Änderungen am Repository nachverfolgen
Du hast jetzt ein voll funktionsfähiges Git Repository und eine Arbeitskopie des Projekts ist in Deinem Verzeichnis ausgecheckt. Du kannst nun die Dateien im Projekt bearbeiten. Immer wenn Dein Projekt einen Zustand erreicht hat, den Du festhalten willst, musst Du diese Änderungen einchecken.
Jede Datei in Deinem Arbeitsverzeichnis kann sich in einem von zwei Zuständen befinden: Änderungen werden verfolgt (engl. tracked) oder nicht (engl. untracked). Alle Dateien, die sich im letzten Snapshot (Commit) befanden, werden in der Versionskontrolle verfolgt. Sie können entweder unverändert (engl. unmodified), modifiziert (engl. modified) oder für den nächsten Commit vorgemerkt (engl. staged) sein. Alle anderen Dateien in Deinem Arbeitsverzeichnis dagegen sind nicht versioniert: das sind all diejenigen Dateien, die nicht schon im letzten Snapshot enthalten waren und die sich nicht in der Staging Area befinden. Wenn Du ein Repository gerade geklont hast, sind alle Dateien versioniert und unverändert – Du hast sie gerade ausgecheckt aber noch nicht verändert.
Sobald Du versionierte Dateien bearbeitest, wird Git sie als modifiziert erkennen, weil Du sie seit dem letzten Commit geändert hast. Du merkst diese geänderten Dateien für den nächsten Commit vor (d.h. Du fügst sie zur Staging Area hinzu bzw. Du stagest sie), legst aus allen markierten Änderungen einen Commit an und der Vorgang beginnt von vorn. Bild 2-1 stellt diesen Zyklus dar:
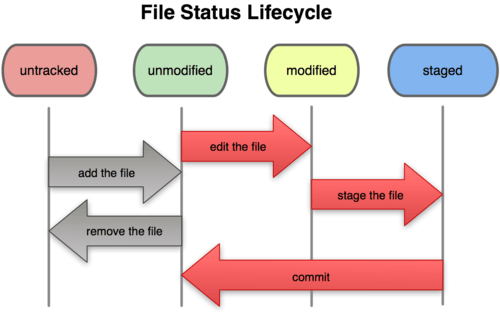
Bild 2-1. Zyklus der Grundzustände Deiner Dateien
Den Zustand Deiner Dateien prüfen
Das wichtigste Hilfsmittel, um den Zustand zu überprüfen, in dem sich die Dateien in Deinem Repository gerade befinden, ist der Befehl git status. Wenn Du diesen Befehl unmittelbar nach dem Klonen eines Repositorys ausführst, sollte er folgende Ausgabe liefern:
$ git status
On branch master
nothing to commit, working directory clean
Dieser Zustand wird auch als sauberes Arbeitsverzeichnis (engl. clean working directory) bezeichnet. Mit anderen Worten, es gibt keine Dateien, die unter Versionskontrolle stehen und seit dem letzten Commit geändert wurden – andernfalls würden sie hier aufgelistet werden. Außerdem teilt Dir der Befehl mit, in welchem Branch Du Dich gerade befindest. In diesem Beispiel ist dies der Branch master. Mach Dir darüber im Moment keine Gedanken, wir werden im nächsten Kapitel auf Branches detailliert eingehen.
Sagen wir Du fügst eine neue README Datei zu Deinem Projekt hinzu. Wenn die Datei zuvor nicht existiert hat und Du jetzt git status ausführst, zeigt Git die bisher nicht versionierte Datei wie folgt an:
$ vim README
$ git status
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
README
nothing added to commit but untracked files present (use "git add" to track)
Alle Dateien, die in der Sektion „Untracked files“ aufgelistet werden, sind Dateien, die bisher nocht nicht versioniert sind. Dort wird jetzt auch die Datei README angezeigt. Mit anderen Worten, die Datei README wird in diesem Bereich gelistet, weil sie im letzen Snapshot (Commit) von Git nicht enthalten ist. Git nimmt eine solche Datei nicht automatisch in die Versionskontrolle auf, sondern man muss Git dazu ausdrücklich auffordern. Ansonsten würden generierte Binärdateien oder andere Dateien, die Du nicht in Deinem Repository haben willst, automatisch hinzugefügt werden. Das möchte man in den meisten Fällen vermeiden. Jetzt wollen wir aber Änderungen an der Datei README verfolgen und fügen sie deshalb zur Versionskontrolle hinzu.
