An einem Projekt mitarbeiten
Du kennst jetzt einige grundlegende Workflow Varianten, und Du solltest ein gutes Verständnis im Umgang mit grundlegenden Git Befehlen haben. In diesem Abschnitt lernst Du wie Du an einem Projekt mitzuarbeiten kannst.
Diesen Prozess zu beschreiben ist nicht leicht, weil es so viele Variationen gibt. Git ist so unheimlich flexibel, dass Leute auf vielen unterschiedlichen Wegen zusammenarbeiten können, und es ist problematisch, zu erklären, wie Du arbeiten solltest, weil jedes Projekt ein bisschen anders ist. Zu den Variablen gehören: die Anzahl der aktiven Mitarbeiter, der Workflow des Projektes, Deine Commit Rechte und möglicherweise eine vorgeschriebene, externe Methode, Änderungen einzureichen.
Wie viele Mitarbeiter tragen aktive Code zum Projekt bei? Und wie oft? In vielen Fällen findest Du zwei oder drei Entwickler, die täglich einige Commits anlegen, möglicherweise weniger in eher (xxx dormant xxx) Projekten. In wirklich großen Unternehmen oder Projekten können tausende Entwickler involviert sein und täglich dutzende oder sogar hunderte von Patches produzieren. Mit so vielen Mitarbeitern ist es aufwendiger, sicher zu stellen, dass Änderungen sauber mit der Codebase zusammengeführt werden können. Deine Änderungen könnten sich als überflüssig oder dysfunktional (xxx) erweisen, nachdem andere Änderungen übernommen wurden, seit Du angefangen hast, an Deinen eigenen zu arbeiten oder während sie darauf warteten, geprüft und eingefügt (xxx) zu werden.
Die nächste Variable ist der Workflow, der in diesem Projekt besteht. Ist es ein zentralisierter Workflow, in dem jeder Entwickler Schreibzugriff auf die Hauptentwicklungslinie hat? Hat das Projekt einen Leiter oder Integration Manager, der alle Patches prüft? Werden die Patches durch eine bestimmte Gruppe oder öffentlich, z.B. durch die Community, geprüft? Nimmst Du selbst an diesem Prozess teil? Gibt es ein Leutnant System, in dem Du Deine Arbeit zunächst an einen Leutnant übergibst?
Eine weitere Frage ist, welche Commit Rechte Du hast. Wenn Du Schreibrechte hast, sieht der Arbeitsablauf, mit dem Du Änderungen beisteuern kannst, natürlich völlig anders aus, als wenn Du nur Leserechte hast. Und in letzterem Fall: in welcher Form werden Änderungen in diesem Projekt akzeptiert? Gibt es dafür überhaupt eine Richtlinie? Wie umfangreich sind die Änderungen, die Du jeweils beisteuerst? Und wie oft tust Du das?
Die Antworten auf diese Fragen können maßgeblich beeinflussen, wie Du effektiv an einem Projekt mitarbeiten kannst und welche Workflows Du zur Auswahl hast. Wir werden verschiedene Aspekte davon in einer Reihe von Fallbeispielen besprechen, wobei wir mit simplen Beispielen anfangen und später komplexere Szenarios besprechen. Du wirst hoffentlich in der Lage sein, aus diesen Beispielen einen eigenen Workflow zu konstruieren, der Deinen Anforderungen entspricht.
Commit Richtlinien
Bevor wir uns verschiedene konkrete Fallbeispiele ansehen, einige kurze Anmerkungen über Commit Meldungen. Gute Richtlinien für Commit Meldungen zu haben und sich danach zu richten, macht die Zusammenarbeit mit anderen und die Arbeit mit Git selbst sehr viel einfacher. Im Git Projekt gibt es ein Dokument mit einer Reihe nützlicher Tipps für das Anlegen von Commits, aus denen man Patches erzeugen will. Schaue im Git Quellcode nach der Datei Documentation/SubmittingPatches.
Zunächst einmal solltest Du keine Whitespace Fehler (xxx) comitten:
$ git diff --check
lib/simplegit.rb:5: trailing whitespace.
+ @git_dir = File.expand_path(git_dir)XX
lib/simplegit.rb:7: trailing whitespace.
+ XXXXXXXXXXX
lib/simplegit.rb:26: trailing whitespace.
+ def command(git_cmd)XXXX
Wenn Du diesen Befehl ausführst, bevor Du einen Commit anlegst, warnt er dich, falls in Deinen Änderungen Whitespace Probleme vorliegen, die andere Entwickler ärgern könnten.
Versuche außerdem, Deine Änderungen in logisch zusammenhängende Einheiten zu gruppieren. Wenn möglich, versuche Commits möglichst leichtverständlich (xxx) zu gestalten: arbeite nicht ein ganzes Wochenende lang an fünf verschiedenen Problemen und committe sie dann am Montag als einen einzigen, riesigen Commit. Selbst wenn Du am Wochenende keine Commits angelegt hast, verwende die Staging Area, um Deine Änderungen auf mehrere Commits aufzuteilen, jeweils mit einer verständlichen Meldung. Wenn einige Änderungen dieselbe Datei betreffen, probiere sie mit git add --patch nur teilweise zur Staging Area hinzuzufügen (das werden wir in Kapitel 6 noch im Detail besprechen). Der Projekt Snapshot wird am Ende derselbe sein, ob Du nun einen einzigen großen oder mehrere kleine Commits anlegst, daher versuche, es anderen Entwickler zu erleichtern machen, Deine Änderungen zu verstehen. Auf diese Weise machst Du es auch einfacher, einzelne Änderungen später herauszunehmen oder rückgängig zu machen. Kapitel 6 beschreibt eine Reihe nützlicher Git Tricks, die hilfreich sind, um die Historie umzuschreiben oder interaktiv Dateien zur Staging Area hinzuzufügen. Verwende diese Hilfsmittel, um eine sauber und leicht verständliche Historie von Änderungen aufzubauen.
