Revision Auswahl
Git erlaubt Dir, Commits auf verschiedenste Art und Weise auszuwählen. Diese sind nicht immer offensichtlich, aber es ist hilfreich diese zu kennen.
Einzelne Revisionen
Du kannst offensichtlich mithilfe des SHA-1-Hashes einen Commit auswählen, aber es gibt auch menschenfreundlichere Methoden, auf einen Commit zu verweisen. Dieser Bereich skizziert die verschiedenen Wege, die man gehen kann, um sich auf ein einzelnen Commit zu beziehen.
Abgekürztes SHA
Git ist intelligent genug, den richtigen Commit herauszufinden, wenn man nur die ersten paar Zeichen angibt, aber nur unter der Bedingung, dass der SHA-1-Hash mindestens vier Zeichen lang und einzigartig ist — das bedeutet, dass es nur ein Objekt im derzeitigen Repository gibt, das mit diesem bestimmten SHA-1-Hash beginnt.
Um zum Beispiel einen bestimmten Commit zu sehen, kann man das git log Kommando ausführen und den Commit identifizieren, indem man eine bestimmte Funktionalität hinzugefügt hat:
$ git log
commit 734713bc047d87bf7eac9674765ae793478c50d3
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 14:58:32 2008 -0800
added some blame and merge stuff
In diesem Fall wählt man 1c002dd...., wenn man diesen Commit mit git show anzeigen lassen will, die folgenden Kommandos sind äquivalent (vorausgesetzt die verkürzte Version ist einzigartig):
$ git show 1c002dd4b536e7479fe34593e72e6c6c1819e53b
$ git show 1c002dd4b536e7479f
$ git show 1c002d
Git kann auch selber eine Kurzform für Deine einzigartigen SHA-1-Werte erzeugen. Wenn Du --abbrev-commit dem git log Kommando übergibst, wird es den kürzeren Wert benutzen, diesen aber einzigartig halten; die Standardeinstellung sind sieben Zeichen, aber es werden automatisch mehr benutzt, wenn dies nötig ist, um den SHA-1-Hash eindeutig zu bezeichnen.
$ git log --abbrev-commit --pretty=oneline
ca82a6d changed the version number
085bb3b removed unnecessary test code
a11bef0 first commit
Generell kann man sagen, dass acht bis zehn Zeichen mehr als ausreichend in einem Projekt sind, um eindeutig zu bleiben. Eines der größten Git-Projekte, der Linux-Kernel, fängt langsam an 12 von maximal 40 Zeichen zu nutzen, um eindeutig zu bleiben.
Ein kurzer Hinweis zu SHA-1
Eine Menge Leute machen sich Sorgen, dass ab einem zufälligen Punkt zwei Objekte im Repository vorhanden sind, die den gleichen SHA-1-Hashwert haben. Was dann?
Wenn es passiert, dass bei einem Commit, ein Objekt mit dem gleichen SHA-1-Hashwert im Repository vorhanden ist, wird Git sehen, dass das vorherige Objekt bereits in der Datenbank vorhanden ist und davon ausgehen, dass es bereits geschrieben wurde. Wenn Du versuchst, das Objekt später wieder auszuchecken, wirst Du immer die Daten des ersten Objekts bekommen.
Allerdings solltest Du Dir bewusst machen, wie unglaublich unwahrscheinlich dieses Szenario ist. Die Länge des SHA-1-Hashs beträgt 20 Bytes oder 160 Bits. Die Anzahl der Objekte, die benötigt werden, um eine 50% Chance einer Kollision zu haben, beträgt ungefähr 2^80 (die Formel zum Berechnen der Kollisionswahrscheinlichkeit lautet p = (n(n-1)/2) * (1/2^160)). 2^80 ist somit 1.2 x 10^24 oder eine Trilliarde. Das ist 1200 Mal so viel, wie es Sandkörner auf der Erde gibt.
Hier ist ein Beispiel, das Dir eine Vorstellung davon gibt, was nötig ist, um in SHA-1 eine Kollision zu bekommen. Wenn alle 6,5 Milliarden Menschen auf der Erde programmieren würden und jeder jede Sekunde Code schreiben würde, der der gesamten Geschichte des Linux-Kernels (1 Million Git-Objekte) entspricht, und diesen dann in ein gigantisches Git-Repository übertragen würde, würde es fünf Jahre dauern, bis das Repository genügend Objekte hätte, um eine 50% Wahrscheinlichkeit für eine einzige SHA-1-Kollision aufzuweisen. Es ist wahrscheinlicher, dass jedes Mitglied Deines Programmierer-Teams, unabhängig voneinander, in einer Nacht von Wölfen angegriffen und getötet wird.