Neue Dateien zur Versionskontrolle hinzufügen
Um eine neue Datei zur Versionskontrolle hinzuzufügen, verwendest Du den Befehl git add. Für Deine neue README Datei kannst Du ihn wie folgt ausführen:
$ git add README
Wenn Du den git status Befehl erneut ausführst, siehst Du, dass sich Deine README Datei jetzt unter Versionskontrolle befindet und für den nächsten Commit vorgemerkt ist (gestaged ist):
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
Dass die Datei für den nächsten Commit vorgemerkt ist, siehst Du daran, dass sie in der Sektion „Changes to be committed“ aufgelistet ist. Wenn Du jetzt einen Commit anlegst, wird der Snapshot den Zustand der Datei beinhalten, den sie zum Zeitpunkt des Befehls git add hatte. Du erinnerst Dich daran, dass Du, als Du vorhin git init ausgeführt hast, anschließend git add ausgeführt hast: an dieser Stelle hast Du die Dateien in Deinem Verzeichnis der Versionskontrolle hinzugefügt. Der git add Befehl akzeptiert einen Pfadnamen einer Datei oder eines Verzeichnisses. Wenn Du ein Verzeichnis angibst, fügt git add alle Dateien in diesem Verzeichnis und allen Unterverzeichnissen rekursiv hinzu.
Geänderte Dateien stagen
Wenn Du eine bereits versionierte Datei benchmarks.rb änderst und den git status Befehl ausführst, erhältst Du folgendes:
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: benchmarks.rb
Die Datei benchmarks.rb erscheint in der Sektion „Changes not staged for commit“ – d.h., dass eine versionierte Datei im Arbeitsverzeichnis verändert worden ist, aber noch nicht für den Commit vorgemerkt wurde. Um sie vorzumerken, führst Du den Befehl git add aus. (git add wird zu verschiedenen Zwecken eingesetzt. Man verwendet ihn, um neue Dateien zur Versionskontrolle hinzuzufügen, Dateien für einen Commit zu markieren und verschiedene andere Dinge – beispielsweise, einen Konflikt aus einem Merge als aufgelöst zu kennzeichnen.)
$ git add benchmarks.rb
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
modified: benchmarks.rb
Beide Dateien sind nun für den nächsten Commit vorgemerkt. Nehmen wir an, Du willst jetzt aber noch eine weitere Änderung an der Datei benchmarks.rb vornehmen, bevor Du den Commit tatsächlich anlegst. Du öffnest die Datei und änderst sie. Jetzt könntest Du den Commit anlegen. Aber zuvor führen wir noch mal git status aus:
$ vim benchmarks.rb
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
modified: benchmarks.rb
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: benchmarks.rb
Huch, was ist das? Jetzt wird benchmarks.rb sowohl in der Staging Area als auch als geändert aufgelistet. Die Erklärung dafür ist, dass Git eine Datei in exakt dem Zustand für den Commit vormerkt, in dem sie sich befindet, wenn Du den Befehl git add ausführst. Wenn Du den Commit jetzt anlegst, wird die Version der Datei benchmarks.rb diejenigen Inhalte haben, die sie hatte, als Du git add zuletzt ausgeführt hast – nicht diejenigen, die sie in dem Moment hat, wenn Du den Commit anlegst. Wenn Du stattdessen die gegenwärtige Version im Commit haben willst, kannst Du einfach erneut git add ausführen:
$ git add benchmarks.rb
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
modified: benchmarks.rb
Dateien ignorieren
Du wirst in der Regel eine Reihe von Dateien in Deinem Projektverzeichnis haben, die Du nicht versionieren bzw. im Repository haben willst, wie z.B. automatisch generierte Dateien, wie Logdateien oder Dateien, die Dein Build-System erzeugt. In solchen Fällen kannst Du in der Datei .gitignore alle Dateien oder Dateimuster angeben, die Du ignorieren willst.