Ein weitere Sache, der Du ein bisschen Aufmerksamkeit schenken solltest, ist die Commit Meldung selbst. Wenn man sich angewöhnt, aussagekräftige und hochwertige Commit Meldungen zu schreiben, macht man sich selbst und anderen das Leben erheblich einfacher. Im allgemeinen sollte eine Commit Meldung mit einer einzelnen Zeile anfangen, die nicht länger als 50 Zeichen sein sollte. Dann sollte eine leere Zeile folgen und schließlich eine ausführlichere Beschreibung der Änderungen.
Short (50 chars or less) summary of changes
More detailed explanatory text, if necessary. Wrap it to about 72
characters or so. In some contexts, the first line is treated as the
subject of an email and the rest of the text as the body. The blank
line separating the summary from the body is critical (unless you omit
the body entirely); tools like rebase can get confused if you run the
two together.
Further paragraphs come after blank lines.
- Bullet points are okay, too
- Typically a hyphen or asterisk is used for the bullet, preceded by a
single space, with blank lines in between, but conventions vary here
Wenn Du Deine Commit Meldungen in dieser Weise formatierst, kannst Du Dir und anderen eine Menge Ärger ersparen. Das Git Projekt selbst hat wohl-formatierte Commit Meldungen. Wir empfehlen, einmal git log --no-merges in diesem Repository auszuführen, um einen Eindruck zu erhalten, wie eine gute Commit History eines Projektes aussehen kann.
In den folgenden Beispielen hier und fast überall in diesem Buch verwende ich keine derartigen, schön formatierten Meldungen. Stattdessen verwende ich die -m Option zusammen mit git commit. Also folge meinen Worten, nicht meinem Beispiel.
Kleine Teams
Das einfachste Setup, mit dem Du zu tun haben wirst, ist ein privates Projekt mit ein oder zwei Entwicklern. Mit „privat“ meine ich, dass es „closed source“, d.h. nicht lesbar für Dritte ist. Alle beteiligten Entwickler haben Schreibzugriff auf das Repository.
In einer solchen Umgebung kann man einen ähnlichen Workflow verwenden, wie für Subversion oder ein anderes zentralisiertes System. Du hast dann immer noch Vorteile wie, dass Du offline committen kannst und dass Branching und Merging so unglaublich einfach ist. Der Hauptunterschied ist, dass Merges auf der Client Seite stattfinden und nicht, wenn man committet, auf dem Server. Schauen wir uns an, wie die Arbeit von zwei Entwicklern in einem gemeinsamen Repository abläuft. Der erste Entwickler, John, klont das Repository, nimmt eine Änderung vor und comittet auf seinem Rechner. (Wir kürzen die Beispiele etwas ab und ersetzen die hierfür irrelevanten Protokoll Meldungen mit xxx.)
# John's Machine
$ git clone john@githost:simplegit.git
Initialized empty Git repository in /home/john/simplegit/.git/
...
$ cd simplegit/
$ vim lib/simplegit.rb
$ git commit -am 'removed invalid default value'
[master 738ee87] removed invalid default value
1 files changed, 1 insertions(+), 1 deletions(-)
Der zweite Entwickler, Jessica, tut das gleiche. Sie klont das Repository und committet eine Änderung:
# Jessica's Machine
$ git clone jessica@githost:simplegit.git
Initialized empty Git repository in /home/jessica/simplegit/.git/
...
$ cd simplegit/
$ vim TODO
$ git commit -am 'add reset task'
[master fbff5bc] add reset task
1 files changed, 1 insertions(+), 0 deletions(-)
Jetzt lädt Jessica ihre Arbeit mit git push auf den Server:
# Jessica's Machine
$ git push origin master
...
To jessica@githost:simplegit.git
1edee6b..fbff5bc master -> master
John versucht, das selbe zu tun:
# John's Machine
$ git push origin master
To john@githost:simplegit.git
! [rejected] master -> master (non-fast forward)
error: failed to push some refs to 'john@githost:simplegit.git'
John darf seine Änderung nicht pushen, weil Jessica in der Zwischenzeit gepushed hat. Dies ist ein Unterschied zu Subversion: wie Du siehst, haben die beiden Entwickler nicht dieselbe Datei bearbeitet. Während Subversion automatisch merged, wenn lediglich verschiedene Dateien bearbeitet wurden, muss man Commits in Git lokal mergen. John muss also Jessicas Änderungen herunterladen und mergen, bevor er dann selbst pushen darf:
$ git fetch origin
...
From john@githost:simplegit
+ 049d078...fbff5bc master -> origin/master
Zu diesem Zeitpunkt sieht Johns lokales Repository jetzt aus wie in Bild 5-4.
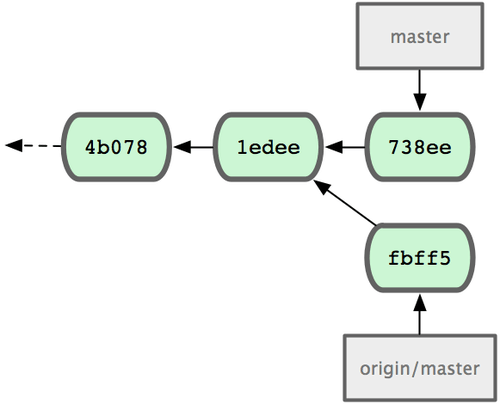
Bild 5-4. Johns ursprüngliches Repository
John hat eine Referenz auf Jessicas Änderungen, aber er muss sie mit seinen eigenen Änderungen mergen, bevor er auf den Server pushen darf:
$ git merge origin/master
Merge made by recursive.