Branch-Referenzen
Am direktesten kannst Du einen Commit spezifizieren, wenn eine Branch-Referenz direkt auf ihn zeigt. In dem Fall kannst Du in allen Git-Befehlen, die ein Commit-Objekt oder einen SHA-1-Wert erwarten, stattdessen den Branch-Namen verwenden. Wenn Du z.B. den letzten Commit in einem Branch sehen willst, sind die folgenden Befehle äquivalent (vorausgesetzt der topic1 Branch zeigt auf den Commit ca82a6d):
$ git show ca82a6dff817ec66f44342007202690a93763949
$ git show topic1
Wenn Du sehen willst, auf welchen SHA-1-Wert ein Branch zeigt, oder wie unsere Beispiele intern in SHA-1-Werte übersetzt aussähen, kannst Du den Git-Plumbing-Befehl rev-parse verwenden. In Kapitel 9 werden wir genauer auf Plumbing-Befehle eingehen. Kurz gesagt ist rev-parse als eine Low-Level-Operation gedacht und nicht dafür, im tagtäglichen Gebrauch eingesetzt zu werden. Aber es kann manchmal hilfreich sein, wenn man wissen muss, was unter der Haube vor sich geht:
$ git rev-parse topic1
ca82a6dff817ec66f44342007202690a93763949
RefLog Kurznamen
Eine andere Sache, die während Deiner täglichen Arbeit im Hintergrund passiert ist, dass Git ein sogenanntes Reflog führt, d.h. ein Log darüber, wohin Deine HEAD- und Branch-Referenzen in den letzten Monaten jeweils gezeigt haben.
Du kannst das Reflog mit git reflog anzeigen:
$ git reflog
734713b... HEAD@{0}: commit: fixed refs handling, added gc auto, updated
d921970... HEAD@{1}: merge phedders/rdocs: Merge made by recursive.
1c002dd... HEAD@{2}: commit: added some blame and merge stuff
1c36188... HEAD@{3}: rebase -i (squash): updating HEAD
95df984... HEAD@{4}: commit: # This is a combination of two commits.
1c36188... HEAD@{5}: rebase -i (squash): updating HEAD
7e05da5... HEAD@{6}: rebase -i (pick): updating HEAD
Immer dann, wenn ein Branch in irgendeiner Weise aktualisiert wird oder Du den aktuellen Branch wechselst, speichert Git diese Information ebenso im Reflog wie Commits und anderen Informationen. Wenn Du wissen willst, welches der fünfte Wert vor dem HEAD war, kannst Du die @{n} Referenz angeben, die Du in Reflog-Ausgabe sehen kannst:
$ git show HEAD@{5}
Außerdem kannst Du dieselbe Syntax verwenden, um eine Zeitspanne anzugeben. Um z.B. zu sehen, wo Dein master Branch gestern war, kannst Du eingeben:
$ git show master@{yesterday}
Das zeigt Dir, wo der master Branch gestern war. Diese Technik funktioniert nur mit Daten, die noch im Reflog sind, d.h. man kann sie nicht für Commits verwenden, die ein älter sind als ein paar Monate.
Um Reflog Informationen in einem Format wie in git log anzeigen, kannst Du git log -g verwenden:
$ git log -g master
commit 734713bc047d87bf7eac9674765ae793478c50d3
Reflog: master@{0} (Scott Chacon <schacon@gmail.com>)
Reflog message: commit: fixed refs handling, added gc auto, updated
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Jan 2 18:32:33 2009 -0800
fixed refs handling, added gc auto, updated tests
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Reflog: master@{1} (Scott Chacon <schacon@gmail.com>)
Reflog message: merge phedders/rdocs: Merge made by recursive.
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
Es ist wichtig zu verstehen, dass das Reflog ausschließlich lokale Daten enthält. Es ist ein Log darüber, was Du in Deinem Repository getan hast, und es ist nie dasselbe wie in einem anderen Klon des selben Repositorys. Direkt nachdem Du ein Repository geklont hast, ist das Reflog leer, weil noch keine weitere Aktivität stattgefunden hat. git show HEAD@{2.months.ago} funktioniert nur dann, wenn das Projekt mindestens zwei Monate alt ist – wenn Du es vor fünf Minuten erst geklont hast, erhältst Du keine Ergebnisse.