$ cat .gitignore
*.[oa]
*~
Die erste Zeile weist Git an, alle Dateien zu ignorieren, die mit einem .o oder .a enden (also Objekt- und Archiv-Dateien, die von Deinem Build-System erzeugt werden). Die zweite Zeile bewirkt, dass alle Dateien ignoriert werden, die mit einer Tilde (~) enden. Viele Texteditoren speichern ihre temporären Dateien auf diese Weise, wie bespielsweise Emacs. Du kannst außerdem Verzeichnisse wie log, tmp oder pid hinzufügen, automatisch erzeugte Dokumentation, und so weiter. Es ist normalerweise empfehlenswert, eine .gitignore Datei anzulegen, bevor man mit der eigentlichen Arbeit anfängt, damit man nicht versehentlich Dateien ins Repository hinzufügt, die man dort nicht wirklich haben will.
Folgende Regeln gelten in einer .gitignore Datei:
- Leere Zeilen oder Zeilen, die mit
#beginnen, werden ignoriert. - Standard
globMuster funktionieren. - Du kannst ein Muster mit einem Schrägstrich (
/) abschließen, um ein Verzeichnis zu deklarieren. - Du kannst ein Muster negieren, indem Du ein Ausrufezeichen (
!) voranstellst.
Glob Muster sind vereinfachte reguläre Ausdrücke, die von der Shell verwendet werden. Ein Stern (*) bezeichnet „kein oder mehrere Zeichen“; [abc] bezeichnet eines der in den eckigen Klammern angegebenen Zeichen (in diesem Fall also a, b oder c); ein Fragezeichen (?) bezeichnet ein beliebiges, einzelnes Zeichen; und eckige Klammern mit Zeichen, die von einem Bindestrich getrennt werden ([0-9]) bezeichnen ein Zeichen aus der jeweiligen Menge von Zeichen (in diesem Fall also aus der Menge der Zeichen von 0 bis 9).
Hier ist ein weiteres Beispiel für eine .gitignore Datei:
# ein Kommentar - dieser wird ignoriert
# ignoriert alle Dateien, die mit .a enden
*.a
# nicht aber lib.a Dateien (obwohl obige Zeile *.a ignoriert)
!lib.a
# ignoriert eine TODO Datei nur im Wurzelverzeichnis, nicht aber
/TODO
# ignoriert alle Dateien im build/ Verzeichnis
build/
# ignoriert doc/notes.txt, aber nicht doc/server/arch.txt
doc/*.txt
# ignoriert alle .txt Dateien unterhalb des doc/ Verzeichnis
doc/**/*.txt
Die Kombination **/ wurde in der Git Version 1.8.2 eingeführt.
Die Änderungen in der Staging Area durchsehen
Wenn Dir die Ausgabe des Befehl git status nicht aussagekräftig genug ist, weil Du exakt wissen willst, was sich geändert hat – und nicht lediglich, welche Dateien geändert wurden – kannst Du den git diff Befehl verwenden. Wir werden git diff später noch einmal im Detail besprechen, aber Du wirst diesen Befehl in der Regel verwenden wollen, um eine der folgenden, zwei Fragen zu beantworten: Was hast Du geändert, aber noch nicht für einen Commit vorgemerkt? Und welche Änderungen hast Du für einen Commit bereits vorgemerkt? Während git status diese Fragen nur mit Dateinamen beantwortet, zeigt Dir git diff exakt an, welche Zeilen hinzugefügt, geändert und entfernt wurden. Dies entspricht gewissermaßen einem Patch.