TODO | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)
Der Merge verläuft glatt: Johns Commit Historie sieht jetzt aus wie in Bild 5-5.
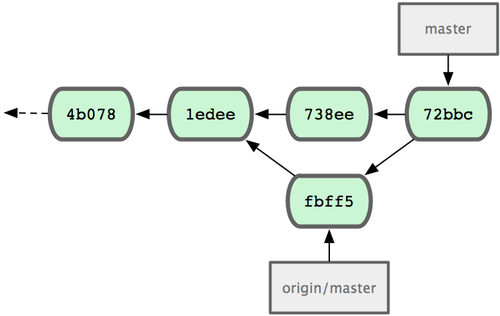
Johns Repository nach dem Merge mit origin/master
John sollte seinen Code jetzt testen, um sicher zu stellen, dass alles weiterhin funktioniert. Dann kann er seine Arbeit auf den Server pushen:
$ git push origin master
...
To john@githost:simplegit.git
fbff5bc..72bbc59 master -> master
Johns Commit Historie sieht schließlich aus wie in Bild 5-6.
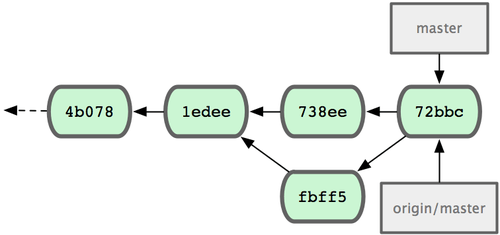
Johns Commit Historie nach dem pushen auf den origin Server
In der Zwischenzeit hat Jessica auf einem Topic Branch (xxx) gearbeitet. Sie hat einen Topic Branch mit dem Namen issue54 und darin drei Commits angelegt. Sie hat Johns Änderungen bisher noch nicht herunter geladen, sodass ihre Commit Historie jetzt so aussieht wie in Bild 5-7.
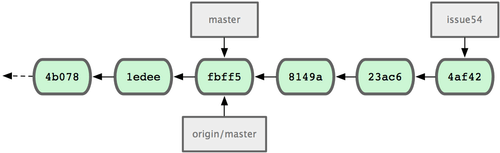
Bild 5-7. Jessicas ursprüngliche Commit Historie
Jessica will ihre Arbeit jetzt mit John synchronisieren. Also lädt sie seine Änderungen herunter:
# Jessica's Machine
$ git fetch origin
...
From jessica@githost:simplegit
fbff5bc..72bbc59 master -> origin/master
Das lädt die Änderungen, die John in der Zwischenzeit hochgeladen hat. Jessicas Historie entspricht jetzt Bild 5-8.
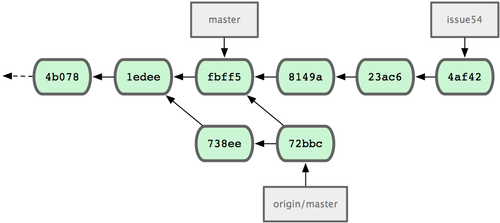
Bild 5-8. Jessicas Historie nachdem sie Johns Änderungen geladen hat
Jessica hat die Arbeit in ihrem Topic Branch abgeschlossen, aber sie will wissen, welche neuen Änderungen es gibt, mit denen sie ihre eigenen mergen muss.
$ git log --no-merges origin/master ^issue54
commit 738ee872852dfaa9d6634e0dea7a324040193016
Author: John Smith <jsmith@example.com>
Date: Fri May 29 16:01:27 2009 -0700
removed invalid default value
Jetzt kann Jessica zunächst ihren Topic Branch issue54 in ihren master Branch mergen, dann Johns Änderungen aus origin/master in ihren master Branch mergen und schließlich das Resultat auf den origin Server pushen. Als erstes wechselt sie zurück auf ihren master Branch:
$ git checkout master
Switched to branch "master"
Your branch is behind 'origin/master' by 2 commits, and can be fast-forwarded.
Sie kann jetzt entweder origin/master oder issue54 zuerst mergen – sie sind beide „upstream“ (xxx). Der resultierende Snapshot wäre identisch, egal in welcher Reihenfolge sie beide Branches in ihren master Branch merged, lediglich die Historie würde natürlich minimal anders aussehen. Jessica entscheidet sich, issue54 zuerst zu mergen:
$ git merge issue54
Updating fbff5bc..4af4298
Fast forward
README | 1 +
lib/simplegit.rb | 6 +++++-
2 files changed, 6 insertions(+), 1 deletions(-)
Das ging glatt, wie Du siehst, war es ein einfacher „fast-forward“ Merge. Als nächstes merged Jessica Johns Änderungen aus origin/master:
$ git merge origin/master
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
Auch hier treten keine Konflikte auf. Jessicas Historie sieht jetzt wie folgt aus (Bild 5-9).
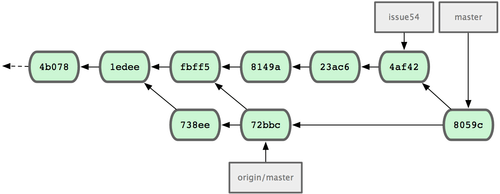
Bild 5-9. Jessicas Historie nach dem Merge mit Johns Änderungen
origin/master ist jetzt in Jessicas master Branch enthalten (xxx reachable xxx), sodass sie in der Lage sein sollte, auf den origin Server zu pushen (vorausgesetzt, John hat zwischenzeitlich nicht gepusht):
$ git push origin master
...
