Git Grundlagen
Was also ist Git, in kurzen Worten? Es ist wichtig, den folgenden Abschnitt zu verstehen, in dem es um die grundlegenden Konzepte von Git geht. Das wird Dich in die Lage versetzen, Git einfacher und effektiver anzuwenden. Versuche Dein vorhandenes Wissen über andere Versionskontrollsysteme, wie Subversion oder Perforce, zu ignorieren, während Du Git kennen lernst. Git speichert und konzipiert Information anders als andere Systeme, auch wenn das Interface relativ ähnlich wirkt. Diese Unterschiede zu verstehen wird Dir helfen, Verwirrung bei der Anwendung von Git zu vermeiden.
Snapshots, nicht Diffs
Der Hauptunterschied zwischen Git und anderen Versionskontrollsystemen (auch Subversion und vergleichbaren Systemen) besteht in der Art und Weise wie Git Daten betrachtet. Die meisten anderen Systeme speichern Information als eine fortlaufende Liste von Änderungen an Dateien („Diffs“). Diese Systeme (CVS, Subversion, Perforce, Bazaar usw.) betrachten die Informationen, die sie verwalten, als eine Menge von Dateien und die Änderungen, die über die Zeit hinweg an einzelnen Dateien vorgenommen werden. (Siehe Bild 1-4.)
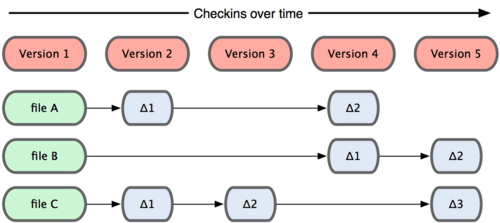
Bild 1-4. Andere Systeme speichern Daten als Änderungen an einzelnen Dateien einer Datenbasis
Git sieht Daten nicht in dieser Weise. Stattdessen betrachtet Git seine Daten eher als eine Reihe von Snapshots eines Mini-Dateisystems. Jedes Mal, wenn Du committest (d.h. den gegenwärtigen Status Deines Projektes als eine Version in Git speicherst), sichert Git den Zustand sämtlicher Dateien in diesem Moment („Snapshot“) und speichert eine Referenz auf diesen Snapshot. Um dies möglichst effizient und schnell tun zu können, kopiert Git unveränderte Dateien nicht, sondern legt lediglich eine Verknüpfung zu der vorherigen Version der Datei an. Git betrachtet Daten also wie in Bild 1-5 dargestellt.
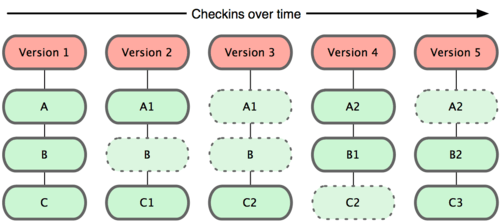
Bild 1-5. Git speichert Daten als eine Historie von Snapshots des Projektes.
Dies ist ein wichtiger Unterschied zwischen Git und praktisch allen anderen Versionskontrollsystemen. In Git wurden daher fast alle Aspekte der Versionskontrolle neu überdacht, die in anderen Systemen mehr oder weniger von ihren jeweiligen Vorgängergeneration übernommen worden waren. Git arbeitet im Großen und Ganzen eher wie ein (mit einigen unglaublich mächtigen Werkezeugen ausgerüstetes) Mini-Dateisystem, als wie ein gängiges Versionskontrollsystem. Auf einige der Vorteile, die es mit sich bringt, Daten in dieser Weise zu betrachten, werden wir in Kapitel 3 eingehen, wenn wir das Git Branching Konzept diskutieren.