Nehmen wir an, Du hast die Datei README geändert und für einen Commit in der Staging Area vorgemerkt. Dann änderst Du außerdem die Datei benchmarks.rb, fügst sie aber noch nicht zur Staging Area hinzu. Wenn Du den git status Befehl dann ausführst, zeigt er Dir in etwa Folgendes an:
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: README
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: benchmarks.rb
Um festzustellen, welche Änderungen Du bisher nicht gestaged hast, führe git diff ohne irgendwelche weiteren Argumente aus:
$ git diff
diff --git a/benchmarks.rb b/benchmarks.rb
index 3cb747f..da65585 100644
--- a/benchmarks.rb
+++ b/benchmarks.rb
@@ -36,6 +36,10 @@ def main
@commit.parents[0].parents[0].parents[0]
end
+ run_code(x, 'commits 1') do
+ git.commits.size
+ end
+
run_code(x, 'commits 2') do
log = git.commits('master', 15)
log.size
Dieser Befehl vergleicht die Inhalte Deines Arbeitsverzeichnisses mit den Inhalten Deiner Staging Area. Das Ergebnis zeigt Dir die Änderungen, die Du an Dateien im Arbeitsverzeichnis vorgenommen, aber noch nicht für den nächsten Commit vorgemerkt hast.
Wenn Du sehen willst, welche Änderungen in der Staging Area und somit für den nächsten Commit vorgesehen sind, kannst Du git diff --cached verwenden. (Ab der Version Git 1.6.1 kannst Du außerdem git diff --staged verwenden, was vielleicht leichter zu merken ist.) Dieser Befehl vergleicht die Inhalte der Staging Area mit dem letzten Commit:
$ git diff --cached
diff --git a/README b/README
new file mode 100644
index 0000000..03902a1
--- /dev/null
+++ b/README2
@@ -0,0 +1,5 @@
+grit
+ by Tom Preston-Werner, Chris Wanstrath
+ http://github.com/mojombo/grit
+
+Grit is a Ruby library for extracting information from a Git repository
Es ist wichtig, im Kopf zu behalten, dass git diff nicht alle Änderungen seit dem letzten Commit anzeigt – er zeigt lediglich diejenigen Änderungen an, die noch nicht in der Staging Area sind. Das kann verwirrend sein. Wenn Du all Deine Änderungen bereits für einen Commit vorgemerkt hast, zeigt git diff überhaupt nichts an.
Ein anderes Beispiel: Wenn Du Änderungen an der Datei benchmarks.rb bereits zur Staging Area hinzugefügt hast und sie dann anschließend noch mal änderst, kannst Du git diff verwenden, um diese letzten Änderungen anzuzeigen, die noch nicht in der Staging Area sind:
$ git add benchmarks.rb
$ echo '# test line' >> benchmarks.rb
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: benchmarks.rb
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: benchmarks.rb
Jetzt kannst Du git diff verwenden, um zu sehen, was noch nicht für den nächsten Commit vorgemerkt ist:
$ git diff
diff --git a/benchmarks.rb b/benchmarks.rb
index e445e28..86b2f7c 100644
--- a/benchmarks.rb
+++ b/benchmarks.rb
@@ -127,3 +127,4 @@ end
main()
##pp Grit::GitRuby.cache_client.stats
+# test line
und git diff --cached, um zu sehen, was für den nächsten Commit vorgesehen ist:
$ git diff --cached
diff --git a/benchmarks.rb b/benchmarks.rb
index 3cb747f..e445e28 100644
--- a/benchmarks.rb
+++ b/benchmarks.rb
@@ -36,6 +36,10 @@ def main
@commit.parents[0].parents[0].parents[0]
end
+ run_code(x, 'commits 1') do
+ git.commits.size
+ end
+
run_code(x, 'commits 2') do
log = git.commits('master', 15)
log.size
Einen Commit erzeugen
Nachdem Du jetzt alle Änderungen, die Du im nächsten Commit haben willst, in Deiner Staging Area gesammelt hast, kannst Du den Commit anlegen. Denke daran, dass Änderungen, die nicht in der Staging Area sind (also alle Änderungen, die Du vorgenommen hast, seit Du zuletzt git add ausgeführt hast), auch nicht in den Commit aufgenommen werden. Sie werden ganz einfach weiterhin als geänderte Dateien im Arbeitsverzeichnis verbleiben. In unserem Beispiel haben wir gesehen, dass alle Änderungen vorgemerkt waren, als wir zuletzt git status ausgeführt haben, also können wir den Commit jetzt anlegen. Das geht am einfachsten mit dem Befehl:
$ git commit
Wenn Du diesen Befehl ausführst, wird Git den Texteditor Deiner Wahl starten. (D.h. denjenigen Texteditor, der durch die $EDITOR Variable Deiner Shell angegeben wird – normalerweise ist das vim oder emacs, aber Du kannst jeden Editor Deiner Wahl angeben. Wie in Kapitel 1 besprochen, kannst Du dazu git config --global core.editor verwenden.)
