi leur rebasage si le sommet du dépôt principal a avancé dans l'intervalle et que vos modifications ne s'appliquent plus proprement.
Par exemple, si vous souhaitez soumettre un second sujet de travail au projet, ne continuez pas à travailler sur la branche thématique que vous venez de pousser mais démarrez en plutôt une depuis la branche master du dépôt principal :
$ git checkout -b fonctionB origin/master
$ (travail)
$ git commit
$ git push macopie fonctionB
$ (email au mainteneur)
$ git fetch origin
À présent, chaque sujet est contenu dans son propre silo — similaire à une file de patchs — que vous pouvez réécrire, rebaser et modifier sans que les sujets n'interfèrent ou ne dépendent les uns des autres, comme sur la figure 5-16.
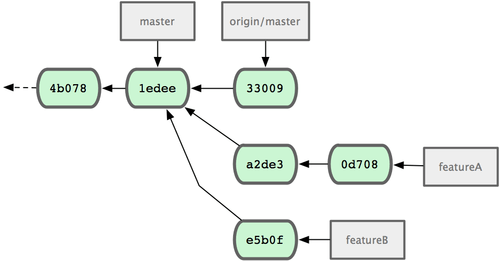
Figure 5-16. Historique initial des commits avec les modifications de fonctionB.
Supposons que le mainteneur du projet a tiré une poignée d'autres patchs et essayé par la suite votre première branche, mais celle-ci ne s'applique plus proprement.
Dans ce cas, vous pouvez rebaser cette branche au sommet de origin/master, résoudre les conflits pour le mainteneur et soumettre de nouveau vos modifications :
$ git checkout fonctionA
$ git rebase origin/master
$ git push –f macopie fonctionA
Cette action réécrit votre historique pour qu'il ressemble à la figure 5-17.
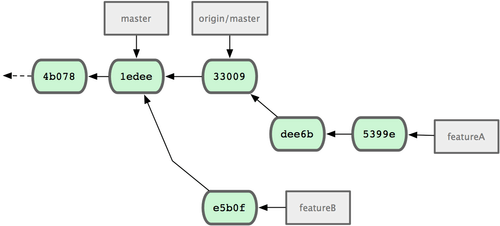
Figure 5-17. Historique des validations après le travail sur fonctionA.
Comme vous avez rebasé votre branche, vous devez spécifier l'option -f à votre commande pour pousser, pour forcer le remplacement de la branche fonctionA sur le serveur par la suite de commits qui n'en est pas descendante.
Une solution alternative serait de pousser ce nouveau travail dans une branche différente du serveur (appelée par exemple fonctionAv2).
Examinons un autre scénario possible : le mainteneur a revu les modifications dans votre seconde branche et apprécie le concept, mais il souhaiterait que vous changiez des détails d'implémentation.
Vous en profiterez pour rebaser ce travail sur le sommet actuel de la branche master du projet.
Vous démarrez une nouvelle branche à partir de la branche origin/master courante, y collez les modifications de fonctionB en résolvant les conflits, changez l'implémentation et poussez le tout en tant que nouvelle branche :
$ git checkout -b fonctionBv2 origin/master
$ git merge --no-commit --squash fonctionB
$ (changement d'implémentation)
$ git commit
$ git push macopie fonctionBv2
L'option --squash prend tout le travail de la branche à fusionner et le colle dans un commit sans fusion au sommet de la branche extraite.
L'option --no-commit indique à Git de ne pas enregistrer automatiquement une validation.
Cela permet de reporter toutes les modifications d'une autre branche, puis de réaliser d'autres modifications avant de réaliser une nouvelle validation.
À présent, vous pouvez envoyer au mainteneur un message indiquant que vous avez réalisé les modifications demandées et qu'il peut trouver cette nouvelle mouture sur votre branche fonctionBv2 (voir figure 5-18).
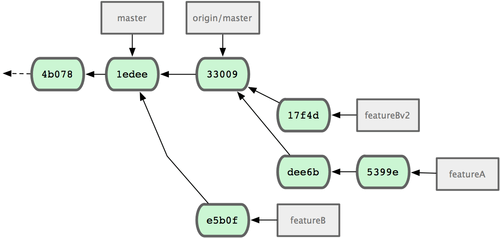
Figure 5-18. Historique des validations après le travail sur fonctionBv2.
Grand projet public
De nombreux grands projets ont des procédures établies pour accepter des patchs — il faut vérifier les règles spécifiques à chaque projet qui peuvent varier. Néanmoins, ils sont nombreux à accepter les patchs via une liste de diffusion de développement, ce que nous allons éclairer d'un exemple.
La méthode est similaire au cas précédent — vous créez une branche thématique par série de patchs sur laquelle vous travaillez. La différence réside dans la manière de les soumettre au projet. Au lieu de dupliquer le projet et de pousser vos soumissions sur votre dépôt, il faut générer des versions e-mail de chaque série de commits et les envoyer à la liste de diffusion de développement.
$ git checkout -b sujetA
$ (travail)
$ git commit
$ (travail)
$ git commit
Vous avez à présent deux commits que vous souhaitez envoyer à la liste de diffusion.
Vous utilisez git format-patch pour générer des fichiers au format mbox que vous pourrez envoyer à la liste.