To jessica@githost:simplegit.git
72bbc59..8059c15 master -> master
Beide Entwickler haben jetzt einige Male committed und die Arbeit des jeweils anderen erfolgreich mit ihrer eigenen zusammengeführt.
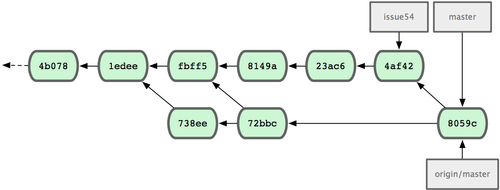
Bild 5-10. Jessicas Historie nachdem sie sämtliche Änderungen auf den Server gepusht hat
Dies ist eine der simpelsten Workflow Varianten. Du arbeitest eine Weile, normalerweise in einem Topic Branch, und mergst in Deinen master Branch, wenn Du fertig bist. Wenn Du Deine Änderungen anderen zur Verfügung stellen willst, holst Du den aktuellen origin/master Branch, mergst Deinen master Branch damit und pushst das ganze zurück auf den origin Server. Der Ablauf sieht in etwa wie folgt aus (Bild 5-11).
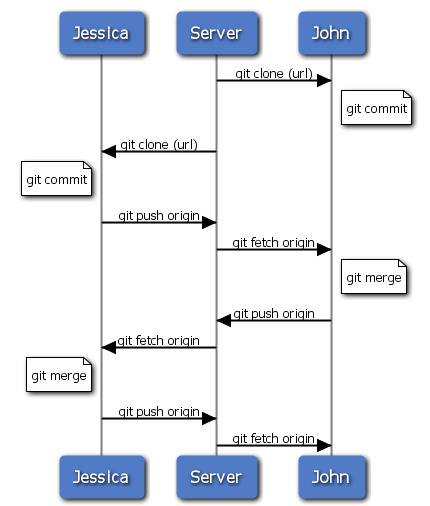
Bild 5-11. Ablauf eines einfachen Workflows für mehrere Entwickler
Teil-Teams mit Integration Manager
Im folgenden Szenario sehen wir uns die Rollen von Mitarbeitern in einem größeren, nicht öffentlich arbeitenden Team an. Du wirst sehen, wie man in einer Umgebung arbeiten kann, in der kleine Gruppen (z.B. an einzelnen Features) zusammenarbeiten und ihre Ergebnisse dann von einer weiteren Gruppe in die Hauptentwicklungslinie integriert werden.
Sagen wir John und Jessica arbeiten gemeinsam an einem Feature, während Jessica und Josie an einem anderen arbeiten. Das Unternehmen verwendet einen Integration-Manager Workflow, in dem die Arbeit der verschiedenen Gruppen von anderen Mitarbeitern zentral integriert werden – und der master Branch nur von diesen letzteren geschrieben werden kann. In diesem Szenario wird sämtliche Arbeit von den Teams in Branches erledigt und dann von den Integration-Manangern zusammengeführt.
Schauen wir uns Jessicas Workflow an, während sie mit jeweils verschiedenen Entwicklern parallel an zwei Features arbeitet. Nehmen wir an, sie hat das Repository bereits geklont und will zuerst an featureA arbeiten. Sie legt einen neuen Branch für das Feature an und fängt an, daran zu arbeiten:
# Jessica's Machine
$ git checkout -b featureA
Switched to a new branch "featureA"
$ vim lib/simplegit.rb
$ git commit -am 'add limit to log function'
[featureA 3300904] add limit to log function
1 files changed, 1 insertions(+), 1 deletions(-)
Jetzt will sie ihre Arbeit John zur Verfügung stellen, der am gleichen Feature arbeiten will, und pusht dazu ihre Commits in ihrem featureA Branch auf den Server. Jessica hat keinen Schreibzugriff auf den master Branch – den haben nur die Integration Manager – also pusht sie ihren Feature Branch, der nur der Zusammenarbeit mit John dient:
$ git push origin featureA
...
To jessica@githost:simplegit.git
* [new branch] featureA -> featureA
Jessica schickt John eine E-Mail und lässt ihn wissen, dass sie ihre Arbeit in einen Branch featureA hochgeladen hat. Während sie jetzt auf Feedback von John wartet, kann Jessica anfangen, an featureB zuarbeiten – diesmal gemeinsam mit Josie. Also legt sie einen neuen Feature Branch an, der auf dem gegenwärtigen master Branch des origin Servers basiert:
# Jessica's Machine
$ git fetch origin
$ git checkout -b featureB origin/master
Switched to a new branch "featureB"
Jetzt legt Jessica eine Reihe von Commits im featureB Branch an:
$ vim lib/simplegit.rb
$ git commit -am 'made the ls-tree function recursive'
[featureB e5b0fdc] made the ls-tree function recursive
1 files changed, 1 insertions(+), 1 deletions(-)
$ vim lib/simplegit.rb
$ git commit -am 'add ls-files'
[featureB 8512791] add ls-files
1 files changed, 5 insertions(+), 0 deletions(-)
Jessicas Repository entspricht jetzt Bild 5-12.
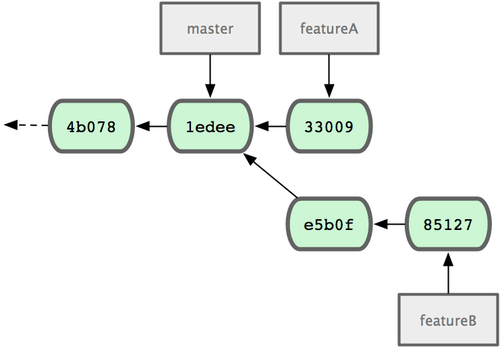
Bild 5-12. Jessicas ursprüngliche Commit Historie
Jessica könnte ihre Arbeit jetzt hochladen, aber sie hat eine E-Mail von Josie erhalten, dass sie bereits einen Feature Branch featureBee für dasselbe Feature auf dem Server angelegt hat. Jessica muss also erst ihre eigenen Änderungen mit diesem Branch mergen und dann dorthin pushen. Sie lädt also Josies Änderungen mit git fetch herunter:
$ git fetch origin
...
