Git Objekte
Git ist ein Dateisystem, das Inhalte addressieren kann. Prima. Aber was heißt das? Es bedeutet, dass Git im Kern nichts anderes ist als ein einfacher Key-Value-Store („Schlüssel-Wert-Speicher“). Du kannst darin jede Art von Inhalt ablegen und Git wird einen Schlüssel dafür zurückgeben, den Du dann verwenden kannst, um diesen Inhalt jederzeit nachzuschlagen. Um das auszuprobieren, kannst Du den Plumbing-Befehl hash-object verwenden. Dieser nimmt Daten entgegen, speichert diese in Deinem .git-Verzeichnis und gibt Dir den Schlüssel zurück, unter dem der Inhalt gespeichert wurde. Dazu initialisierst Du als erstes ein neues Git-Repository und verifizierst, dass das objects-Verzeichnis leer ist:
$ mkdir test
$ cd test
$ git init
Initialized empty Git repository in /tmp/test/.git/
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type f
$
Git hat also ein Verzeichnis objects und darin die Unterverzeichnisse pack und info angelegt, bisher aber keine weiteren Dateien. Als nächsten speichern wir einen Text in dieser Git-Datenbank:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4
Die Option -w weist git hash-object an, das Objekt zu speichern. Andernfalls würde Dir der Befehl lediglich den Schlüssel mitteilen. --stdin weist den Befehl an, den Inhalt von der Standardeingabe einzulesen. Wenn Du diese Option weglässt, erwartet der Befehl zusätzlich einen Dateipfad. Die Ausgabe ist ein 40 Zeichen langer SHA-1-Hash, der eine Prüfsumme des gespeicherten Inhaltes darstellt (wir gehen auf diese Hashes gleich noch genauer ein). Git hat jetzt außerdem eine neue Datei in der Datenbank angelegt:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
Jetzt liegt im Verzeichnis objects genau eine Datei. Anfangs speichert Git den Inhalt auf diese Art und Weise: In jeweils einer einzelnen Datei werden die Daten gespeichert, referenziert durch den SHA-1-Hash des Inhaltes und seines Headers. Der Name des Unterverzeichnis d6 entspricht den ersten zwei Zeichen des SHA-1-Hashes. Die verbleibenden 38 Zeichen werden als Dateiname verwendet.
Mit dem Befehl git cat-file kannst Du den jeweiligen Inhalt nachschlagen. Dieser Befehl ist so etwas wie ein Schweizer Taschenmesser, wenn es um Objekte in der Git-Datenbank geht. Wenn Du die Option -p übergibst, versucht git cat-file, die Art des Inhaltes herauszufinden und lesbar darzustellen:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content
Auf diese Weise kannst Du also Inhalte zu Git hinzufügen und von dort wieder auslesen. Das klappt auch mit Dateiinhalten. Wenn Du beispielsweise eine einzelne Datei versionieren willst, legst Du dazu die Datei zunächst an und speicherst ihren Inhalt in der Datenbank:
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30
Dann kannst Du Änderungen vornehmen und die Datei erneut speichern:
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
Die Datenbank enthält jetzt zwei weitere Versionen der Datei neben dem ursprünglich gespeicherten Inhalt:
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
Jetzt kannst Du die erste Version der Datei mit folgendem Befehl wieder herstellen:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1
Oder die zweite Version:
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2
Sich den SHA-1-Hash für jede Version merken zu müssen, ist allerdings nicht sonderlich praktisch. Außerdem speicherst Du nicht den Dateinamen in der Datenbank, sondern lediglich den Inhalt der Datei. Ein solcher Objekttyp wird als „Blob“ bezeichnet. Mit git cat-file -t kannst Du Git nach dem Typ eines Objektes in der Datenbank fragen:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blob
Baum-Objekte
Als Nächstes schauen wir uns den Objekttyp „Tree“ (Baum) an, der es ermöglicht, Dateinamen zu speichern und Dateien zu gruppieren. Git speichert Inhalte in einer ähnlichen Weise wie das UNIX-Dateisystem, allerdings ein bisschen vereinfacht. Sie werden als Tree- und Blob-Objekte abgelegt, wobei die Trees mit UNIX-Verzeichnis-Einträgen korrespondieren und Blobs mehr oder weniger mit den Inode-Einträgen bzw. Datei-Inhalten. Ein einzelnes Baum-Objekt enthält einen oder mehrere Einträge, von denen jeder ein SHA-1-Hash ist, der wiederum einen Blob oder einen Untertree referenziert. Jeder dieser Einträge verfügt außerdem über einen Modus, Typ und Dateinamen. Beispielsweise sieht das aktuelle Tree-Objekt im simplegit-Projekt möglicherweise so aus:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 lib
Die master^{tree}-Syntax spezifiziert, dass wir an dem Tree-Objekt interessiert sind, auf das der letzte Commit des Branches master zeigt. Beachte, dass das Unterverzeichnis lib nicht auf ein Blob, sondern wiederum auf einen weiteren Baum zeigt.