Cette commande transforme chaque commit en un message e-mail dont le sujet est la première ligne du message de validation et le corps contient le reste du message plus le patch correspondant.
Un point intéressant de cette commande est qu'appliquer le patch à partir d'un e-mail formaté avec format-patch préserve toute l'information de validation comme nous le verrons dans le chapitre suivant lorsqu'il s'agira de l'appliquer.
$ git format-patch -M origin/master
0001-Ajout-d-une-limite-la-fonction-de-log.patch
0002-change-la-largeur-du-log-de-25-a-30.patch
La commande format-patch affiche les noms de fichiers de patch créés.
L'option -M indique à Git de suivre les renommages.
Le contenu des fichiers ressemble à ceci :
$ cat 0001-Ajout-d-une-limite-la-fonction-de-log.patch
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] Ajout d'une limite à la fonction de log
Limite la fonctionnalité de log aux 20 premières lignes
---
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index 76f47bc..f9815f1 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -14,7 +14,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log #{treeish}")
+ command("git log -n 20 #{treeish}")
end
def ls_tree(treeish = 'master')
--
1.6.2.rc1.20.g8c5b.dirty
Vous pouvez maintenant éditer ces fichiers de patch pour ajouter plus d'informations à destination de la liste de diffusion mais que vous ne souhaitez pas voir apparaître dans le message de validation.
Si vous ajoutez du texte entre la ligne --- et le début du patch (la ligne lib/simplegit.rb), les développeurs peuvent le lire mais l'application du patch ne le prend pas en compte.
Pour envoyer par e-mail ces fichiers, vous pouvez soit copier leur contenu dans votre application d'e-mail, soit l'envoyer via une ligne de commande.
Le copier-coller cause souvent des problèmes de formatage, spécialement avec les applications « intelligentes » qui ne préservent pas les retours à la ligne et les types d'espace.
Heureusement, Git fournit un outil pour envoyer correctement les patchs formatés via IMAP, la méthode la plus facile.
Je démontrerai comment envoyer un patch via Gmail qui s'avère être la boîte mail que j'utilise ; vous pourrez trouver des instructions détaillées pour de nombreuses applications de mail à la fin du fichier susmentionné Documentation/SubmittingPatches du code source de Git.
Premièrement, il est nécessaire de paramétrer la section imap de votre fichier ~/.gitconfig.
Vous pouvez positionner ces valeurs séparément avec une série de commandes git config, ou vous pouvez les ajouter manuellement.
À la fin, le fichier de configuration doit ressembler à ceci :
[imap]
folder = "[Gmail]/Drafts"
host = imaps://imap.gmail.com
user = user@gmail.com
pass = p4ssw0rd
port = 993
sslverify = false
Si votre serveur IMAP n'utilise pas SSL, les deux dernières lignes ne sont probablement pas nécessaires et le paramètre host commencera par imap:// au lieu de imaps://.
Quand c'est fait, vous pouvez utiliser la commande git send-email pour placer la série de patchs dans le répertoire Drafts du serveur IMAP spécifié :
$ git send-email *.patch
0001-Ajout-d-une-limite-la-fonction-de-log.patch
0002-change-la-largeur-du-log-de-25-a-30.patch
Who should the emails appear to be from? [Jessica Smith <jessica@example.com>]
Emails will be sent from: Jessica Smith <jessica@example.com>
Who should the emails be sent to? jessica@example.com
Message-ID to be used as In-Reply-To for the first email? y
La première question demande l'adresse e-mail d'origine (avec par défaut celle saisie en config), tandis que la seconde demande les destinataires. Enfin la dernière question sert à indiquer que l'on souhaite poster la série de patchs comme une réponse au premier patch de la série, créant ainsi un fil de discussion unique pour cette série. Ensuite, Git crache un certain nombre d'informations qui ressemblent à ceci pour chaque patch à envoyer :
(mbox) Adding cc: Jessica Smith <jessica@example.com> from
\line 'From: Jessica Smith <jessica@example.com>'
OK. Log says:
Sendmail: /usr/sbin/sendmail -i jessica@example.com
From: Jessica Smith <jessica@example.com>
To: jessica@example.com
Subject: [PATCH 1/2] Ajout d'une limite à la-fonction de log
Date: Sat, 30 May 2009 13:29:15 -0700
Message-Id: <1243715356-61726-1-git-send-email-jessica@example.com>
X-Mailer: git-send-email 1.6.2.rc1.20.g8c5b.dirty
In-Reply-To: <y>
References: <y>
Result: OK
À présent, vous devriez pouvoir vous rendre dans le répertoire Drafts, changer le champ destinataire pour celui de la liste de diffusion, y ajouter optionnellement en copie le mainteneur du projet ou le responsable et l'envoyer.
Résumé
Ce chapitre a traité quelques-unes des méthodes communes de gestion de types différents de projets Git que vous pourrez rencontrer et a introduit un certain nombre de nouveaux outils pour vous aider à gérer ces processus. Dans la section suivante, nous allons voir comment travailler de l'autre côté de la barrière : en tant que mainteneur de projet Git. Vous apprendrez comment travailler comme dictateur bienveillant ou gestionnaire d'intégration.