Fast jede Operation ist lokal
Die meisten Operationen in Git benötigen nur die lokalen Dateien und Ressourcen auf Deinem Rechner, um zu funktionieren. D.h. im Allgemeinen werden keine Informationen von einem anderen Rechner im Netzwerk benötigt. Wenn Du mit einem CVCS gearbeitet hast, das für die meisten Operationen einen Network Latency Overhead (also Wartezeiten, die das Netzwerk benötigt werden) hat, dann wirst Du den Eindruck haben, dass die Götter der Geschwindigkeit Git mit unaussprechlichen Fähigkeiten ausgestattet haben. Weil man die vollständige Historie lokal auf dem Rechner hat, werden die allermeisten Operationen ohne jede Verzögerung ausgeführt und sind sehr schnell.
Um beispielsweise die Historie des Projektes zu durchsuchen, braucht Git sie nicht von einem externen Server zu holen – es liest sie einfach aus der lokalen Datenbank. Das heißt, Du siehst die vollständige Projekthistorie ohne jede Verzögerung. Wenn Du sehen willst, worin sich die aktuelle Version einer Datei von einer Version von vor einem Monat unterscheidet, dann kann Git diese Versionen lokal nachschlagen und ihre Unterschiede lokal bestimmen. Es braucht dazu keinen externen Server – weder um Dateien dort nachzuschlagen, noch um Unterschiede dort bestimmen zu lassen.
Dies bedeutet natürlich außerdem, dass es fast nichts gibt, was Du nicht tun kannst, bloß weil Du gerade offline bist oder keinen Zugriff auf ein VPN hast. Wenn Du im Flugzeug oder Zug ein wenig arbeiten willst, kannst Du problemlos Deine Arbeit committen und Deine Arbeit erst auf den Server pushen (hochladen), wenn Du wieder mit dem Internet verbunden bist. Wenn Du zu Hause bist aber nicht auf das VPN zugreifen kannst, kannst Du dennoch arbeiten. Perforce z.B. erlaubt Dir dagegen nicht sonderlich viel zu tun, solange Du nicht mit dem Server verbunden bist. Und in Subversion und CVS kannst Du Dateien zwar ändern, die Änderungen aber nicht in der Datenbank sichern (weil die Datenbank offline ist). Das mag auf den ersten Blick nicht nach einem großen Problem aussehen, aber Du wirst überrascht sein, was für einen großen Unterschied das ausmachen kann.
Git stellt Integrität sicher
In Git werden Änderungen in Checksummen umgerechnet, bevor sie gespeichert werden. Anschließend werden sie mit dieser Checksumme referenziert. Das macht es unmöglich, dass sich die Inhalte von Dateien oder Verzeichnissen ändern, ohne dass Git das mitbekommt. Git basiert auf dieser Funktionalität und sie ist ein integraler Teil von Gits Philosophie. Man kann Informationen deshalb z.B. nicht während der Übermittlung verlieren oder unwissentlich beschädigte Dateien verwenden, ohne dass Git in der Lage wäre, dies festzustellen.
Der Mechanismus, den Git verwendet, um diese Checksummen zu erstellen, heißt SHA-1 Hash. Eine solche Checksumme ist eine 40 Zeichen lange Zeichenkette, die aus hexadezimalen Zeichen besteht und diese wird von Git aus den Inhalten einer Datei oder Verzeichnisstruktur kalkuliert. Ein SHA-1 Hash sieht wie folgt aus:
24b9da6552252987aa493b52f8696cd6d3b00373
Dir werden solche Hash Werte überall in Git begegnen, weil es sie so ausgiebig benutzt. Tatsächlich speichert und referenziert Git Informationen über Dateien in der Datenbank nicht nach ihren Dateinamen sondern nach den Hash Werten ihrer Inhalte.
Git verwaltet fast ausschließlich Daten
Fast alle Operationen, die Du in der täglichen Arbeit mit Git verwendest, fügen Daten jeweils nur zur internen Git Datenbank hinzu. Deshalb ist es sehr schwer, das System dazu zu bewegen, irgendetwas zu tun, das nicht wieder rückgängig zu machen ist, oder dazu, Daten in irgendeiner Form zu löschen. In jedem anderen VCS ist es leicht, Änderungen, die man noch nicht gespeichert hat, zu verlieren oder unbrauchbar zu machen. In Git dagegen ist es schwierig, einen einmal gespeicherten Snapshot zu verlieren, insbesondere wenn man regelmäßig in ein anderes Repository pusht.