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb
Git speichert Daten also, konzeptuell gesehen, in etwa wie in Bild 9-1 dargestellt.
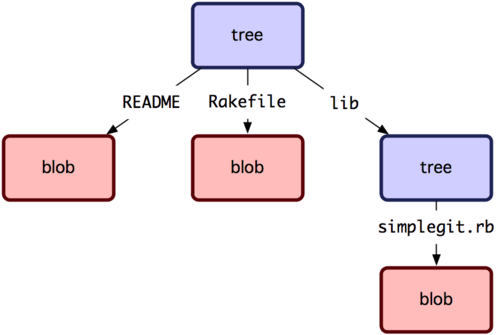
Bild 9-1. Vereinfachte Darstellung des Git-Datenmodels.
Du kannst auch Deine eigenen Tree-Objekte anlegen. Git erzeugt Trees normalerweise, indem es die Inhalte der Staging-Area nimmt und als ein Tree-Objekt speichert. D.h., um ein Tree-Objekt anzulegen, musst Du zunächst einen Index (d.h. eine Staging-Area) aufbauen, indem Du einige Dateien hinzufügst. Um einen einzelnen Eintrag in den Index zu schreiben – z.B. die erste version der Datei test.txt – kannst Du den Plumbing-Befehl git update-index verwenden, der eine frühere Version dieser Datei künstlich zu einer neuen Staging-Area hinzufügt. Du musst ihm die Option --add übergeben, weil die Datei bisher noch nicht in der Staging-Area enthalten ist (Du hast ja bisher noch überhaupt keine Staging-Area aufgesetzt), und die Option --cacheinfo, weil Du eine Datei hinzufügst, die sich nicht in Deinem Verzeichnis befindet, sondern in der Datenbank. Du gibst außerdem den Modus, SHA-1-Hash und den Dateinamen an:
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txt
In diesem Fall gibst Du als Modus 100644 an, was bedeutet, dass es sich um eine normale Datei handelt. Eine ausführbare Datei wäre dagegen 100755 und ein symbolischer Link 120000. Der Modus entspricht normalen UNIX-Datei-Modi, ist aber weniger flexibel. Die drei genannten Modi sind die einzigen, die in Git für Dateien (Blobs) verwendet werden (es gibt allerdings noch weitere Modi für Verzeichnisse und Submodule).