Vorfahren Referenzen
Außerdem kann man Commits über ihre Vorfahren spezifizieren. Wenn Du ein ^ ans Ende einer Referenz setzt, schlägt Git den direkten Vorfahren dieses Commits nach. Nehmen wir an, Deine Historie sieht so aus:
$ git log --pretty=format:'%h %s' --graph
* 734713b fixed refs handling, added gc auto, updated tests
* d921970 Merge commit 'phedders/rdocs'
|\
| * 35cfb2b Some rdoc changes
* | 1c002dd added some blame and merge stuff
|/
* 1c36188 ignore *.gem
* 9b29157 add open3_detach to gemspec file list
Du kannst jetzt den vorletzten Commit mit HEAD^ referenzieren, d.h. „den direkten Vorfahren von HEAD“.
$ git show HEAD^
commit d921970aadf03b3cf0e71becdaab3147ba71cdef
Merge: 1c002dd... 35cfb2b...
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 15:08:43 2008 -0800
Merge commit 'phedders/rdocs'
Außerdem kannst Du nach dem ^ eine Zahl angeben. Beispielsweise heißt d921970^2: „der zweite Vorfahr von d921970“. Diese Syntax ist allerdings nur für Merge Commits nützlich, die mehr als einen Vorfahren haben. Der erste Vorfahr ist der Branch, auf dem Du Dich beim Merge befandest, der zweite ist der Commit auf dem Branch, den Du gemergt hast.
$ git show d921970^
commit 1c002dd4b536e7479fe34593e72e6c6c1819e53b
Author: Scott Chacon <schacon@gmail.com>
Date: Thu Dec 11 14:58:32 2008 -0800
added some blame and merge stuff
$ git show d921970^2
commit 35cfb2b795a55793d7cc56a6cc2060b4bb732548
Author: Paul Hedderly <paul+git@mjr.org>
Date: Wed Dec 10 22:22:03 2008 +0000
Some rdoc changes
Eine andere Vorfahren-Spezifikation ist ~. Dies bezieht sich ebenfalls auf den ersten Vorfahren, d.h. HEAD~ und HEAD^ sind äquivalent. Einen Unterschied macht es allerdings, wenn Du außerdem eine Zahl angibst. HEAD~2 bedeutet z.B. „der Vorfahr des Vorfahren von HEAD“ oder „der n-te Vorfahr von HEAD“. Beispielsweise würde HEAD~3 in der obigen Historie auf den folgenden Commit zeigen:
$ git show HEAD~3
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <tom@mojombo.com>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gem
Dasselbe kannst Du mit HEAD^^^ angeben, was wiederum den „Vorfahren des Vorfahren des Vorfahren“ referenziert:
$ git show HEAD^^^
commit 1c3618887afb5fbcbea25b7c013f4e2114448b8d
Author: Tom Preston-Werner <tom@mojombo.com>
Date: Fri Nov 7 13:47:59 2008 -0500
ignore *.gem
Du kannst diese Schreibweisen auch kombinieren und z.B. auf den zweiten Vorfahren der obigen Referenz mit HEAD~3^2 zugreifen.
Commit Reihen
Nachdem Du jetzt einzelne Commits spezifizieren kannst, schauen wir uns an, wie man auf Commit-Reihen zugreift. Dies ist vor allem nützlich, um Branches zu verwalten, z.B. wenn man viele Branches hat und solche Fragen beantworten will wie „Welche Änderungen befinden sich in diesem Branch, die ich noch nicht in meinen Hauptbranch gemergt habe?“.
Zwei-Punkte-Syntax
Die gängigste Weise, Commit-Reihen anzugeben, ist die Zwei-Punkte-Notation. Allgemein gesagt liefert Git damit eine Reihe von Commits, die von dem einem Commit aus erreichbar sind, allerdings nicht von dem anderen aus. Nehmen wir z.B. an, Du hättest eine Commit-Historie wie die folgende (Bild 6-1).