From jessica@githost:simplegit
* [new branch] featureBee -> origin/featureBee
Jessica kann ihre eigene Arbeit jetzt mit diesen Änderungen zusammenführen:
$ git merge origin/featureBee
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 4 ++++
1 files changed, 4 insertions(+), 0 deletions(-)
Es gibt jetzt ein kleines Problem. Jessica muss die zusammengeführten Änderungen in ihrem featureB Branch in den featureBee Branch auf dem Server pushen. Das kann sie tun, indem sie sowohl den Namen ihres lokalen Branches als auch des externen Branches angibt, und zwar mit einem Doppelpunkt getrennt:
$ git push origin featureB:featureBee
...
To jessica@githost:simplegit.git
fba9af8..cd685d1 featureB -> featureBee
Das nennt man eine Refspec. In Kapitel 9 gehen wir detailliert auf Git Refspecs ein und darauf, was man noch mit ihnen machen kann.
Als nächstes schickt John Jessica eine E-Mail. Er schreibt, dass er einige Änderungen in den featureA Branch gepusht hat, und bittet sie, diese zu prüfen. Sie führt also git fetch aus, um die Änderungen herunter zu laden:
$ git fetch origin
...
From jessica@githost:simplegit
3300904..aad881d featureA -> origin/featureA
Danach kann sie die neuen Änderungen mit git log auflisten:
$ git log origin/featureA ^featureA
commit aad881d154acdaeb2b6b18ea0e827ed8a6d671e6
Author: John Smith <jsmith@example.com>
Date: Fri May 29 19:57:33 2009 -0700
changed log output to 30 from 25
Schließlich aktualisiert sie ihren eigenen featureA Branch mit Johns Änderungen:
$ git checkout featureA
Switched to branch "featureA"
$ git merge origin/featureA
Updating 3300904..aad881d
Fast forward
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)
Jessica will eine kleine Änderung vornehmen. Also comittet sie und pusht den neuen Commit auf den Server:
$ git commit -am 'small tweak'
[featureA 774b3ed] small tweak
1 files changed, 1 insertions(+), 1 deletions(-)
$ git push origin featureA
...
To jessica@githost:simplegit.git
3300904..774b3ed featureA -> featureA
Jessicas Commit Historie sieht jetzt wie folgt aus (Bild 5-13).
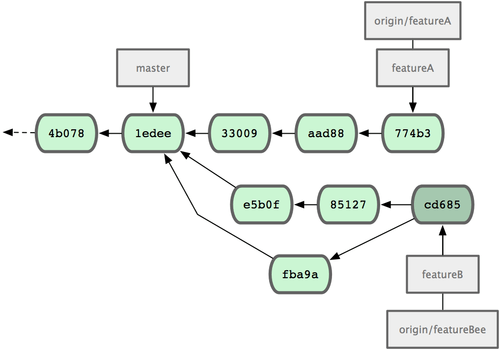
Bild 5-13. Jessicas Historie mit dem neuen Commit im Feature Branch
Jessica, Josie und John informieren jetzt ihre Integration Manager, dass die Ändeurngen in den Branches featureA und featureBee fertig sind und in die Hauptlinie in master übernommen werden können. Nachdem das geschehen ist, wird git fetch die neuen Merge Commits herunter laden und die Commit Historie in etwa wie folgt aussehen (Bild 5-14):
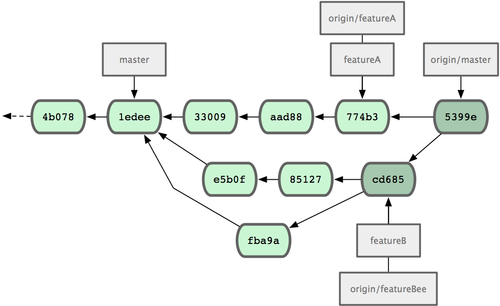
Bild 5-14. Jessicas Historie nachdem beide Feature Branches gemerged wurden
Viele Teams wechseln zu Git, weil es auf einfache Weise ermöglicht, verschiedene Teams parallel an verschiedenen Entwicklungslinien zu arbeiten, die erst später im Prozess integriert werden. Ein riesiger Vorteil von Git besteht darin, dass man in kleinen Teilgruppen über externe Branches zusammenarbeiten kann, ohne dass dazu notwendig wäre, das gesamte Team zu involvieren und möglicherweise aufzuhalten. Der Ablauf dieser Art von Workflow kann wie folgt dargestellt werden (Bild 5-15).
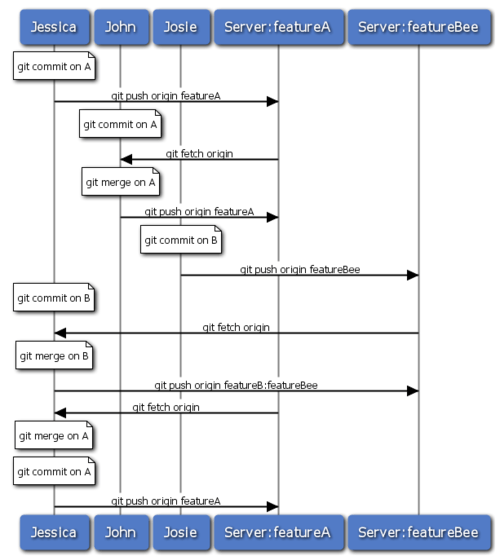
Bild 5-15. Workflow mit Teil-Teams und Integration Manager
Kleine, öffentliche Projekte
An öffentlichen Projekten mitzuarbeiten funktioniert ein bisschen anders. Weil man normalerweise keinen Schreibzugriff auf das öffentliche Repository des Projektes hat, muss man mit den Betreibern in anderer Form zusammenarbeiten. Unser erstes Beispiel beschreibt, wie man zu Projekten auf Git Hosts beitragen kann, die es erlauben Forks eines Projektes anzulegen. Z.B. unterstützen die Git Hosting Seiten repo.or.cz und GitHub dieses Feature – und viele Projekt Betreiber akzeptieren Änderungen in dieser Form. Das nächste Beispiel geht dann darauf ein, wie man mit Projekten arbeiten kann, die es bevorzugen, Patches per E-Mail zu erhalten (xxx oder Ticket Tracker, wie z.B. Rails xxx).