Der Editor zeigt in etwa folgenden Text an (dies ist ein Beispiel mit vim):
# Please enter the commit message for your changes. Lines starting
# with '#' will be ignored, and an empty message aborts the commit.
# On branch master
# Changes to be committed:
# new file: README
# modified: benchmarks.rb
#
~
~
~
".git/COMMIT_EDITMSG" 10L, 283C
Du siehst, dass die vorausgefüllte Commit Meldung die Ausgabe des letzten git status Befehls als einen Kommentar und darüber eine leere Zeile enthält. Du kannst die Kommentare entfernen und Deine eigene Meldung einfügen. Oder Du kannst sie stehen lassen, damit Du siehst, was im Commit enthalten sein wird. (Um die Änderungen noch detaillierter sehen zu können, kannst Du den Befehl git commit mit der Option -v verwenden. Das fügt zusätzlich das Diff Deiner Änderungen im Editor ein, sodass Du exakt sehen kannst, was sich im Commit befindet.) Wenn Du den Texteditor beendest, erzeugt Git den Commit mit der gegebenen Meldung (d.h., ohne den Kommentar und das Diff).
Alternativ kannst Du die Commit Meldung direkt mit dem Befehl git commit angeben, indem Du die Option -m wie folgt verwendest:
$ git commit -m "Story 182: Fix benchmarks for speed"
[master 463dc4f] Fix benchmarks for speed
2 files changed, 3 insertions(+)
create mode 100644 README
Du hast jetzt Deinen ersten Commit angelegt! Git zeigt Dir als Rückmeldung einige Details über den neu angelegten Commit an: in welchem Branch er sich befindet (master), welche SHA-1 Checksumme er hat (463dc4f, in diesem Fall nur die Kurzform), wie viele Dateien geändert wurden und eine Zusammenfassung über die insgesamt neu hinzugefügten und entfernten Zeilen in diesem Commit.
Denke daran, dass jeder neue Commit denjenigen Snapshot aufzeichnet, den Du in der Staging Area vorbereitet hast. Änderungen, die nicht in der Staging Area waren, werden weiterhin als modifizierte Dateien im Arbeitsverzeichnis vorliegen. Jedes Mal wenn Du einen Commit anlegst, zeichnest Du einen Snapshot Deines Projektes auf, zu dem Du zurückkehren oder mit dem Du spätere Änderungen vergleichen kannst.
Die Staging Area überspringen
Obwohl die Staging Area unglaublich nützlich ist, um genau diejenigen Commits anzulegen, die Du in Deiner Projekt Historie haben willst, ist sie manchmal auch ein bisschen umständlich. Git stellt Dir deshalb eine Alternative zur Verfügung, mit der Du die Staging Area überspringen kannst. Wenn Du den Befehl git commit mit der Option -a ausführst, übernimmt Git automatisch alle Änderungen an dejenigen Dateien, die sich bereits unter Versionskontrolle befinden, in den Commit – sodass Du auf diese Weise den Schritt git add weglassen kannst:
$ git status
On branch master
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: benchmarks.rb
no changes added to commit (use "git add" and/or "git commit -a")
$ git commit -a -m 'added new benchmarks'
[master 83e38c7] added new benchmarks
1 files changed, 5 insertions(+)
Beachte, dass Du in diesem Fall git add zuvor noch nicht ausgeführt hast, die Änderungen an benchmarks.rb aber dennoch in den Commit übernommen werden.
Dateien entfernen
Um eine Datei aus der Git Versionskontrolle zu entfernen, muss diese von den verfolgten Dateien (genauer, aus der Staging Area) entfernt werden und dann mit einem Commit bestätigt werden. Der Befehl git rm tut genau das – und löscht die Datei außerdem aus dem Arbeitsverzeichnis, sodass sie dort nicht unbeabsichtigt (als eine nun unversionierte Datei) liegen bleibt.