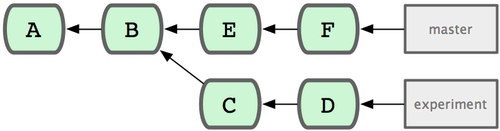
Du willst jetzt herausfinden, welche Änderungen in Deinem experiment-Branch sind, die noch nicht in den master-Branch gemergt wurden. Dann kannst Du ein Log dieser Commits mit master..experiment anzeigen, d.h. „alle Commits, die von experiment aus erreichbar sind, aber nicht von master“. Um die folgenden Beispiele ein bisschen abzukürzen und deutlicher zu machen, verwende ich für die Commit-Objekte die Buchstaben aus dem Diagramm anstelle der tatsächlichen Log Ausgabe:
$ git log master..experiment
D
C
Wenn Du allerdings – anders herum – diejenigen Commits anzeigen willst, die in master, aber noch nicht in experiment sind, kannst Du die Branch-Namen umdrehen: experiment..master zeigt „alles in master, das nicht in experiment enthalten ist“.
$ git log experiment..master
F
E
Dies ist nützlich, wenn Du vorhast, den experiment-Branch zu aktualisieren, und anzeigen willst, was Du dazu mergen wirst. Oder wenn Du vorhast, in ein Remote-Repository zu pushen und sehen willst, welche Commits betroffen sind:
$ git log origin/master..HEAD
Dieser Befehl zeigt Dir alle Commits im gegenwärtigen, lokalen Branch, die noch nicht im master-Branch des origin Repositorys sind. D.h., der Befehl listet diejenigen Commits auf, die auf den Server transferiert würden, wenn Du git push benutzt und der aktuelle Branch origin/master trackt. Du kannst mit dieser Syntax außerdem eine Seite der beiden Punkte leer lassen. Git nimmt dann an, Du meinst an dieser Stelle HEAD. Z.B. kannst Du dieselben Commits wie im vorherigen Beispiel auch mit git log origin/master.. anzeigen lassen. Git fügt dann HEAD auf der rechten Seite ein.
Mehrere Bezugspunkte
Die Zwei-Punkte-Syntax ist eine nützliche Abkürzung, aber möglicherweise willst Du mehr als nur zwei Branches angeben, um z.B. herauszufinden, welche Commits in einem beliebigen anderen Branch enthalten sind, ausgenommen in demjenigen, auf dem Du Dich gerade befindest. Dazu kannst Du in Git das ^ Zeichen oder --not verwenden, um Commits auszuschließen, die von den angegebenen Referenzen aus erreichbar sind. D.h., die folgenden drei Befehle sind äquivalent:
$ git log refA..refB
$ git log ^refA refB
$ git log refB --not refA
Das ist praktisch, weil Du auf diese Weise mehr als nur zwei Referenzen angeben kannst, was mit der Zwei-Punkte-Notation nicht geht. Wenn Du beispielsweise alle Commits sehen willst, die von refA oder refB erreichbar sind, nicht aber von refC, dann kannst Du folgende (äquivalente) Befehle benutzen:
$ git log refA refB ^refC
$ git log refA refB --not refC
Damit hast Du ein sehr mächtiges System von Abfragen zur Verfügung, mit denen Du herausfinden kannst, was in welchen Deiner Branches enthalten ist.
Drei-Punkte-Syntax
Die letzte wichtige Syntax, mit der man Commit-Reihen spezifizieren kann, ist die Drei-Punkte-Syntax, die alle Commits anzeigt, die in einer der beiden Referenzen enthalten sind, aber nicht in beiden. Schau Dir noch mal die Commit Historie in Bild 6-1 an. Wenn Du diejenigen Commits anzeigen willst, die in den master- und experiment-Branches, nicht aber in beiden Branches gleichzeitig enthalten sind, dann kannst Du folgendes tun:
$ git log master...experiment
F
E
D
C
Dies gibt Dir wiederum ein normale log Ausgabe, aber zeigt nur die Informationen dieser vier Commits – wie üblich sortiert nach dem Commit-Datum.
Eine nützliche Option für den log Befehl ist in diesem Fall --left-right. Sie zeigt Dir an, in welchem der beiden Branches der jeweilige Commit enthalten ist, sodass die Ausgabe noch nützlicher ist:
$ git log --left-right master...experiment
< F
< E
> D
> C
Mit diesen Hilfsmitteln kannst Du noch einfacher und genauer angeben, welche Commits Du nachschlagen willst.