Zunächst wirst vermutlich das Hauptrepository klonen, einen Topic Branch für Deinen Patch anlegen und dann darin arbeiten. Der Prozess sieht dann in etwa so aus:
$ git clone (url)
$ cd project
$ git checkout -b featureA
$ (work)
$ git commit
$ (work)
$ git commit
Es ist wahrscheinlich sinnvoll, git rebase -i zu verwenden, um die verschiedenen Commits zu einem einzigen zusammen zu packen („squash“, quetschen) oder um sie in anderer Weise neu zu arrangieren, sodass es für die Projekt Betreiber leichter ist, die Änderungen nach zu vollziehen. In Kapitel 6 gehen wir ausführlicher auf das interaktive rebase -i ein.
Wenn Dein Branch fertig ist und Du Deine Arbeit den Projekt Betreibern zur Verfügung stellen willst, gehst Du auf die Projekt Seite und klickst auf den „Fork“ Button. Dadurch legst Du Deinen eigenen Fork des Projektes an, in den Du dann schreiben kannst. Die Repository URL dieses Forks musst Du dann als ein zweites, externes Repository („remote“) einrichten. In unserem Beispiel verwenden wir den Namen myfork:
$ git remote add myfork (url)
Jetzt kannst Du Deine Änderungen dorthin hochladen. Am besten tust Du das, indem Du Deinen Topic Branch hochlädst (statt ihn in Deinen master Branch zu mergen und den dann hochzuladen). Dies deshalb, weil Du, wenn Deine Änderungen nicht akzeptiert werden, Deinen eigenen master Branch nicht zurücksetzen musst. Wenn die Projekt Betreiber Deine Änderungen mergen, rebasen oder cherry-picken, landen sie schließlich ohnehin in Deinem master Branch.
$ git push myfork featureA
Nachdem Du Deine Arbeit in Deinen Fork hochgeladen hast, musst Du die Projekt Betreiber benachrichtigen. Dies wird oft als „pull request“ bezeichnet. Du kannst ihn entweder direkt über die Webseite schicken (GitHub hat dazu einen „pull request“ Button) oder den Git Befehl git request-pull verwenden und manuell eine E-Mail an die Projekt Betreiber schicken.
Der request-pull Befehl vergleicht denjenigen Branch, für den Deine Änderungen gedacht sind, mit Deinem Topic Branch und gibt eine Übersicht der Änderungen aus. Wenn Jessica zwei Änderungen in einem Topic Branch hat und nun John einen pull request schicken will, kann sie folgendes tun:
$ git request-pull origin/master myfork
The following changes since commit 1edee6b1d61823a2de3b09c160d7080b8d1b3a40:
John Smith (1):
added a new function
are available in the git repository at:
git://githost/simplegit.git featureA
Jessica Smith (2):
add limit to log function
change log output to 30 from 25
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)
Die Ausgabe kann an den Projekt Betreiber geschickt werden – sie sagt klar, auf welchem Branch die Arbeit basiert, gibt eine Zusammenfassung der Änderungen und gibt an, aus welchem Fork oder Repository man die Änderungen herunterladen kann.
Wenn Du nicht selbst Betreiber eines bestimmten Projektes bist, ist es im Allgemeinen einfacher, einen Branch master immer dem origin/master Branch tracken (xxx folgen) zu lassen und eigene Änderungen in Topic Branches vorzunehmen, die man leicht wieder löschen kann, wenn sie nicht akzeptiert werden. Wenn Du Aspekte Deiner Arbeit in Topic Branches isolierst, kannst Du sie außerdem recht leicht auf den letzten Stand des Hauptrepositories rebasen, falls das Hauptrepository in der Zwischenzeit weiter entwickelt wurde und Deine Commits nicht mehr sauber passen. Wenn Du beispielsweise an einem anderen Patch für das Projekt arbeiten willst, verwende dazu nicht weiter den gleichen Topic Branch, den Du gerade in Deinen Fork hochgeladen hast. Lege statt dessen einen neuen Topic Branch an, der wiederum auf dem master Branch des Hauptrepositories basiert.
$ git checkout -b featureB origin/master
$ (work)
$ git commit
$ git push myfork featureB
$ (email maintainer)
$ git fetch origin
Deine Arbeit an den verschiedenen Patches sind jetzt in Deine Topic Branches isoliert – ähnlich wie in einer Patch Queue – sodass Du die einzelnen Topic Branches neu schreiben, rebasen und ändern kannst, ohne dass sie mit einander in Konflikt geraten (siehe Bild 5-16).