Jetzt kannst Du den Befehl git write-tree verwenden, um die Staging-Area als Tree-Objekt zu schreiben. Dazu brauchst Du die -w Option nicht angeben – git write-tree schreibt automatisch ein Tree-Objekt für Einträge der Staging-Area, für die es noch keinen Tree gibt:
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
Um zu überprüfen, ob es sich wirklich um ein Tree-Objekt handelt:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
tree
Jetzt erzeugen wir einen neuen Tree mit der zweiten Version der Datei test.txt sowie einer neuen Datei:
$ echo 'new file' > new.txt
$ git update-index test.txt
$ git update-index --add new.txt
Die Staging-Area enthält jetzt eine neue Version der Datei test.txt sowie die neue Datei new.txt. Speichern wir diesen Tree (d.h. den gegenwärtigen Status der Staging-Area bzw. des Index als Tree-Objekt) und schauen ihn uns an:
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
Beachte, dass das Tree-Objekt beide Datei-Einträge hat und dass der SHA-1-Hash der Datei test.txt noch derselbe „Version 2“-Hash ist wie zuvor (1f7a7a). Fügen wir jetzt den ersten Tree als ein Unterverzeichnis in diesem hier ein. Du kannst einen Tree mit git read-tree in die Staging-Area einlesen. In diesem Fall können wir einen bereits existierenden Tree als einen Untertree zur Staging-Area hinzufügen, indem wir die Option --prefix verwenden:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
Wenn Du ein Arbeitsverzeichnis aus diesem neuen Tree-Objekt auschecken würdest, würdest Du zwei Dateien im Hauptverzeichnis und ein Unterverzeichnis mit dem Namen bak erhalten, in dem sich die erste Version der Datei test.txt befindet. Du kannst Dir die Daten, die Git für diese Strukturen speichert, in etwa wie in Bild 9-2 vorstellen.
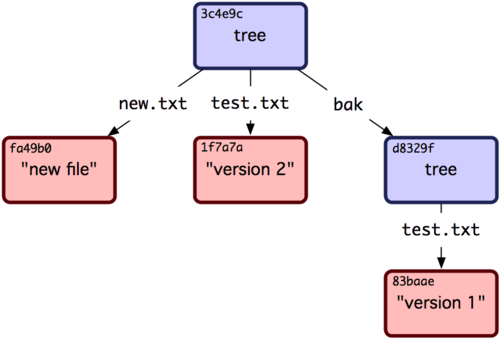
Bild 9-2. Die Datenstruktur des gegenwärtigen Git-Repositorys.
Objekte committen
Du hast jetzt drei Trees, die verschiedene Snapshots Deines Projektes spezifizieren, die Du nachverfolgen willst. Das ursprüngliche Problem besteht aber weiterhin: Du musst Dir alle drei SHA-1-Hashwerte merken, um wieder an die Snapshots zu kommen. Ebenso fehlen Dir die Informationen darüber, wer die Snapshots gespeichert hat, wann sie gespeichert wurden und warum. Dies sind die drei Hauptinformationen, die ein Commit-Objekt für uns speichert.
Um ein Commit-Objekt anzulegen, verwendest Du den Befehl git commit-tree, spezifizierst den SHA-1-Hash eines einzelnen Trees und welche Commit-Objekte (sofern vorhanden) die direkten Vorgänger sind. Fangen wir damit an, den ersten Tree, den Du angelegt hast, einzuchecken:
$ echo 'first commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Du kannst Dir dann dieses neue Commit-Objekt mit cat-file anschauen:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
first commit
Das Format für ein Commit-Objekt ist einfach: es besteht aus dem obersten Tree für den Snapshot des Projektes zum gegebenen Zeitpunkt, die Autoren- und ggf. Committer-Information (jeweils entsprechend Deiner user.name- und user.email-Konfiguration) und dem aktuellen Zeitstempel. Dann folgen eine leere Zeile und die Commit-Nachricht.
Als Nächstes speichern wir die beiden anderen Commit-Objekte und referenzieren jeweils den vorhergehenden Commit:
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9
Jedes der drei Commit-Objekte zeigt auf einen der drei Snapshot-Trees, die Du zuvor gespeichert hattest. Es mag Dich überraschen, aber Du hast jetzt bereits eine vollständige Git-Historie, die Du mit dem Befehl git log inspizieren kannst, indem Du den SHA-1-Hash des letzten Commits angibst:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletions(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
Fantastisch, oder? Du hast jetzt sämtliche Low-Level-Operationen durchgeführt, die eine vollständige Git-Historie aufbauen, ohne aber irgendwelche Frontend-Befehle von Git zu verwenden. Im Wesentlichen ist das derselbe Prozess, der im Hintergrund stattfindet, wenn Du die Befehle git add und git commit ausführst. Sie speichern Blobs für die Dateien, die Du hinzugefügt oder geändert hast, aktualisieren den Index (d.h. die Staging-Area), speichern Trees und legen Commit Objekte an, die die obersten Trees sowie die Commits referenzieren, die ihnen unmittelbar vorhergingen. Diese drei Hauptobjekte – Blob, Tree und Commit – werden zunächst als separate Dateien im Verzeichnis .git/objects gespeichert. Hier ist eine Liste aller Objekte, die sich in unserem Beispiel-Repository jetzt in der Datenbank befinden – jeweils mit einem Kommentar darüber, was sie speichern:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1
Wenn man all diese internen Zeiger nachverfolgt, erhält man einen Objekt-Graphen wie den folgenden (Bild 9-3).