U.a. deshalb macht es so viel Spaß, mit Git zu arbeiten. Man kann mit Änderungen experimentieren, ohne befürchten zu müssen, irgendetwas zu zerstören oder durcheinander zu bringen. Einen tieferen Einblick in die Art, wie Git Daten speichert und wie man Daten, die scheinbar verloren sind, wieder herstellen kann, wird Kapitel 9 gewähren.
Die drei Zustände
Jetzt aufgepasst. Es folgt die wichtigste Information, die Du Dir merken musst, wenn Du Git kennen lernen willst und Fallstricke vermeiden willst. Git definiert drei Haupt-Zustände, in denen sich eine Datei befinden kann: committed, modified („geändert“) und staged („vorgemerkt“). „Committed“ bedeutet, dass die Daten in der lokalen Datenbank gesichert sind. „Modified“ bedeutet, dass die Datei geändert, diese Änderung aber noch nicht committed wurde. „Staged“ bedeutet, dass Du eine geänderte Datei in ihrem gegenwärtigen Zustand für den nächsten Commit vorgemerkt hast.
Das führt uns zu den drei Hauptbereichen eines Git Projektes: das Git Verzeichnis, das Arbeitsverzeichnis und die Staging Area.
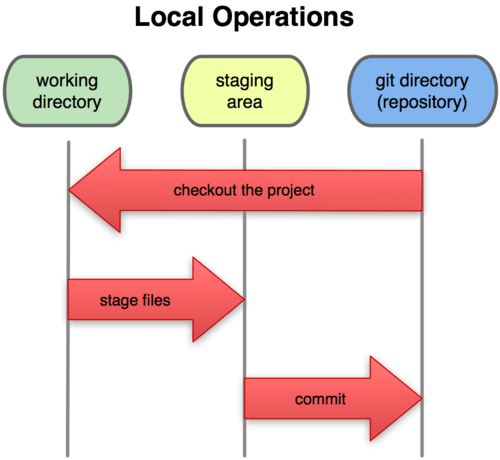
Bild 1-6. Arbeitsverzeichnis, Staging Area (xxx) und Git Verzeichnis
Das Git Verzeichnis ist der Ort, an dem Git Metadaten und die lokale Datenbank für Dein Projekt speichert. Dies ist der wichtigste Teil von Git, und dieser Teil wird kopiert, wenn Du ein Repository von einem anderen Rechner klonst.
Dein Arbeitsverzeichnis ist ein Checkout („Abbild“ xxx) einer spezifischen Version des Projektes. Diese Dateien werden aus der komprimierten Datenbank geholt und auf der Festplatte in einer Form gespeichert, die Du bearbeiten und modifizieren kannst.
Die Staging Area ist einfach eine Datei (normalerweise im Git Verzeichnis), in der vorgemerkt wird, welche Änderungen Dein nächster Commit umfassen soll. Sie wird manchmal auch als „Index“ bezeichnet, aber der Begriff „Staging Area“ ist der gängigere.
Der grundlegend Git Arbeitsprozess sieht in etwa so aus:
- Du bearbeitest Dateien in Deinem Arbeitsverzeichnis.
- Du markierst Dateien für den nächsten Commit, indem Du Snapshots zur Staging Area hinzufügst.
- Du legst den Commit an, wodurch die in der Staging Area vorgemerkten Snapshots dauerhaft im Git Verzeichnis (d.h. der lokalen Datenbank) gespeichert werden.
Wenn eine bestimmte Version einer Datei im Git Verzeichnis liegt, gilt sie als „committed“. Wenn sie geändert und in der Staging Area vorgemerkt ist, gilt sie als „staged“. Und wenn sie geändert, aber noch nicht zur Staging Area hinzugefügt wurde, gilt sie als „modified“. In Kapitel 2 wirst Du mehr über diese Zustände lernen und darüber, wie Du sie sinnvoll einsetzen und wie Du den Zwischenschritt der Staging Area auch einfach überspringen kannst.