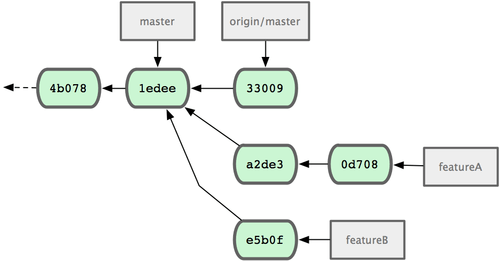
Bild 5-16. Ursprüngliche Commit Historie mit dem featureB Branch
Sagen wir, der Projekt Betreiber hat eine Reihe von Änderungen Dritter in das Projekt übernommen und Deine eigenen Änderungen lassen sich jetzt nicht mehr sauber mergen. In diesem Fall kannst Du Deine Änderungen auf dem neuen Stand des origin/master Branches rebasen, Konflikte beheben und Deine Arbeit erneut einreichen:
$ git checkout featureA
$ git rebase origin/master
$ git push -f myfork featureA
Das schreibt Deine Commit Historie neu, sodass sie jetzt so aussieht (Bild 5-17):
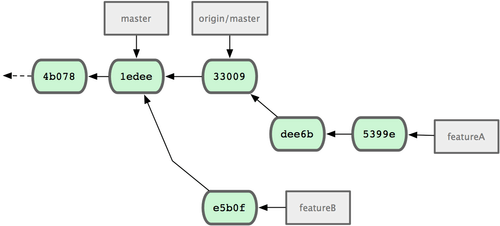
Bild 5-17. Commit Historie nach dem rebase von featureA
Weil Du den Branch rebased hast, musst Du die Option -f verwenden, um den featureA Branch auf dem Server zu ersetzen, denn Du hast die Commit Historie umgeschrieben und nun ist ein Commit enthalten, von dem der gegenwärtig letzte Commit des externen Branches nicht abstammt. Eine Alternative dazu wäre, den Branch jetzt in einen neuen externen Branch zu pushen, z.B. featureAv2.
Schauen wir uns noch ein anderes Szenario an: der Projekt Betreiber hat sich Deine Arbeit angesehen und will die Änderungen übernehmen, aber er bittet dich, noch eine Kleinigkeit an der Implementierung zu ändern. Du willst die Gelegenheit außerdem nutzen, um Deine Änderungen neu auf den gegenwärtigen master Branch des Projektes zu basieren. Du legst dazu einen neuen Branch von origin/master an, übernimmst Deine Änderungen dahin, löst ggf. Konflikte auf, nimmst die angeforderte Änderung an der Implementierung vor und lädst die Änderungen auf den Server:
$ git checkout -b featureBv2 origin/master
$ git merge --no-commit --squash featureB
$ (change implementation)
$ git commit
$ git push myfork featureBv2
Die --squash Option bewirkt, dass alle Änderungen des Merge Branches (featureB) übernommen werden, ohne aber dass zusätzlich ein Merge Commit angelegt wird. Die --no-commit Option instruiert Git außerdem, nicht automatisch einen Commit anzulegen. Das erlaubt dir, sämtliche Änderungen aus dem anderen Branch zu übernehmen und dann weitere Änderungen vorzunehmen, bevor Du das Ganze dann in einem neuen Commit speicherst.
Jetzt kannst Du dem Projekt Betreiber eine Nachricht schicken, dass Du die angeforderte Änderung vorgenommen hast und dass er Deine Arbeit in Deinem featureBv2 Branch finden kann (siehe Bild 5-18).
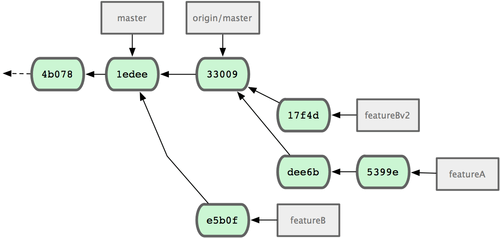
Bild 5-18. Commit Historie mit dem neuen featureBv2 Branch
Große öffentliche Projekte
Viele große Projekte haben einen etablierten Prozess, nach dem sie vorgehen, wenn es darum geht, Patches zu akzeptieren. Du musst Dich mit den jeweiligen Regeln vertraut machen, die in jedem Projekt ein bisschen anders sind. Allerdings akzeptieren viele große Projekte Patches per E-Mail über eine Entwickler Mailingliste (xxx oder einen Bugtracker, wie Rails xxx). Deshalb gehen wir auf dieses Beispiel als nächstes ein.
Der Workflow ist ähnlich wie im vorherigen Szenario. Du legst für jeden Patch oder jede Patch Serie einen Topic Branch an, in dem Du arbeitest. Der Unterschied besteht dann darin, auf welchem Wege Du die Änderungen an das Projekt schickst. Statt das Projekt zu forken und Änderungen in Deinen Fork hochzuladen, erzeugst Du eine E-Mail Version Deiner Commits und schickst sie als Patch an die Entwickler Mailingliste.
$ git checkout -b topicA
$ (work)
$ git commit
$ (work)
$ git commit
Jetzt hast Du zwei Commits, die Du an die Mailingliste schicken willst. Du kannst den Befehl git format-patch verwenden, um aus diesen Commits Dateien zu erzeugen, die im mbox-Format formatiert sind und die Du per E-Mail verschicken kannst. Dieser Befehl macht aus jedem Commit eine E-Mail Datei. Die erste Zeile der Commit Meldung wird zum Betreff der E-Mail und der Rest der Commit Meldung sowie der Patch des Commits selbst wird zum Text der E-Mail. Das schöne daran ist, dass wenn man einen auf diese Weise erzeugten Patch benutzt, dann bleiben alle Commit Informationen erhalten. Du kannst das in den nächsten Beispielen sehen:
$ git format-patch -M origin/master
0001-add-limit-to-log-function.patch
0002-changed-log-output-to-30-from-25.patch
Der Befehl git format-patch zeigt Dir die Namen der Patch Dateien an, die er erzeugt hat. (Die -M option weist Git an, nach umbenannten Dateien Ausschau zu halten.) Die Dateien sehen dann so aus:
$ cat 0001-add-limit-to-log-function.patch
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] add limit to log function
Limit log functionality to the first 20
---
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index 76f47bc..f9815f1 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -14,7 +14,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log #{treeish}")
+ command("git log -n 20 #{treeish}")
end
def ls_tree(treeish = 'master')
--
1.6.2.rc1.20.g8c5b.dirty
Du kannst diese Patch Dateien anschließend bearbeiten, z.B. um weitere Informationen für die Mailingliste hinzuzufügen, die Du nicht in der Commit Meldung haben willst. Wenn Du zusätzlichen Text zwischen der --- Zeile und dem Anfang des Patches (der Zeile lib/simplegit.rb in diesem Fall), dann ist er für den Leser sichtbar, aber Git wird ihn ignorieren, wenn man den Patch verwendet.