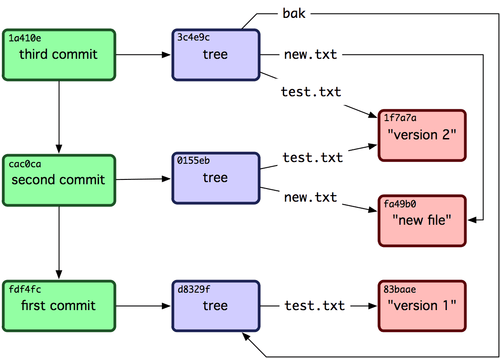
Bild 9-3. Alle Objekte in Deinem Git-Repository.
Objekt-Speicher
Ich habe bereits erwähnt, dass zusammen mit dem jeweiligen Inhalt ein Header gespeichert wird. Schauen wir uns also genauer an, wie genau Git Objekte speichert. Du wirst sehen, wie ein Blob-Objekt – in diesem Fall die Zeichenkette „what is up, doc?“ gespeichert wird. Dazu nutzen wir den interaktiven Ruby-Modus, den Du mit dem Befehl irb starten kannst:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"
Git erzeugt einen Header, der mit dem Objekttyp beginnt, in diesem Fall ist das ein Blob. Dann folgt ein Leerzeichen, die Anzahl der Zeichen des Inhalts und schließlich ein Nullbyte.
>> header = "blob #{content.length}\0"
=> "blob 16\000"
Git fügt diesen Header mit dem ursprünglichen Inhalt zusammen und kalkuliert aus dem Ergebnis die SHA-1-Prüfsumme. Du kannst einen SHA-1-Hash in Ruby berechnen, indem Du die SHA1-Digest-Bibliothek mit require einbindest und dann Digest::SHA1.hexdigest() mit der Zeichenkette ausführst:
>> store = header + content
=> "blob 16\000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"
Git komprimiert den neuen Inhalt (d.h. inklusive des Headers) mit zlib. In Ruby kannst Du dazu die zlib-Bibliothek verwenden, indem Du wiederum zuerst die Bibliothek mit require einbindest und dann Zlib::Deflate.deflate() mit dem Inhalt aufrufst:
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\234K\312\311OR04c(\317H,Q\310,V(-\320QH\311O\266\a\000_\034\a\235"
Schließlich schreibst Du den zlib-komprimierten Inhalt in eine Datei auf der Festplatte. Dazu bestimmst Du den Pfad, an den die Datei gespeichert wird (die ersten beiden Zeichen für das Unterverzeichnis und die verbleibenden 38 Zeichen für den Dateinamen). In Ruby kannst Du die Funktion FileUtils.mkdir_p() verwenden, um Unterverzeichnisse anzulegen, die noch nicht existieren. Dann öffnest Du die Datei mit File.open() und schreibst den komprimierten Inhalt mit write() in die Datei:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32
Das ist alles – Du hast jetzt ein gültiges Blob-Objekt geschrieben. Git-Objekte werden immer in dieser Weise gespeichert, lediglich mit verschiedenen Typen, d.h. anstelle der Zeichenkette „blob“ wird der Header mit „commit“ oder „tree“ anfangen. Außerdem sind Commit- und Tree-Inhalte auf eine sehr spezifische Weise formatiert, während Blobs beliebige Inhalte sein können.