Wenn Du einfach nur eine Datei aus dem Arbeitsverzeichnis löschst, wird sie in der Sektion „Changes not staged for commit“ angezeigt, wenn Du git status ausführst:
$ rm grit.gemspec
$ git status
On branch master
Changes not staged for commit:
(use "git add/rm <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
deleted: grit.gemspec
no changes added to commit (use "git add" and/or "git commit -a")
Wenn Du jetzt git rm ausführst, wird diese Änderung für den nächsten Commit in der Staging Area vorgemerkt:
$ git rm grit.gemspec
rm 'grit.gemspec'
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
deleted: grit.gemspec
Nach dem nächsten Anlegen eines Commits, wird die Datei nicht mehr im Arbeitsverzeichnis liegen und sich nicht länger unter Versionskontrolle befinden. Wenn Du die Datei zuvor geändert und diese Änderung bereits zur Staging Area hinzugefügt hattest, musst Du die Option -f verwenden, um zu erzwingen, dass sie gelöscht wird. Dies ist eine Sicherheitsmaßnahme, um zu vermeiden, dass Du versehentlich Daten löschst, die sich bisher noch nicht als Commit Snapshot in der Historie Deines Projektes befinden – und deshalb auch nicht wiederhergestellt werden können.
Ein anderer Anwendungsfall für git rm ist, dass Du eine Datei in Deinem Arbeitsverzeichnis behalten, aber aus der Staging Area nehmen willst. In anderen Worten, Du willst die Datei nicht löschen, sondern aus der Versionskontrolle nehmen. Das könnte zum Beispiel der Fall sein, wenn Du vergessen hattest, eine Datei in .gitignore anzugeben und sie versehentlich zur Versionskontrolle hinzugefügt hast, beispielsweise eine große Logdatei oder eine Reihe kompilierter .a Dateien. Hierzu kannst Du dann die --cached Option verwenden:
$ git rm --cached readme.txt
Der git rm Befehl akzeptiert Dateien, Verzeichnisse und glob Dateimuster. D.h., Du kannst z.B. folgendes tun:
$ git rm log/\*.log
Beachte den Backslash (\) vor dem Stern (*). Er ist nötig, weil Git Dateinamen zusätzlich zur Dateinamen-Expansion Deiner Shell selbst vervollständigt. D.h., dieser Befehl entfernt alle Dateien, die die Erweiterung .log haben und sich im /log Verzeichnis befinden. Ein anderes Beispiel ist:
$ git rm \*~
Dieser Befehl entfernt alle Dateien, die mit einer Tilde (~) aufhören.
Dateien verschieben
Anders als andere VCS Systeme verfolgt Git nicht explizit, ob Dateien verschoben werden. Wenn Du eine Datei umbenennst, werden darüber keine Metadaten in der Historie gespeichert. Stattdessen ist Git schlau genug, solche Dinge im Nachhinein zu erkennen. Wir werden uns damit später noch befassen.
Es ist allerdings ein bisschen verwirrend, dass Git trotzdem einen git mv Befehl kennt. Wenn Du eine Datei umbenennen willst, kannst Du folgendes tun:
$ git mv file_from file_to
Das funktioniert einwandfrei. Wenn Du diesen Befehl ausführst und danach den git status ausführst, zeigt Git an, dass die Datei umbenannt wurde:
$ git mv README.txt README
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
renamed: README.txt -> README
Allerdings kannst Du genauso folgendes tun:
$ mv README.txt README
$ git rm README.txt
$ git add README
Git ist clever genug, selbst herauszufinden, dass Du die Datei umbenannt hast. Du brauchst dies also nicht explizit mit dem git mv Befehl zu tun. Der einzige Unterschied ist, dass Du mit git mv nur einen Befehl, nicht drei, ausführen musst – das ist natürlich etwas bequemer. Darüberhinaus kannst Du aber Dateien auf jede beliebige Art und Weise extern umbenennen und dann später git add bzw. git rm verwenden, wenn Du einen Commit zusammenstellst.