Um das jetzt an die Mailingliste zu schicken, kannst Du entweder die Datei per copy-and-paste in Dein E-Mail Programm kopieren, als Anhang an eine E-Mail anhängen oder Du kannst die Dateien mit einem Befehlszeilen Programm direkt verschicken. Patches zu kopieren verursacht oft Formatierungsprobleme – insbesondere mit „smarten“ E-Mail Clients, die die Dinge umformatieren, die man einfügt. Zum Glück bringt Git aber ein Tool mit, mit dem man Patches in ihrer korrekten Formatierung über IMAP verschicken kann. In folgendem Beispiel zeige ich, wie man Patches über Gmail verschicken kann, welches der E-Mail Client ist, den ich selbst verwende. Darüberhinaus findest Du ausführliche Beschreibungen für zahlreiche E-Mail Programme am Ende der schon erwähnten Datei Documentation/SubmittingPatches im Git Quellcode.
Zunächst musst Du die IMAP Sektion in Deiner ~/.gitconfig Datei ausfüllen. Du kannst jeden Wert separat mit dem Befehl git config eingeben oder Du kannst die Datei öffnen und sie manuell eingeben. Im Endeffekt sollte Deine ~/.gitconfig Datei in etwa so aussehen:
[imap]
folder = "[Gmail]/Drafts"
host = imaps://imap.gmail.com
user = user@gmail.com
pass = p4ssw0rd
port = 993
sslverify = false
Wenn Dein IMAP Server kein SSL verwendet, kannst Du die letzten beiden Zeilen wahrscheinlich weglassen und der host dürfte mit imap:// und nicht imaps:// beginnen. Wenn Du diese Einstellungen konfiguriert hast, kannst Du git imap-send verwenden, um Deine Patches in den Entwurfsordner des angegebenen IMAP Servers zu kopieren:
$ cat *.patch |git imap-send
Resolving imap.gmail.com... ok
Connecting to [74.125.142.109]:993... ok
Logging in...
sending 2 messages
100% (2/2) done
Jetzt kannst Du in Deinen Entwürfe-Ordner wechseln, die Mailingliste an die Du den Patch senden möchtest im An-Feld setzen, vielleicht noch den Maintainer oder die verantwortliche Person in das CC-Feld einfügen und dann das Ganze losschicken.
Man kann Patches auch über einen SMTP-Server schicken. Wie im letzen Beispiel, kann man auch hier jeden einzelnen Wert mit einer Reihe von git config Kommandos setzen. Oder aber Du änderst die Sektion sendemail in Deiner ~/.gitconfig Datei manuell:
[sendemail]
smtpencryption = tls
smtpserver = smtp.gmail.com
smtpuser = user@gmail.com
smtpserverport = 587
Nach der Änderungen kannst Du mit git send-email die Patches abschicken:
$ git send-email *.patch
0001-added-limit-to-log-function.patch
0002-changed-log-output-to-30-from-25.patch
Who should the emails appear to be from? [Jessica Smith <jessica@example.com>]
Emails will be sent from: Jessica Smith <jessica@example.com>
Who should the emails be sent to? jessica@example.com
Message-ID to be used as In-Reply-To for the first email? y
Git gibt dann für jeden Patch, den Du verschickst, ein paar Log Informationen aus, die in etwa so aussehen:
(mbox) Adding cc: Jessica Smith <jessica@example.com> from
\line 'From: Jessica Smith <jessica@example.com>'
OK. Log says:
Sendmail: /usr/sbin/sendmail -i jessica@example.com
From: Jessica Smith <jessica@example.com>
To: jessica@example.com
Subject: [PATCH 1/2] added limit to log function
Date: Sat, 30 May 2009 13:29:15 -0700
Message-Id: <1243715356-61726-1-git-send-email-jessica@example.com>
X-Mailer: git-send-email 1.6.2.rc1.20.g8c5b.dirty
In-Reply-To: <y>
References: <y>
Result: OK
Jetzt solltest Du in den Entwurfsordner Deines E-Mail Clients gehen, als Empfänger Adresse die jeweilige Mailingliste angeben, möglicherweise ein CC an den Projektbetreiber oder einen anderen Verantwortlichen setzen und die E-Mail dann verschicken können.
Zusammenfassung
Wir haben jetzt eine Reihe von Workflows besprochen, die für jeweils sehr verschiedene Arten von Projekten üblich sind und denen Du vermutlich begegnen wirst. Wir haben außerdem einige neue Tools besprochen, die dabei hilfreich sind, diese Workflows umzusetzen. Als nächstes werden wir auf die andere Seite dieser Medaille eingehen: wie Du selbst ein Git Projekt betreiben kannst. Du wirst lernen, wie Du als „wohlwollender Diktator“ oder als Integration Manager arbeiten kannst.